SpeechGen:用Prompt解锁语音语言模型生成能力
本文分享了一个创新的统一框架,SpeechGen,旨在激发语音语言模型进行生成任务的潜力。提出该框架的团队是来自台湾大学李宏毅老师团队,作者均是台湾大学在读博士,分别是语音实验室成员吴海斌、KAI-Wei Chang和Yuan-Kuei Wu。
论文链接:https://arxiv.org/pdf/2306.02207.pdf
作者 | 台湾大学语音实验室
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)
引言与动机
大型语言模型 (LLMs)在人工智能生成内容(AIGC)方面引起了相当大的关注,特别是随着 ChatGPT 的出现。
然而,如何用大型语言模型处理连续语音仍然是一个未解决的挑战,这一挑战阻碍了大型语言模型在语音生成方面的应用。
因为语音信号包含丰富的信息,包括说话者和情感,超越了纯文本数据,基于语音的语言模型 (Speech Language Model, Speech LM)不断涌现。
虽然与基于文本的语言模型相比,语音语言模型仍处于早期阶段,但由于语音数据中蕴含着比文本更丰富的信息,它们具备巨大的潜力,令人充满期待。
研究人员们正积极探索提示 (prompt) 范式的潜力,以发挥预训练语言模型的能力。这种提示通过微调少量参数,引导预训练语言模型做特定的下游任务。这种技术因其高效和有效而在 NLP领域备受青睐。在语音处理领域,SpeechPrompt 展示出了在参数效率方面的显著改进,并在各种语音分类任务中取得了竞争性的表现。
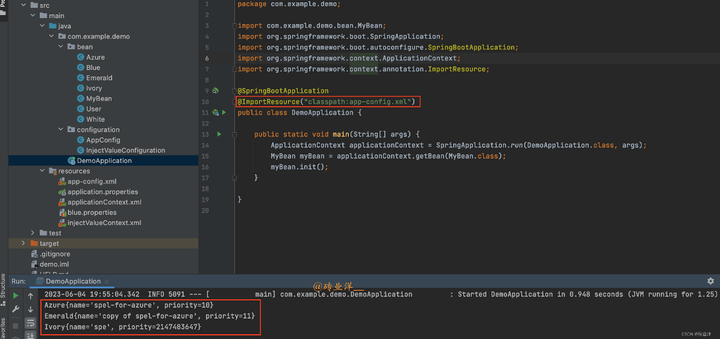
然而,提示能否帮助语音语言模型做生成任务仍是未解之谜。在本文中,我们提出一个创新的统一框架,SpeechGen,旨在激发语音语言模型进行生成任务的潜力。如下图所示,将一段语音、一个特定的提示(prompt)喂给 speech LM 作为输入,speech LM就能做特定的任务。比如将红色的 prompt 当作输入,speech LM 就能做 speech translation 的任务。
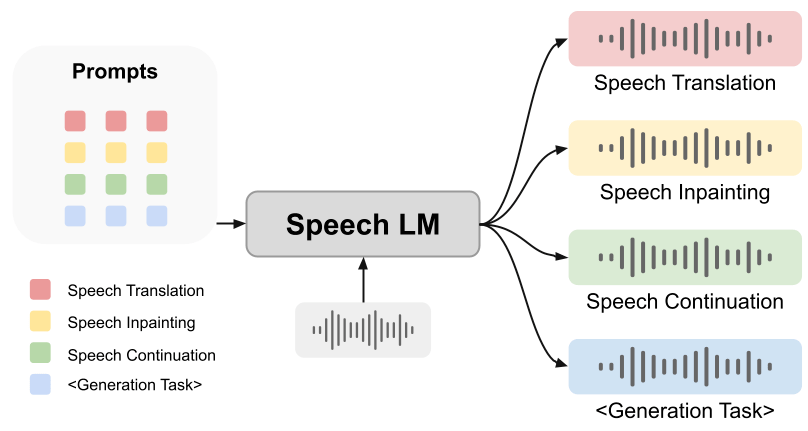
我们提出的框架有以下优点:
-
无文本 (Textless):我们的框架以及其所依赖的语音语言模型独立于文字数据,拥有无可估量的价值。毕竟,获取标记文本与语音配对的过程耗时繁琐,而且在某些语言中甚至无法找到合适的文本。无需文字的特性使得我们的强大语音生成能力得以覆盖各种语言需求,让全人类受益匪浅。
-
多功能性 (Versatility):我们开发的框架通用性极高,能应用于各种各样的语音生成任务。文章中的实验使用语音翻译、语音修复、语音连续当作例子。
-
简易性 (Easy to follow):我们提出的框架为各类语音生成任务提供了通用解决方案,让设计下游模型和损失函数变得轻而易举。
