前端不存在了?盲测64%的人更喜欢GPT-4V的设计,杨笛一等团队新作
3 月 9 日央视的一档节目上,百度创始人、董事长兼 CEO 李彦宏指出,以后不会存在「程序员」这种职业了,因为只要会说话,人人都会具备程序员的能力。「未来的编程语言只会剩下两种,一种叫做英文,一种叫做中文。」

自大模型技术突破以来,越来越多的行业拥有了自动化的趋势,这其中进度最快的领域似乎是软件开发本身。
根据你的自然语言指令,ChatGPT 这样的工具可以和你边聊边生成代码,结果逐渐靠谱且速度很快。在最近多模态技术进步以后,甚至截个图让 AI 自行领会意图也能生成你想要的设计:
这种方法是装装样子还是来真的?AI 距离「替代程序员」还有多远?有研究告诉我们:已经很可怕了。
我们离自动化前端工程还有多远?
将视觉设计实现成执行功能的代码是一项颇具挑战性的任务,因为这需要理解视觉元素和它们的布局,然后将它们翻译成结构化的代码。
这个过程需要复杂的技能,也因此让很多普通人无法构建自己的网络应用,即便他们已经有了非常具体的构建或设计思路。不仅如此,由于这个过程需要不同领域的专业知识,因此往往需要具备不同技能的人互相合作,这就会让整个网页构建过程更加复杂,甚至可能导致目标设计与实际实现之间出现偏差。
如果能基于视觉设计有效地自动生成功能性代码,那么势必有望实现前端网页应用开发的大众化,也就是让非专家人士也能轻松快捷地构建应用。
近些年,基于自然语言的代码生成领域发展迅速,但少有人研究基于用户界面(UI)设计来自动生成代码实现,原因包括用户界面存在多样化的视觉和文本信号、结果代码的搜索空间巨大等。
最近,多模态 LLM 进入了新的发展时代,大规模预训练模型可以针对多种基于视觉的任务通过处理视觉和文本输入来生成文本输出,其中代表性的模型包括 Flamingo、GPT-4V 和 Gemini。
这样的进展为上述任务带来了全新的解决方案范式:取一张用户网站设计的截图并将其提供给系统,就能得到完整的代码实现,然后这些代码又可以被渲染成用户想要的网页。整个过程是完全端到端式的。
近日,斯坦福大学、佐治亚理工学院等机构的一个联合团队评估了当前的多模态模型在这一任务上的表现。

- 论文标题:Design2Code: How Far Are We From Automating Front-End Engineering?
