基于性能怪兽如何构建日均亿级吞吐量的网关架构?
引言
在关于《Nginx》的文章中曾经提到:单节点的Nginx在经过调优后,可承载5W左右的并发量,同时为确保Nginx的高可用,在文中也结合了Keepalived对其实现了程序宕机重启、主机下线从机顶替等功能。
但就算实现了高可用的Nginx依旧存在一个致命问题:如果项目的QPS超出5W,那么很有可能会导致Nginx被流量打到宕机,然后根据配置的高可用规则,Keepalived会对Nginx重启,但重启后的Nginx依旧无法承载业务带来的并发压力,结果同样会宕机.....
经过如上分析后,明显可看出,如果Nginx面对这种超高并发的情况,就会一直处于「在重启、去重启的路上」这个过程不断徘徊,因此在此背景下,我们需要设计出一套能承载更大流量级别的接入层架构。
不过相对来说,至少90%以上的项目用不上这套接入层架构,因为大部分项目上线后,能够拥有的用户数是很有限的,压根无法产生太高的并发量,所以往往一个Nginx足以支撑系统的访问压力。
不过虽说大家不一定用得上,但不懂两个字我们绝不能说出口,尤其是面试过程中,往往频繁问到的:你是如何处理高并发的? 跟本文有很大的联系,之后被问到时,千万先别回答什么缓存、削峰填谷、熔断限流、分库分表.....等这类的,首先需要先把接入层说清楚,因为如果接入层都扛不住访问压力,流量都无法进到系统,后续这一系列处理手段自然没有意义。
一、亿级吞吐第一战-DNS轮询解析
对于单节点的Nginx而言,虽然利用Keepalived实现了高可用,但它更类似于一种主从关系,从机在主机正常的情况下,并不能为主机分担访问压力,也就代表着作为主节点的机器,需要凭“一己之力”承载整个系统的所有流量。那么当系统流量超出承载极限后,很容易导致Nginx宕机,所以也需要对Nginx进行横向拓展,那又该如何实现呢?最简单的方式:DNS轮询解析方案。
DNS轮询解析技术算一种较老的方案了,但在如今的大舞台上依旧能够看见它的身影,它源自于DNS的域名多记录解析,在《HTTP/HTTPS》文章中曾聊到过,DNS域名系统本质上是一个大型的分布式K-V数据库,以域名作为Key,以物理服务器的公网IP作为Value,而大多数域名注册商都支持为同一个域名配置多个对应的IP,如下:
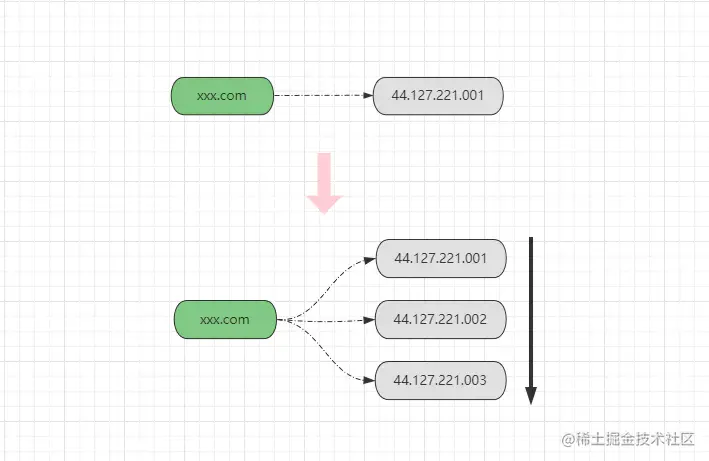
如上图所示,为一个域名配置多个映射的IP后,DNS服务器在解析域名请求时,就会依据配置的IP顺序,将请求逐一分配到不同的IP上,也就是《上文》所提及到的轮询调度方式。
借助DNS的轮询解析支持,对Nginx可以轻松实现横向拓展,也就是同一个域名配置的多台物理机,分别都部署一个Nginx节点,每台Nginx节点的配置信息都一样。
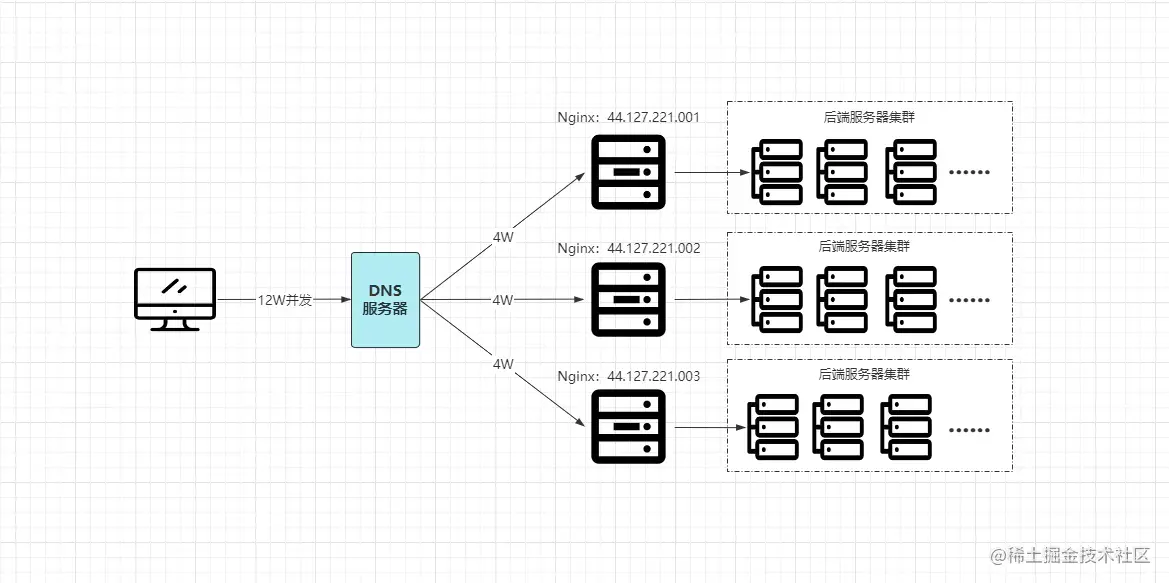