-
可迁移性 (Transferability):我们的框架不仅容易适应未来更先进的语音语言模型,还蕴藏着巨大的潜力,让效率和效果得到进一步提升。尤其令人振奋的是,随着先进语音语言模型即将问世,我们的框架将迎来更为强大的发展。
-
经济性 (Affordability):我们的框架经过精心的设计,只需训练少量参数,而不是整个庞大的语言模型。这极大地减轻了计算负担,并允许在GTX 2080 GPU上执行训练过程。大学的实验室也能负担得起这样的运算开销。
SpeechGen

我们的研究方法在于构建一个全新的框架 SpeechGen,该框架主要用于利用语音语言模型 (Speech Language Model, Speech LM)进行各种下游语音生成任务的微调。在训练过程中,Speech LMs的参数保持不变,我们的方法侧重于学习任务特定的提示(Prompt)向量。Speech LMs通过同时对提示向量和输入单元进行条件设置,有效地生成特定语音生成任务所需的输出。然后,这些离散单元输出被输入到基于单元的语音合成器中,生成对应的波形。
我们的 SpeechGen 框架由三个元素组成:语音编码器、Speech LM 和语音解码器(Speech Decoder)。首先,语音编码器将波形作为输入,并将其转换为由有限词汇表导出的单位序列。为了缩短序列长度,会移除重复的连续单位以生成压缩的单位序列。然后,Speech LM 作为单位序列的语言模型,通过预测前一单位和单位序列的后续单位来优化可能性。我们对 Speech LM 进行提示调整,以引导其根据任务生成适当的单位。最后,Speech LM生成的标记由语音解码器处理,将其转换回波形。在我们的提示调整策略中,提示向量会在输入序列的开始处插入,这将引导 Speech LMs 在生成过程中的方向。具体插入的提示数量,则取决于 Speech LMs 的架构。在序列到序列的模型中,编码器输入和解码器输入都会加入提示,但在只有编码器或只有解码器的架构中,只会在输入序列前面添加一个提示。
在序列到序列的 Speech LMs(如mBART)中,我们采用了自我监督学习模型(如HuBERT)来处理输入和目标语音。这样做可以为输入生成离散单元,并为目标生成对应的离散单元。我们在编码器和解码器输入的前面都添加了提示向量,以构造输入序列。此外,我们还通过替换注意力机制中的关键值对,以进一步增强提示的指导能力。
在模型训练中,我们以交叉熵损失作为所有生成任务的目标函数,通过比较模型的预测结果和目标离散单元标签来计算损失。在这个过程中,提示向量是模型中唯一需要训练的参数,而Speech LMs的参数在训练过程中保持不变,这确保了模型行为的一致性。我们通过插入提示向量,引导 Speech LMs 从输入中提取任务特定信息,并提高产生符合特定语音生成任务的输出的可能性。这种方法允许我们微调并调整 Speech LMs 的行为,而无需修改其基础参数。
