到底该不该使用Python?
编译 | 王瑞平
最近,大家总在吐槽Python/ target=_blank class=infotextkey>Python:“虽然它是一种不错的语言,但不适用于专业领域。”
前不久,我在LinkedIn上找到一篇帖子,主要建议初级开发人员应该学习哪种语言,以便获得更好的工作机会,Python凭借出色的表现稳居第一。图片
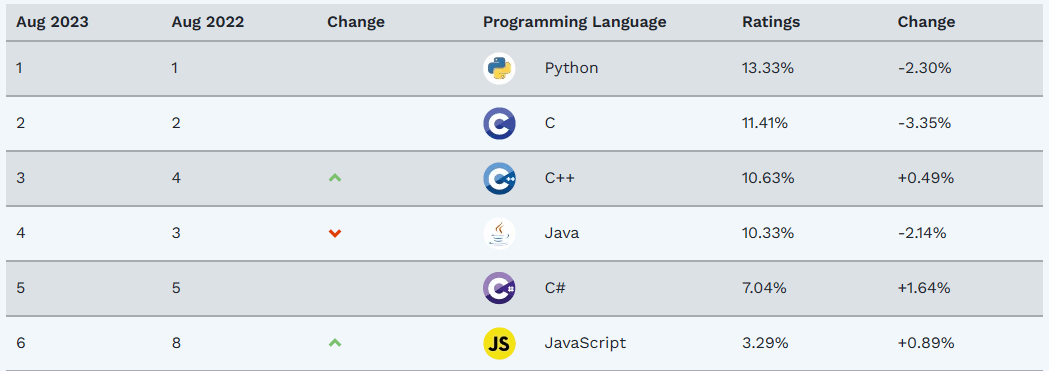
其它证据同样表明:Python确实太受欢迎了!近日,TIOBE编程社区公布了“2023年8月编程语言排行榜”。数据显示:Python依然排名第一,占比13.33%;C语言紧随其后,排行第二,占比11.41%;C++位列第三,占比10.63%,与C语言差距为0.78%。

此外,JAVA和C#分别排在第四和第五位,占比分别为10.33%和7.04%。JavaScript在本月依然保持榜单第六位,占比为3.29%。
虽然Python如此受欢迎,但它能否持续流行依旧是一个重大问题,很多用户普遍认为,如果持续使用将会使行业倒退好几年。
1、局限:Python无法开发大型应用程序
Python对于开发大型应用程序不太友好,在工程化实践中需要特殊的技术支持。
“我曾用Python编写过大型应用程序很多年。由于Python入门非常简单,在编写大型应用程序时就像用乐高积木构建核反应堆一样。”原作者在文章中形象地比喻道。
“但是,现在‘反应堆’已经运行很久,辐射泄漏到处都有,我们需要到处‘贴新砖’让‘反应堆’持续运转。”
实际上,目前唯一能做的就是将“反应堆”封装在混凝土中让它冷却下来,然后再用合适的建筑材料构建出一个新的。
认为“Python无法开发大型应用程序”的网友认为它“不太友好”,在工程化实践中需要特殊技术支持。
图片

也有反对者认为:在大型项目中,与影响更大的其它因素相比,编程语言的语法、语义、范式等几乎无关紧要。团队经验和熟悉度、开发管理、流程、实践、支持工具、文档、语言生态系统、语言成熟度、管理支持等都会对项目结果产生更大的影响。
另外,从技术层面来讲,质疑Python无法开发大型编程语言只能反映提问者对相关开发缺乏了解。这些质疑一是源于Python的动态类型特性,使类型推断变得困难,对代码的静态检查和重构十分不利;二是由于Python代码没有编译过程,因此缺少编译时检查错误机制。
关于动态类型特性质疑,Python从3.3版本起就引入类型声明,因此,只要遵循规范编写代码,类型推断和代码重构就不是问题。
不久前,ChatGPT的问世也证明了Python可以写出高性能、可扩展性强的大型分布式计算平台—Ray。目前,这个平台已汇聚超过1亿的月活跃用户。
“糟糕的应用程序架构是绝大多数应用产生性能瓶颈的原因,而不应该由开发语言来背黑锅。”有些评论者这样认为。
2、速度慢
诚然,Python与其它开发语言相比,在运行速度方面确实落后不少。究其根源,还是由于Python之父认为不需要过多关注Python的速度问题,认为它已经足够快了。
确实,对于99%以上的任务来说,Python的速度够快,快到足以支撑早期google和Dropbox。
自那时起,Python的速度又有了显著提升,但开发者仍要求Python运行得更快。因为,无论人们已经使用Python构建出算力多么惊人的计算平台,它的计算能力在很多场景下依然更慢。
