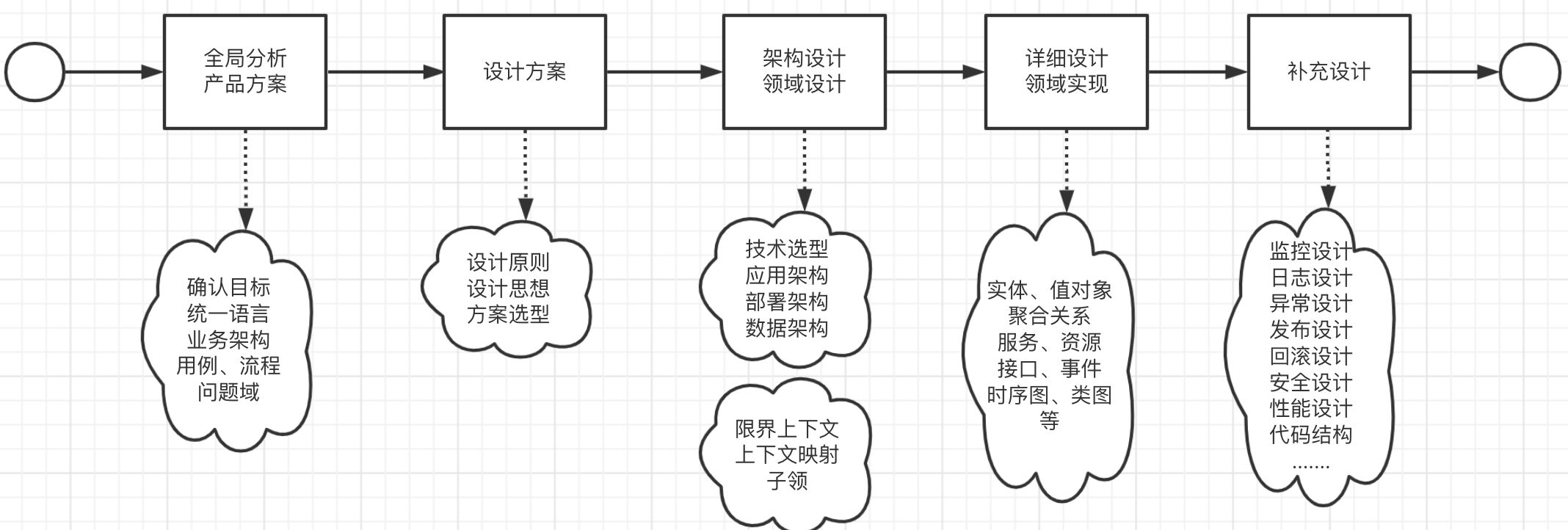
ChatGPT中的Transformer架构

Transformer是一种基于自注意力机制(Self-Attention)的序列到序列(Seq2Seq)模型架构,由google在2017年提出。与传统的循环神经网络(RNN)模型相比,Transformer在处理长序列时具有更好的捕捉依赖关系和并行计算能力,因此在机器翻译、文本生成等自然语言处理任务中表现出色。
Transformer模型主要由两个部分组成:编码器和解码器。编码器的作用是将输入序列转化为一系列高层次的特征表示,解码器则根据这些特征表示来生成目标序列。
编码器
编码器由多个相同的层组成,每一层都由两个子层组成:自注意力机制层和全连接前馈网络层。自注意力机制层主要用于学习输入序列中各个位置之间的关系,全连接前馈网络层则用于将每个位置的特征表示映射到一个更高维度的空间中。在自注意力机制层中,我们会根据输入序列中每个位置的特征来计算它与其他位置的相似度,然后对相似度进行归一化处理,得到一个加权的向量表示,这个过程就叫做注意力机制。
解码器
解码器也由多个相同的层组成,每一层也包含两个子层:自注意力机制层和编码器-解码器注意力机制层。自注意力机制层和编码器中的自注意力机制层是类似的,用于学习解码器输入序列中各个位置之间的关系;编码器-解码器注意力机制层则用于将编码器的输出特征和解码器的输入序列进行对齐,从而将编码器的信息引入到解码器中。
在Transformer模型中,输入的序列首先通过词嵌入(word Embedding)层得到词向量表示,然后再通过位置编码(Positional Encoding)层将序列中的位置信息编码到词向量中。编码器和解码器都包含多个Transformer模块,每个Transformer模块中包含了一个自注意力机制和一个前馈神经网络(Feed-Forward.NETwork)。自注意力机制用于学习输入序列中的依赖关系,前馈神经网络则用于对注意力机制的输出进行处理。在解码器中,还增加了一个注意力机制,用于对编码器输出进行加权求和,从而得到最终的输出序列。

Transformer模型架构的发展主要集中在以下几个方面:
Transformer-XL
Transformer-XL是在原始Transformer模型的基础上提出的改进型模型。传统的Transformer模型只能处理有限长度的序列,但在实际应用中,有些任务需要处理更长的序列,如文档或长篇小说等。为了解决这个问题,Transformer-XL采用了一种新的架构,称为“相对位置编码(Relative Positional Encoding)”,可以处理更长的序列。
BERT
BERT(Bidirectional Encoder Representations from Transformers)是由Google于2018年提出的预训练模型,主要用于自然语言处理任务。BERT模型使用了Transformer模型的编码器部分,通过预训练学习得到高质量的语言表示,然后可以通过微调来适应各种下游任务。BERT模型的出现,推动了自然语言处理领域的发展。
GPT
GPT(Generative Pre-trAIned Transformer)是由OpenAI于2018年提出的预训练模型,也基于Transformer架构。GPT主要用于自然语言生成任务,如文本生成、机器翻译等。GPT模型使用了Transformer的解码器部分,并通过预训练学习得到高质量的语言表示,从而实现了非监督式的语言生成。
XLNet
XLNet是由CMU和谷歌等机构共同开发的预训练模型,采用了Transformer-XL的相对位置编码,并且引入了一种新的预训练方法,称为“可扩展性的自回归性(Permutation Language Modeling)”。相比于BERT模型,XLNet模型在自然语言处理任务上取得了更好的性能。
Transformer模型作为一种基于自注意力机制的模型架构,已经成为处理序列到序列任务的主流模型之一,并且在自然语言处理、语音识别、计算机视觉等领域都得到了广泛的应用。