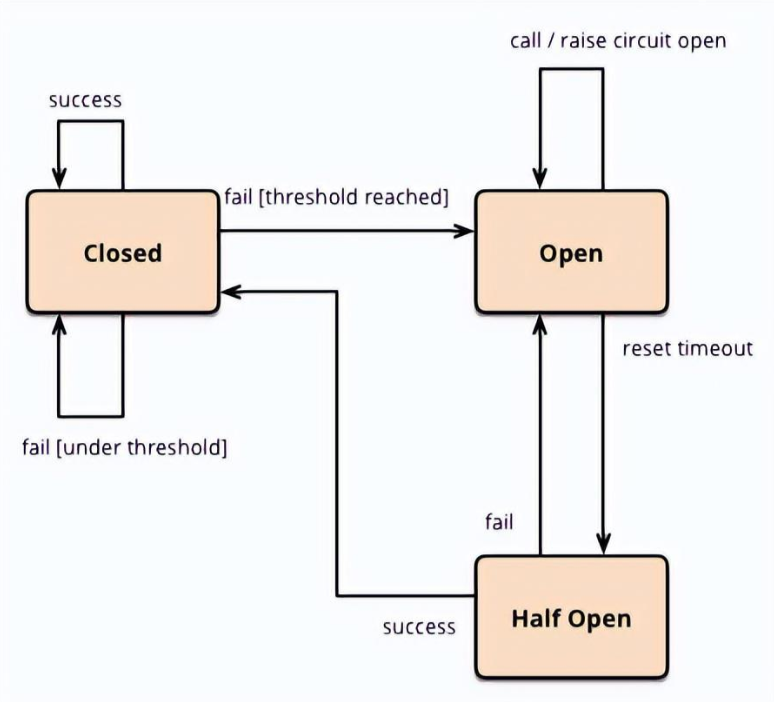
分布式缓存是一种将数据存储在多个节点上的缓存解决方案,旨在提高系统的性能、可扩展性和容错性。下面是一些分布式缓存的重要知识点:
缓存的作用:缓存是将计算结果或数据存储在快速访问的介质中,以减少对慢速或昂贵资源的访问。通过缓存常用的数据,系统可以加快响应时间并降低对后端数据存储系统的负载。
分布式缓存架构:分布式缓存通常由多个缓存节点构成,这些节点可以是物理服务器或虚拟机。数据在这些节点之间进行分片存储,以实现水平扩展和负载均衡。常见的分布式缓存架构包括主从复制、分片和一致性哈希等。
缓存命中和缓存失效:当应用程序请求数据时,分布式缓存首先检查是否存在于缓存中,如果存在且有效,则命中缓存,可以立即返回结果。如果数据不存在或已失效,则需要从后端数据存储系统中获取数据,并将其存储到缓存中以供后续访问。
缓存一致性:在分布式环境中,多个缓存节点之间需要保持数据的一致性,即相同的数据在不同节点上保持一致。为了实现一致性,可以使用一致性哈希算法或一致性协议,以确保数据在节点之间均匀分布。
缓存失效策略:缓存中的数据可能会过期或失效,需要一定的策略来处理。常见的缓存失效策略包括基于时间的失效、基于LRU(最近最少使用)的失效、基于写回的失效等。
容错性和高可用性:分布式缓存需要具备容错性,即在部分节点故障或网络分区的情况下,仍能够正常工作。为了实现高可用性,可以使用主从复制、数据备份和故障转移等机制。
缓存穿透和缓存击穿:缓存穿透是指当请求的数据在缓存和后端存储中都不存在时,每次请求都会直接访问后端存储系统,导致性能问题。缓存击穿是指某个热点数据失效或过期时,大量的请求同时涌入,导致缓存和后端存储系统压力过大。为了应对这些问题,可以采取预加载、热点数据预热、使用互斥锁等措施。
常见的分布式缓存系统包括redis、Memcached、Apache Ignite等。它们提供了丰富的功能和API,支持数据的存储、读取、更新和删除操作,并提供了各种高级功能如事务支持、发布/订阅机制、数据过期等。
数据一致性风险:由于分布式缓存中的数据被分片存储在多个节点上,可能导致数据的一致性问题。当节点发生故障、网络分区或数据同步延迟时,不同节点之间的数据可能会出现不一致的情况,从而影响系统的正确性和可靠性。
缓存雪崩风险:缓存雪崩是指在缓存中大量数据同时失效或过期,导致大量请求直接落到后端存储系统上,从而造成后端系统的压力骤增,甚至导致系统崩溃。这通常是由于缓存中的数据设置了相同的过期时间或缓存层的故障引起的。
缓存穿透风险:缓存穿透是指恶意请求或者非常罕见的请求导致缓存和后端存储系统中都不存在所请求的数据,从而导致每次请求都需要直接访问后端存储系统,影响系统性能。攻击者可能通过不断发送不存在的数据请求来消耗系统资源。
热点数据问题:在分布式缓存中,某些热点数据可能会导致不均匀的负载分布。当大量请求集中在某个热点数据上时,可能导致该节点的性能下降,并成为系统的瓶颈。
缓存过期管理:合理设置缓存数据的过期时间是一个挑战。过长的过期时间可能导致数据的更新延迟,过短的过期时间则增加了缓存失效和后端存储系统的负载。
容量规划和管理:分布式缓存需要合理规划和管理容量,以适应系统的负载和数据访问模式。如果缓存容量不足,可能导致数据被频繁驱逐,影响性能。如果缓存容量过大,可能造成资源浪费。
依赖性和故障恢复:分布式缓存作为系统的关键组件,可能会对系统的稳定性和可靠性产生重要影响。如果分布式缓存发生故障或出现网络分区,可能导致整个系统的故障。因此,需要考虑缓存的依赖性,并制定故障恢复策略。
为了减少这些风险,可以采取一些措施,如合理的缓存策略、多级缓存、数据备份和冗余、缓存监控和报警、缓存预热、故障转移和容错机制等。同时,根据具体场景和业务需求,结合缓存的特性和限制,进行合理的系统设计和架构。