- 论文地址:https://arxiv.org/pdf/2403.03163.pdf
- 项目主页:https://salt-nlp.Github.io/Design2Code/
他们将这个任务称为 Design2Code。通过一系列的基准评测,我们可以从这些结果中了解自动化前端工程已经发展到哪一步了。
为了实现系统化和严格的基准评测,该团队为 Design2Code 任务构建了首个真实世界基准。表 1 给出了一些示例。

为了最好地反映真实用例,他们使用了真实世界的网页,而非用生成方法得到合成网页。他们收集了 C4 验证集中的网页,并对所有样本进行了仔细的人工调整,最终得到了 484 个高质量、高难度和多样化的网页。它们可代表不同复杂度的多种真实世界用例。他们执行了定性和定量分析,证明这个基准数据集覆盖了广泛的 html 标签用法、领域和复杂度。
此外,为了促进高效的评估和模型开发,该团队还为这个任务开发了一些评估指标 —— 可自动比较生成网页的截图与给定的截图输入。这些新指标考虑的维度很全面,包括边界框匹配、文本内容、位置和所有已匹配视觉元素的颜色。
然后,该团队调查了 GPT-4V 和 Gemini 等当前的多模态 LLM 在这一任务上的表现。为了让这些模型能展现出自己的最优能力,该团队使用了一些不同的 prompt 设计方案,包括文本增强式 prompt 设计和自我修正式 prompt 设计。其中文本增强式 prompt 设计是为视觉输入提供文本元素作为补充,从而可以降低光学字符识别(OCR)的任务负载;自我修正式 prompt 设计则是让模型比较之前的生成结果与输入的网页截图,让其自我改进。
研究者发现,在 GPT-4V 和 Gemini Pro 上,相比于使用直接 prompt 设计法,文本增强式 prompt 设计都能带来提升,但自我修正式方法只能为 GPT-4V 带来积极影响。
尽管这些商用模型的表现是当前最佳的,但它们都是缺乏透明度的黑箱。因此,该团队还为这一任务贡献了一个开源的 18B 参数的已微调模型:Design2Code-18B。
具体来说,该模型基于当前最佳的开源模型 CogAgent 构建,并使用合成的 Design2Code 数据进行了微调。令人惊讶的是,在新提出的基准上,尽管合成的训练数据与真实的测试数据之间存在差异,但这个「小型」开源模型的表现依然颇具竞争力 —— 足以媲美 Gemini Pro Vision。这说明专用型的「小型」开放模型是有发展潜力的,并且模型也可以从合成数据中学习获取技能。
