5分钟熟悉“系统架构设计”(架构演进)
【写在最前】
我们在平时的编程学习中,经常会接触到“ 系统架构设计 ”这个概念;
但是很多小白并不能准确理解这个概念,以及常用系统的架构演进过程,甚至是在查阅了很多资料之后仍然是云山雾罩。
通过本文知识,让我们花5分钟时间彻底搞懂它,相信聪明的你,看完一定会有收获!

【正文开始】
什么是架构设计模式?
我想这个问题,如果有5个人回答,估计能得出6个答案,因为第6个就是大家互相讨论(妥协)的结果(^_^)。
在我看来,设计模式就是设计经验,只有具备了足够多的经验,才能够根据业务自身的具体情况,组合出最适合当前业务的架构设计,从而控制投入成本,提高工作效率。
笔者在IT行业深耕十余年,经历过的架构设计(演进)可以说数以百计,今天把一些架构设计模式的一些经验分享给大家,以飨读者。
当前业界的架构设计,大体上可以分为 6种:
1. 单库单应用模式
这种模式一般只有一个数据库,一个后台管理系统(当然也可以有前台应用)。
这是最简单的架构设计模式,也是所有IT初学者最先(必须)接触到的模式。
说一下该模式的优缺点:
优点:结构简单、开发速度快、实现简单,可用于产品的第一版原型验证需求、用户少的设计。
缺点:性能差、没有解决“高并发,高可用、大数据、易扩展“的问题(所以不能用于正式业务的生产环境)
注1:该架构是其他架构设计模式的基础(再复杂的架构,也都是在这个模式上不断演进的)
注2:目前流行的前后端分离模式,只是将前端工程化,但本质上并没有改变应用架构的本质,所以在本文中仍然归类为这一种。
2、内容分发模式
这种模式主要解决”静态资源(网页,图片,js,css等)的访问性能问题”
与单库单应用模式相比:多了一个OSS云存储(阿里云,七牛云等)和一个CDN加速网络
CDN加速原理:
1)程序通过调用OSS上传接口,得到图片访问地址U,并把U地址入库
2)CDN网络会将真实图片资源,在各个CND节点缓存一份;
3)用户访问地址U时,CDN先拿到用户端IP,然后再通过一个DNS智能查询算法,找出与该用户距离最近(或通讯时间最短)的CDN节点服务器,将该服务器的缓存图片下发给用户。
说一下该模式的优缺点:
优点:资源下载快、无需过多的开发与配置,同时也减轻了后端服务器对资源的存储压力,减少带宽的使用。
缺点:目前来说OSS,CDN的价格还是稍微有些贵,只适用于中小规模的应用,另外由于网络传输的延迟、CDN同步策略等,会有数据不一致的问题。
3、查询分离模式
这种模式主要解决“查询性能问题”.
这个可以说是单库单应用模式的升级版本,也是架构迭代演进过程中的必经之路。
与单库单应用模式相比:进行了业务数据库的主从分离,并引入了ES搜索引擎
为什么要这样做呢?下面结合两个业务需求场景进行叙述。
场景一:业务读多写少
有统计数据表明,一般的业务系统,读(查询)场景跟写(保存)场景的比例在7;3(甚至8:2)以上
这就决定了我们的系统中会有大量的查询请求。
如果仅仅是因为数据库的写性能遇到了问题,而导致我们的系统80%的读场景不可用,这显然是不能够接受的。
针对此问题,业界较为成熟的方案就是对数据库进行”读写分离“,即写的时候入主库,读的时候读从库。
这样就把压力分散到不同的数据库了,如果一个读库性能不行,扛不住的话,可以一主多从,横向扩展。
一般的业务流程是这样的:
1)服务端把一条业务数据,写到主数据库(master)
2)主数据库通过”同步策略“将该数据同步到从库中(slave)
3)需要数据查询时,直接去从库(slave)读相应的数据
一些聪明的、爱思考、想上进的同学可能发现问题了:就是数据的延迟问题,
比如:数据还没有同步到从库,我就马上读,那么肯定是读不到的。
对于这个问题,各家公司解决的思路不一样,方法也就不尽相同。
比如其中一个解决方案是:先尝试读从库,如果读不到就再尝试读主库。
场景二:关键词全文检索
业务系统都会有关键字搜索的需求,如果使用传统的数据库技术,基本都会使用like这种SQL语句。
众所周知:当数据量达到一定级别,SQL全表扫描会有严重的性能问题。
解决办法就是全文检索场景直接走ES搜索引擎(ES不仅可以替代数据库完成全文检索功能,还可以实现诸如分页、排序、分组等功能)
ES搜索引擎的一般使用流程为,
1)服务端把一条业务数据落业务库,同时异步发送给ES
2)ES把该条记录按照预定规则、配置放入自己的索引库
3)客户端查询时,由服务端把这个请求发送到ES,ES根据需求拼装、组合数据,返回给客户端
说完了两个场景,该总结一下这种设计模式的优缺点的了:
优点:减少数据库的压力,理论上提供无限高的读性能,间接提高业务(写)的性能,专用的查询、索引、全文(分词)解决方案。
缺点:数据延迟,数据一致性的保证和解决。
4、分库分表模式
这种模式主要解决"单表写入压力过大的问题",这个模式也是架构迭代演进过程中的必经之路。
对于单个业务表,一般有水平切分和垂直切分两种,这里主要介绍水平切分。
理论上:一台主机可以有多个实例,一个实例中可以有多个库,一个库可以有多个表。
实践中:一台主机上只有一个实例,一个实例中只有一个库,库==实例==主机,所以才有了分库分表这个简称。
接下来以一个例子来讲解一下分表流程:
假设用户表(user),数据量有1亿用户,查询、插入、存储都出现了问题,怎么分呢?