好比目前每瞬12W的并发量,配置域名时,映射3台真实Nginx服务器,最终经过DNS轮询解析后,12W的并发请求被均摊到每台Nginx,每个节点分别承载4W的并发请求,通过这种方式就能够完美的解决之前的:单节点Nginx无法承载超高并发量而宕机的问题,如下:
![Nginx水平集群]
同时DNS域名解析,也依旧可以配置调度算法,如Rate权重分配、最少连接数分配、甚至可以按照客户端网络的运营商、客户端所在地区等方式进行解析分配,但仅一小部分的DNS服务器支持。
浅谈DNS域名轮询解析的优劣
这种方式带来的优势极为明显:
无需增加额外的成本即可实现多节点水平集群,利于系统拓展。
但也存在非常大的劣势:
- ①与其他的负载均衡方案不同,其他的负载方案一般都会自带健康监测机制,但DNS则无法感知,也就是当下游的某服务器宕机,DNS服务器会依旧向其分发请求。
- ②无法根据服务器的硬件配置,合理的分配客户端请求,大部分DNS服务器只支持最简单的轮询调度。
虽然DNS轮询解析方案存在很大的劣势,但这两个劣势对比其带来的收益可以忽略不计,因为现在云计算技术的发展,多台节点保持相同的配置已不再是难事。同时,由于Nginx本身就会利用Keepalived的VIP机制实现高可用,所以就算某个节点宕机,从机也可顶替上线接管流量,中间只会有很短暂的切换时间。
而且如果DNS将客户端请求分发到某个宕机节点时,客户端看到的结果便是空白页、超时无响应或请求错误的信息,通常情况下,依据用户的习性,都会再次重试,那么客户端再次发出的请求会被轮询解析到其他节点,而从机在这个时间间隔内也能够成功上线接管服务。
二、亿级吞吐第二战-CDN内容分发
CDN(Content Delivery.NETwork)内容分发网络是一种构建在现有网络基础上的智能虚拟网络,依靠部署在全球各地的节点,通过负载均衡、内容分发、机器调度等功能,使用户的请求能够被分发到离自身最近的节点处理,就近获取所需的资源,最终达到提升用户访问速度以及降低服务器访问压力等目的。
CDN出现的本质是为了解决不同地区用户访问速度不一致问题,在之前的《TCP/IP》文中曾提到过,网络上的数据传输本质上最终都会依赖于物理层的传输介质,那么当用户和目标服务器的“实际地理距离”越长,访问的速度自然会越慢,而CDN的核心就在于:各地区都会部署子节点,当用户访问时,会将其请求分发到距离最近的节点处理,就好比生活中的例子:
某个想吃北京烤鸭的人身在美国,最初仅北京有相应的店铺,因此想吃的时候必须得跑到北京去买,那么这一去一回的过程自然会需要很长时间,而CDN的思想就是在各地都开分店,好比美国也有北京烤鸭的分店,当某个用户想吃时,不再需要跑到北京去买,而是可以直接选择就近的店铺进行购买,这样速度自然会更快。
2.1、CDN分发的内容
通常一个平台的资源都会分为静态与动态两种类型,而CDN本质上是一种类似于缓存的技术,缓存必然会存在延迟性,对于会经常发生变化的动态资源,使用CDN意义并不大,因为CDN无法确保数据的实时性。