Design2Code 基准
为了得到基准数据,该团队首先收集了 C4 验证集中的所有网站链接。然后他们将所有 css 代码嵌入到了 HTML 文件中,从而让每个网页都只有一个代码实现文件。这样得到了共计 12.79 万个网页。然后他们又执行了进一步的过滤和处理,包括自动调整和人工调节。最终他们得到了包含 484 个测试样本的基准。下表 1 比较了新提出的 Design2Code 与 Huggingface 的 WebSight 数据集。

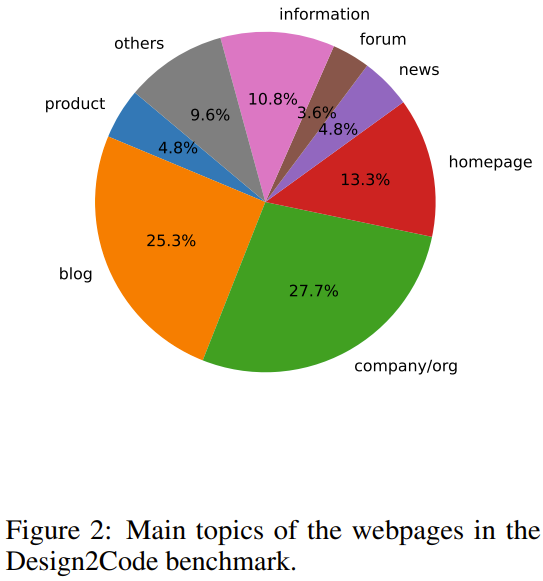
图 2 总结了 Design2Code 的主要主题。
至于评估指标,该团队提出了一种高层级的视觉相似度指标,即比较参考网页和生成网页的相似度。另外他们还使用了一组低层级的元素匹配指标,包括块元素、位置、文本和颜色等的匹配程度。
结果自动评估和人类评估
自动评估
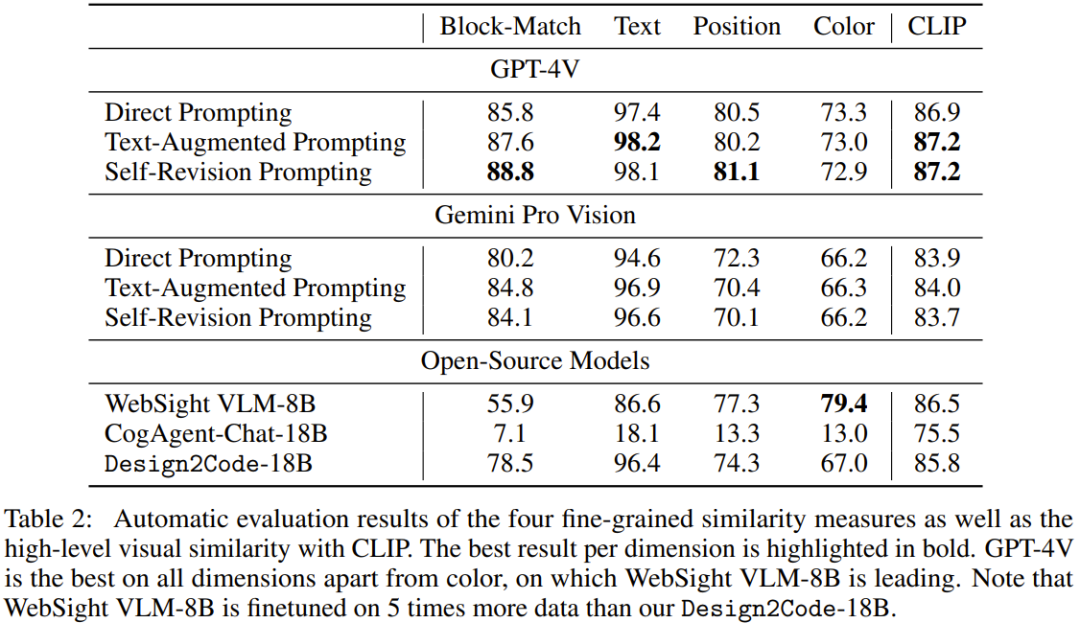
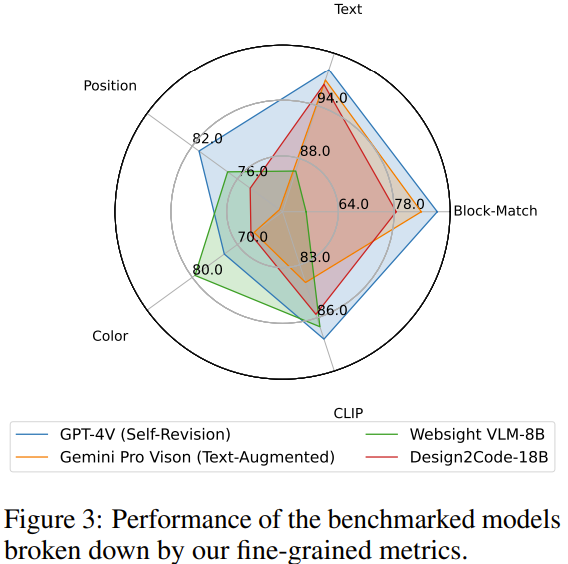
表 2 和图 3 给出了自动评估的结果。请注意,这里的比较并不是公平的,因为不同模型有不同的模型大小和训练数据。
可以观察到:
- GPT-4V 在颜色之外的所有维度上都表现最好,而在颜色维度上领先的是 WebSight VLM-8B。
- 对于 GPT-4V 和 Gemini Pro Vision,文本增强式 prompt 设计均可以成功提升块元素匹配分数和文本相似度分数,这说明提供提取出的文本元素是有用的。
- 对 GPT-4V 而言,自我修正式 prompt 设计可以为块元素匹配和位置相似度带来少量提升,但对 Gemini Pro Vision 来说却并无提升。可能的原因是:在没有外部反馈的前提下,LLM 执行内部自我校正的能力有限。
- 通过比较 Design2Code-18B 和基础版本的 CogAgent-18B,可以看出微调能为所有维度带来显著提升。
- 相比于 WebSight VLM-8B,该团队微调得到的 Design2Code-18B 在块元素匹配和文本相似度指标上表现更好,但在位置相似度和颜色相似度指标上表现更差。