首先,分析问题,这个明显是由于数据量太大了而导致的问题。
其次,设计方案,可以分为10个库,这样每个库的数据量就降到了1KW,单表1KW数据量还是有些大,而且不利于以后量的增长,所以每个库再分100个表,这个每个单表数据量就为10W了,对于查询、索引更新、单表文件大小、打开速度,都有益处。
再次,给IT运维部门打电话,要10台物理机,扩展数据库...... 最后,逻辑实现,这里是最有学问的地方。首先是写入数据,需要知道写到哪个分库分表中,读也是一样的,所以,需要有个请求路由层,负责把请求分发、转换到不同的库表中,
说说这个模式的问题:
1)事务问题
因为分库分表,传统事务完成不了,而分布式事务又太笨太重,所以这里需要有一定的策略,保证在这种情况下事务能够完成。常用的策略如:最终一致性、复制、特殊设计等。
2)关联和分组查询改造
该模式下,传统的 join, orderby,grouby 都不能再用了,需要在业务代码层进行改造。(如何解决这些副作用不是一句两句能说清楚的,以后会单独开篇,敬请及时关注作者)
该总结一下这种模式的优缺点的了,如下:
优点:减少数据库单表的读写压力。
缺点:事务保证困难、业务逻辑需要做大量改造。
5、微服务架构模式
上面的模式看似不错,但也只是解决了部分性能问题。但是软件系统天生的复杂性,决定了还有其他诸如”高可用、健壮性、易扩展“等大量问题等待我们去解决.
微服务模式 可以说是最近的热点,花花绿绿、大大小小、国内国外的公司都在鼓吹,实践这个模式,可是大部分都没有弄清楚为什么要这么做,也并不知道这么做有什么好处、坏处,
在这里,我以自己的亲身实践说一下我对这个模式的看法,也请大家在评论区踊跃留言!
随着项目发展,业务与人员的规模会不断增加,从而会陆续遇到了如下问题:
1)数据库写压力大量增加,导致数据库不堪重负, 数据库一旦挂了,那么整个系统业务都挂了
2)业务代码越来越多,全都放在一个GIT里,越来越难以维护
3)上线要求越来越频繁,经常是一个小功能的修改,就要整个大项目要重新编译
4)其他一些外围系统直接连接数据库,导致一旦数据库结构发生变化,所有的相关系统都要通知,甚至对修改不敏感的系统也要通知
5)每个应用服务器需要开通所有的、相同的、访问权限和网络权限,因为每个服务器部署的应用都是一样的
慢慢的,所有人,都已经失去了对这个系统的把控......