总的来说,我们的研究方法基于一种全新的框架 SpeechGen,通过训练提示向量,引导模型的生成过程,并使其能有效地产生符合特定语音生成任务的输出。
实验
我们的框架可以用于任意的 speech LM 及各类生成任务,具有很好的潜力。在我们的实验中,由于 VALL-E 和 AudioLM 不是开源的,我们选择使用 Unit mBART 作为 speech LM 进行案例研究。我们用语音翻译 (speech translation)、语音修复 (speech inpainting)、语音连续 (speech continuation) 当作例子,来展示我们的框架的能力。这三个任务的示意图如下图所示。所有的任务都是语音输入,语音输出,无需文本的帮助。
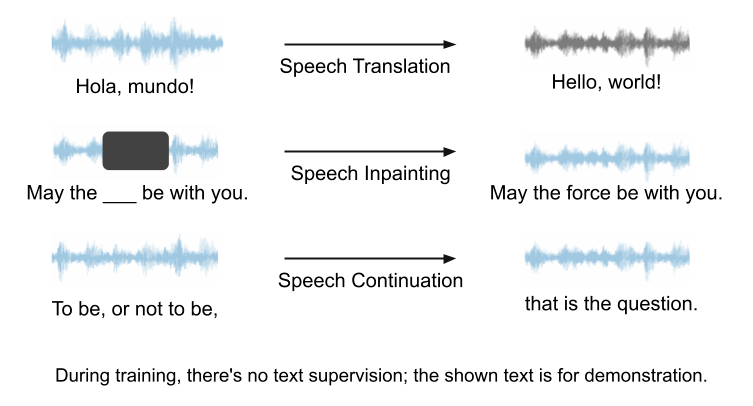
语音翻译
我们在训练语音翻译 (speech translation) 时,用的时西班牙文转英文的任务。我们给模型输入西班牙语的语音,希望模型产生英文的语音,整个过程无需文本帮助。以下是几个语音翻译的例子,我们会展示正确答案 (ground truth) 与模型的预测 (model prediction)。这些演示示例表明模型的预测捕捉到了正确答案的核心含义。

语音修补
在我们进行语音修补 (speech inpainting) 的实验中,我们特别选取超过 2.5 秒的音频片段作为后续处理的目标语音,并通过随机选择过程挑选出一段时长介于 0.8 至 1.2 秒的语音片段。然后我们对选出的片段进行遮蔽,模拟语音修补任务中缺失或受损的部分。我们使用词错误率 (WER) 和字符错误率 (CER) 作为评估受损片段修复程度的指标。
对 SpeechGen 生成的输出与受损语音进行比较分析,我们的模型可以显著重建口语词汇,将 WER 从 41.68% 降低到 28.61%,将 CER 从 25.10% 降低到 10.75%,如下表所示。这意味着我们提出的方法能够显著提高语音重建的能力,最终促进语音输出的准确性和可理解性。
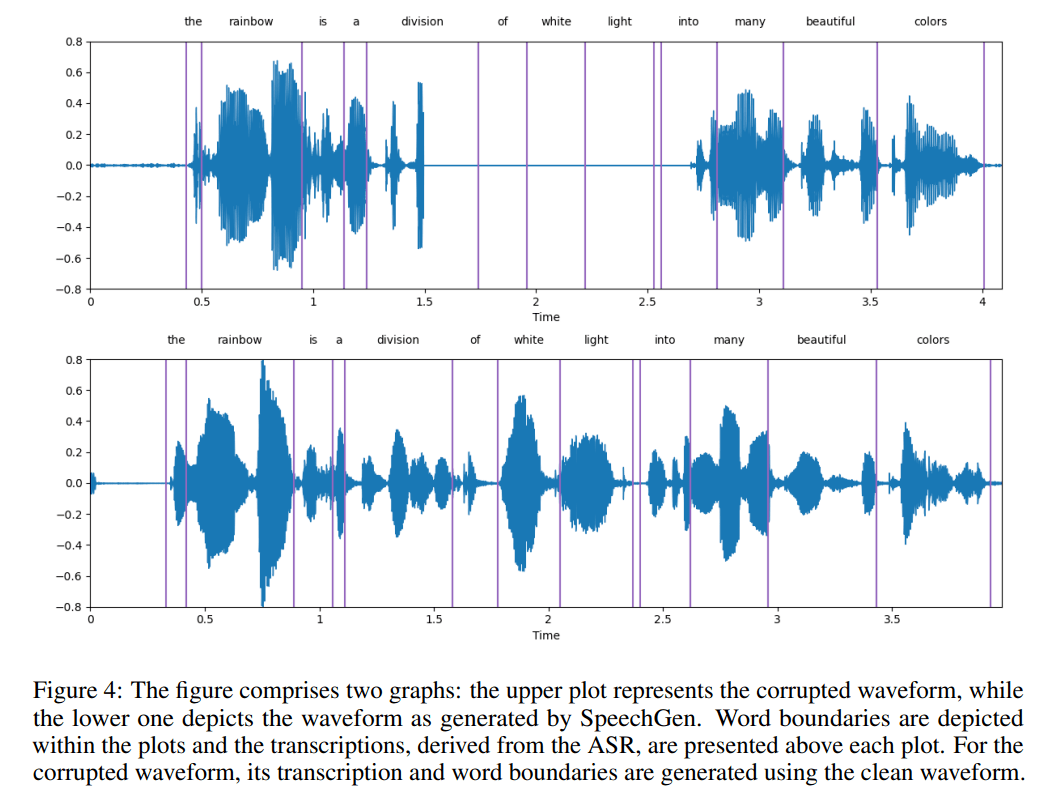
下图是一个展示样例,上面的子图是受损的语音,下面的子图是 SpeechGen 产生的语音,可以看到,SpeechGen 很好地修复了受损的语音。
语音连续
我们将通过 LJSpeech 展示语音连续任务的实际应用。在训练提示(prompt)期间,我们的策略是让模型只看到片段的种子片段(seed segment),这个 seed segment 占据了语音总长度的一个比例,我们将其称为条件比率(condition ratio, r),并让模型继续产生后续的语音。