该团队表示,前两个观察可以归因于更强更大的基础模型,而后两个则可归功于更大量的微调数据。
人类评估
该团队也进行了人类评估。下面是主要的评估协议和结果。每一个问题都由 5 位人类标注者给出评估意见,最终结果遵从多数意见。
成对模型比较:也就是让标注者给一对生成的网页排名(一个来自基线方法,另一个来自受测方法),以决定哪一个与参考网页更相似。这里的基线是对 Gemini Pro Vision 采用直接 prompt 设计,收集的数据是其它七种方法与这种基线方法的胜 / 平 / 负的比例。
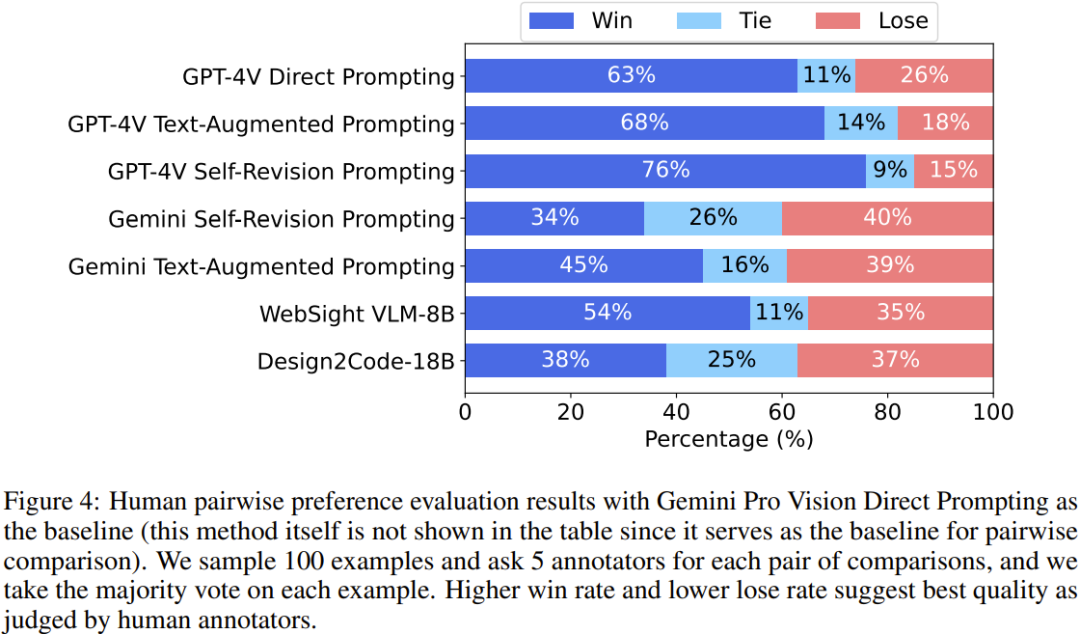
结果见图 4,可以看出:
- GPT-4V 显著优于其它基线,而且文本增强式 prompt 设计和自我修正式 prompt 设计能在直接 prompt 设计的基础上进一步提升。
- 文本增强式 prompt 设计可以少量提升 Gemini,但进一步增加自我修正方法却没有帮助。
- WebSight VLM-8B 优于 Gemini 直接 prompt 设计方法(54% 的胜率和 35% 的败率),这说明在大量数据上进行微调可以在特定领域比肩商用模型。
- 新模型 Design2Code-18B 的表现与 Gemini Pro Vision 直接 prompt 设计方法相当(38% 的胜率和 37% 的败率)。
直接评估:尽管有这些比较,但读者可能还是会问:「我们离自动化前端工程还有多远?」
为了得到一个更直观的答案,该团队进一步让人类标注者比较了参考网页与最佳的 AI 生成网页(使用了 GPT-4V 自我修正式 prompt 设计)。他们从两个方面进行了直接评估:
1.AI 生成的网页能否替代原始网页?
人类标注者认为:AI 生成的网页中,49% 可与参考网页互换。
2. 参考网页和 AI 生成的网页哪个更好?
结果有点出人意料:在 64% 的案例中,人类标注者更偏爱 GPT-4V 生成的网页,也就是说他们认为 AI 生成的网页比原始参考图像的设计更好!
自动评估 vs 人类评估
该团队也研究了自动指标与人类配对偏好之间的相关性。结果发现,人类通常更关注高层级的视觉效果和布局,而不是细节内容,这说明人类的思考方式是自上而下的。
不过,针对论文给出的结果,有人提出了不同意见,认为前端的工作流程远比表面看上去复杂,因此真正实现「自动化前端工程」还需要一段时间。

对于这个问题,你怎么看?