3、功能差
当然,Python是一种灵活的和duck类型的语言:我们键入代码、保存它,然后仅在运行时才能根据输入的数据确定语句始终有效、有时有效还是根本不可能实现。
此外,你在用Python编写程序时,只能部分控制进入该函数的数据,需要严格检查所有输入的数据。
更糟糕的是,Python的duck式输入方式可能会引入“可怕”代码,这会带来麻烦。
4、错误百出
我在用Python编写大型应用程序的这些年里,经历过一些可怕的事情;如果这些应用程序是用理性的、安全的语言编写的,这些事就不会发生。
*在几年前的一个例子中,我设法说服组织用Rust重写系统,效果非常不错!
实际上,我曾多次在社区中发布用Python编写的大型应用程序新版本,结果却立即被错误“吞噬”;这些错误都是由Python代码异常导致的。
*Python的捍卫者会说,这不是语言的缺陷,而是代码审查和测试方法的缺陷。
*他们错了!理论上,测试方法主要是查看每一行代码并检查每个输入和场景,但实际上这并不可能!
好的编程语言的特点之一是:你不必检查和测试内存中每个相关位置的排列;如果必须详尽地检查和测试每个“a=b+c”,程序将可能永远无法应用于实践。
我会经常查看Python函数,并想了解是否有人实际调用了它们以及携带了哪些参数。
我也经常不得不“求助”代码库的全文搜索功能寻找调用位置;不幸的是,即便没有输出任何结果,当我删除相应函数时,程序依然会崩溃;就算程序没有立即崩溃,也无法判断程序是否会在某种情况下崩溃。
5、分叉进程,耗尽内存
用Python的另一个问题是内存。我的笔记本电脑有10个CPU内核,其中,Python应用程序大约占用1.2个。
这该怎么办呢?幸运的是,我可以在Python中使用分叉工作进程的功能处理请求,确保所有核心都能正常使用。
不幸的是,分叉进程的操作很快就耗尽了内存,所以我决定在处理完一定数量的请求后自行终止分叉,然后由linux进行内存管理。虽然这并不是Python本身的问题,但Python使内存管理变得更加糟糕。
分叉工作进程还有另一个影响:Python使用引用计数法击败了写时复制。为控制引用计数,保存只读变量的内存块也被写入,从而耗费了一定的内存。
解决这个问题的有效方法是:让编译器对所有由主进程创建和由worker进程继承的变量使用参考数值,而不必触及到具有该参考数值的引用计数。
这是超级聪明的解决方案,但我认为应该没这个必要。如果你需要破解编译器才能让Python为你所用,那这种语言又有什么用呢?
总之,Python使编写可靠、易于维护和快速的代码变得非常困难。
6、将Python替换成GO
当我对Python忍无可忍之时就会转向Go,它使用起来几乎与Python同样容易、安全,还能快速构建系统并生成高度优化的二进制本机代码文件。
虽然Go也并不是完美的,但是,如果你想可靠和快速地编写代码,并在代码失控时可以调试和重构,Go比Python好很多!
参考资料:
https://www.zhihu.com/question/321166662/answer/2937406779?utm_id=0
https://www.zhihu.com/question/321166662/answer/2937406779