分布式缓存的数据一致性风险是指在分布式环境中,由于多个缓存节点之间的异步通信或节点故障等原因,可能导致数据的一致性问题。以下是一些常见的数据一致性风险:
更新冲突:当多个节点同时更新相同的缓存数据时,可能会导致数据的不一致性。例如,节点 A 和节点 B 同时更新了某个缓存数据,但由于异步通信的延迟或竞争条件,导致最终数据在不同节点上的值不同。
读写延迟:当一个节点更新了缓存数据后,其他节点可能需要一定的时间才能收到更新通知并更新自己的缓存。在这段延迟期间,读请求可能会访问到旧的缓存数据,导致数据的不一致性。
脏数据问题:当一个节点更新了缓存数据,但由于某种原因(例如节点故障或网络分区),该更新没有成功同步到其他节点。在这种情况下,其他节点可能仍然存储着旧的缓存数据,导致数据的不一致性。
缓存失效问题:在某些情况下,缓存中的数据可能会在规定的过期时间之前失效。例如,当多个节点同时失效或重启时,所有缓存数据都会同时失效,导致数据的不一致性。
为了降低数据一致性风险,可以采取以下措施:
示例代码中,Cache是一个代表缓存的类型,它可以是一个抽象类或接口,也可以是一个具体的实现类。这取决于所使用的缓存库或框架。
通常情况下,缓存库或框架会提供一个缓存接口或抽象类,用于定义缓存操作的基本方法和功能。具体的缓存实现类会实现这个接口或继承这个抽象类,并提供具体的缓存功能和行为。
一个简化的缓存接口的定义:
public interface Cache {
void put(String key, Object value);
Object get(String key);
void remove(String key);
// ...
}
Cache cache = // 获取缓存实例
cache.setConsistencyLevel(ConsistencyLevel.STRONG); // 设置强一致性级别
// 或者
cache.setConsistencyLevel(ConsistencyLevel.EVENTUAL); // 设置最终一致
Cache cache = // 获取缓存实例
cache.setExpirationTime("key", expirationTime); // 设置缓存失效时间
Cache cache = // 获取缓存实例
Lock lock = cache.getLock("key"); // 获取分布式锁
try {
lock.lock(); // 获取锁
// 更新缓存数据
cache.put("key", data);
} finally {
lock.unlock(); // 释放锁
}
Cache cache = // 获取缓存实例
CacheEventListener listener = // 缓存事件监听器
// 注册监听器
cache.registerCacheEventListener(listener);
// 在缓存节点上进行数据更新
cache.put("key", data);
// 监听器接收到缓存更新事件后,将事件广播给其他缓存节点,实现数据同步
Cache cache = // 获取缓存实例
// 监控缓存节点的状态和健康状况
CacheHealthMonitor monitor = cache.getHealthMonitor();
monitor.startMonitoring();
// 在故障恢复后,进行数据同步和修复
if (monitor.isNodeRecovered(node)) {
// 执行数据同步和修复操作
cache.syncData(node);
}
分布式缓存主要是由于写和更新操作造成不一致性,在使用时要全面考虑该种情况,设计比较完善的同步策略。