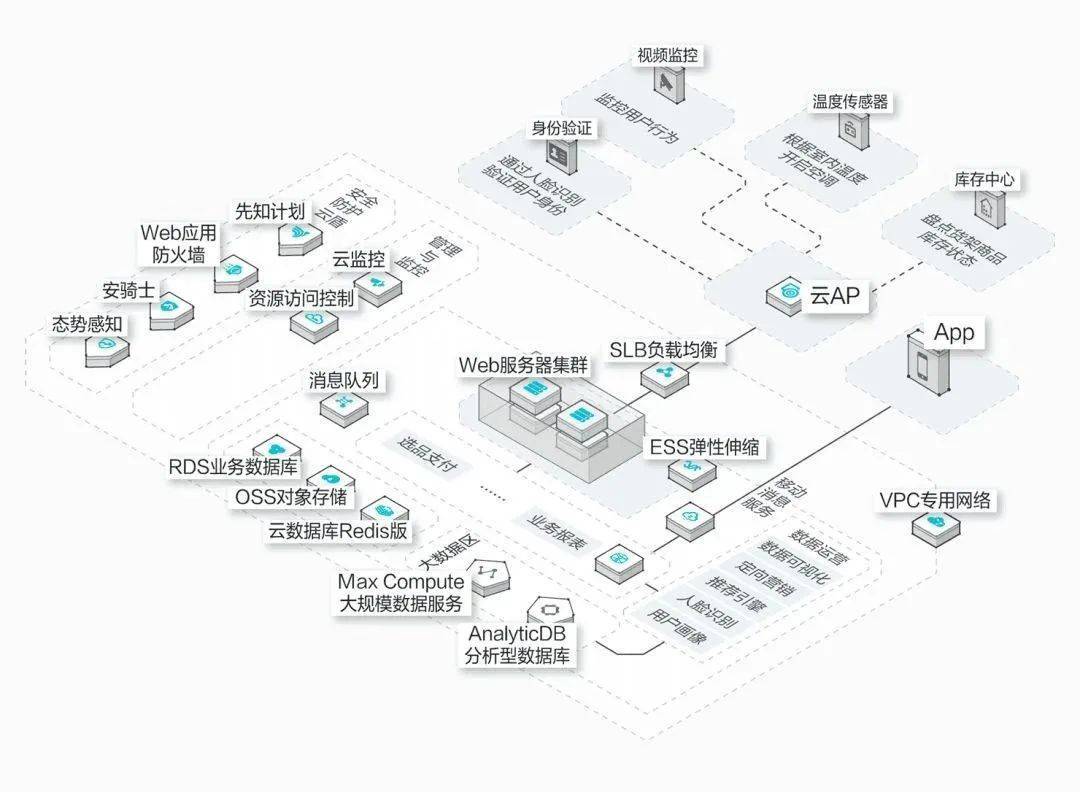
微服务架构,就是为了解决上述这些问题,这种模式的一般设计见下图:

如上图所示,我们把业务分块做了垂直切分,切成一个个独立的业务系统,每个系统各自衍化,有自己的业务库、缓存库等,
系统之间的实时交互通过RPC远程调用,异步交互通过MQ消息队列
通过这种组合,共同完成整个系统功能。
这样,对于上面的5个问题,我们就都有了解决方案:
对于问题1:由于拆分成了多个子系统,系统的压力被分散了,而各个子系统都有自己的数据库实例,所以数据库的压力变小。
一个子系统A的数据库挂了,只是影响到系统A和使用系统A的那些功能,不会所有的功能不可用,从而可以解决一个数据库挂了,导致所有功能不可用的问题。
对于问题2:各个子系统有自己独立的GIT代码库,不会相互影响。通用的模块可通过库、服务、平台的形式解决。
对于问题3:子系统A发生改变,需要上线,那么我只需要编译A,然后只上线部署A就可以了,不需要其他系统做同样的事情。
对于问题4:所有需要访问的业务数据,都通过接口的形式发布出去,客户通过接口获取数据,从而屏蔽了底层数据库结构。我们只需保证接口契约没有发生变化即可,新的需求增加新的接口
对于问题5: 不同的子系统需要不同的权限,这个问题也优雅的解决了。
目前来看,所有问题都得到了解决???
注意:采用该架构,会有许多其他副作用随之产生,如RPC、MQ的超高稳定性、超高性能,网络延迟,数据一致性等问题,这里就不展开来讲了,太多了,一本书都讲不完。
另外:对于这个模式来说,最难把握的是拆分的维度,细粒度
一个较为可行的拆分指导原则是:能不分就不分,除非有非常必要的理由!
该总结一下这种模式的优缺点的了,如下:
优点:相对高性能,可扩展性强,高可用,适合于中等以上规模公司架构。
缺点:复杂、粒度不好把握。不仅需要一个能在高层把控大方向、大流程、总体技术的人,还需要能够针对各个子系统有针对性的开发。把握不好度或者滥用的话,投入产出会适得其反!
6、弹性伸缩模式
这种模式主要解决流量高并发(流量突发)的问题。
比如:天猫双11或京东618,会在特定的时间带来巨大流量,但是传统横向扩展方案实施又比较慢,如果设计处理不好就会影响业务,甚至全站崩溃。
这个模式是一种相对来说比较高级的技术,也是各个大公司目前都正在研究、试用的技术。
时至今日,有这种思想的架构师就已经是算是很不错了,更别提那些已经动手实践过的,所以,你懂得......
与微服务模式相比,这种架构会多出一个“弹性伸缩服务”,用来动态的增加、减少实例。
具体实现上,比较成熟的两种资源池方案是VM、Docker,每个产品目前都有着自己强大的生态。监控的点有CPU、内存、硬盘、网络IO、服务质量等,根据这些,在配合一些预留、扩张、收缩策略,就可以简单的实现自动伸缩。
该总结一下这种模式的优缺点的了,如下:
优点:弹性、随需计算,充分优化企业计算资源。
缺点:应用要从架构层做到可动态配置的横向扩展,弹性伸缩改造、依赖的底层配套比较多,对团队的技术水平、运维实力、应用规模要求都非常高。
【全文完】