以下,我们为您展示一些实例。黑色的文字代表种子片段(seed segment),而红色的文字则是 SpeechGen 生成的句子(这里的文字首先经过语音识别得到的结果。在训练和推理过程中,模型完全进行的是语音到语音的任务,且完全不接收任何文字信息)。不同的条件比率使 SpeechGen 能够生成不同长度的语句以实现连贯性,并完成一句完整的话。从质量角度看,可以观察到生成的句子与种子片段在语法上基本一致,并且语义相关。虽然,生成的语音仍然无法完美地传达一个完整的意思。我们预期这个问题将在未来更强大的语音模型中得到解决。

不足与未来方向
语音语言模型和语音生成正处于蓬勃发展的阶段,而我们的框架则提供了一种巧妙地利用强大语言模型进行语音生成的可能性。然而,这个框架仍有一些尚待完善之处,也有许多值得我们深入研究的问题。
-
与基于文本的语言模型相比,语音语言模型目前还处于发展的初级阶段。虽然我们提出的提示框架能激发语音语言模型做语音生成任务,但并不能达到卓越的性能。不过,随着语音语言模型的不断进步,比如从 GSLM 到 Unit mBART 的大转身,提示的表现有了明显的提升。特别是以前对 GSLM 而言具有挑战性的任务,现在在 Unit mBART 下表现出更好的性能。我们预计未来会出现更多先进的语音语言模型崭露头角。
-
超越内容信息:当前的语音语言模型并不能完全捕捉到说话者和情感信息,这给当前的语音提示框架在有效处理这些信息方面带来了挑战。为了克服这个限制,我们有一个方法:引入即插即用的模块,专门为框架注入说话者和情感信息。展望未来,我们预计未来的语音语言模型将整合和利用这些内容之外的信息,以提高性能并更好地处理语音生成任务中的说话者和情感相关方面。
-
提示生成的可能性:对于提示生成,我们有着灵活多变的选择,可以集成各种类型的指示,包括文本和图像指示。想象一下,我们可以训练一个神经网络,让它用图像或文本作为输入,而不是像本文中那样使用训练好的 embedding 当作提示。这个训练好的网络将成为我们的提示生成器,为框架增添了更多的多样性。这样的方式会让提示生成变得更加有趣和丰富多彩。
结论
在本文中,我们探索了使用提示来解锁语音语言模型在各种生成任务中的性能。我们提出了一个名为 SpeechGen 的统一框架,该框架仅有约 10M 的可训练参数。我们所提出的框架具有几个令人满意的特性,包括无需文本、多功能性、高效性、可转移性和可负担性。为了展示我们框架的能力,我们以 Unit mBART 为案例研究,并在三个不同的语音生成任务上进行实验:语音翻译、语音修复和语音延续。
当这篇论文提交到 arXiv时,google 提出了一种更先进的语音语言模型——SPECTRON,它为我们展示了语音语言模型在建模说话人和情感等信息的可能性。这无疑是一个令人兴奋的消息,随着先进语音语言模型的不断提出,我们的统一框架具有巨大的潜力。
▶ 大脑将会代替开发者的键盘,人类和 AI 能够“双向奔赴”吗? | 近匠
▶ 王小川新公司开源 70 亿参数量的中英文预训练大模型,可商用;谷歌要求员工慎用 AI,即便是自己家的 Bard|极客头条
▶ 成立 4 个星期获得 1.13 亿美元种子轮融资,3 个 30岁+小伙草创「开源版 OpenAI」!