由于静态资源很少发生变更,所以CDN一般会用于静态资源的分发,如果你要使用CDN服务,国内有大量的CDN提供商提供这类服务,当购买CDN服务后,将静态资源传给CDN服务,那么这些静态资源将自动的被分发到提供商全球各地的CDN节点。
2.2、CDN实现原理
在系统接入CDN服务并将静态资源传递给CDN后,那么当用户再访问系统时,对应的一些请求就会被分发到距离用户最近的CDN节点处理,但这究竟是如何实现的呢?接下来简单聊一聊。
一般用户发送请求都是通过域名去进行访问的,域名最终会被解析成一个IP,那么如何解析出一个距离用户最近的服务器IP,这是普通的DNS服务器做不到的,因此CDN为了实现这点,需要特殊的DNS服务器去解析域名请求,该DNS服务器需要解决两个问题:
①需要得知用户目前的所在位置。
②CDN所有节点中,哪个节点离用户最近。
对于上述两个问题,第一个问题可以直接从用户的请求中提取客户端IP,然后根据IP去判断,可以将IP解析为上海电信、北京移动等,从而能够确定用户的大概位置。
第一个问题容易找到答案,但实现CDN请求分发的难点在于第二个问题:如何确定距离用户最近的CDN节点。这时就需要用到DNS解析中的CNAME机制了,DNS域名解析主要会分为两种:
- ①将一个域名解析为一个具体的IP,这种方式被称为A记录机制。
- ②将一个域名解析为另一个域名,这种方式就被称为CNAME机制。
在CDN中,这个CNAME会被配置为CDN专用DNS服务器的域名地址。
某个用户通过域名static.xxx.com请求静态资源时,这个域名会映射着一个CNAME,例如cdn.xxx.com,当普通的DNS服务器收到用户的static.xxx.com域名请求后,经过解析得到一个CNAME,该CNAME对应的则是CDN专用的DNS服务器,那么会将域名解析工作转交给该DNS服务器处理,CDN专用DNS服务器对cdn.xxx.com域名解析,根据服务器上记录着的所有CDN节点信息,选出距离用户最近的CDN服务器地址并返回给用户,最后用户就可通过该地址访问距离自己最近的CDN节点。
上述这个过程也被称为智能DNS解析技术。
2.3、CDN带来的优势
大致聊了CDN分发原理后,再来思考思考CDN的引入能够给系统带来哪些好处呢?
- ①加快用户的访问速度,带来更好的用户体验感。
- ②分担系统50%以上的访问流量,降低系统的负载压力。
- ③节省系统源站的带宽消耗,降低网络带宽的成本。
- ④进一步提升系统安全性,大部分攻击请求会被CDN节点阻挡。
从上看来,系统接入CDN服务后带来的收益很大,就算原本的系统访问速度很慢,在接入CDN后也能够快速加载,对于用户而言体验感会进一步提升,并且最关键的是:对于网站整体而言,几乎90%以上的静态请求会由CDN去响应,系统源站能够减轻很大的访问压力,从而能够确保系统本身拥有更大的“动态请求”吞吐能力。
三、亿级吞吐第三战-LVS负载均衡
在之前提到过,我们可以通过DNS的轮询解析机制对Nginx实现水平拓展,从而使得接入层能够承担更高的并发访问,但DNS由于其机制的不健全,所以一般并不会采用它去实现Nginx的集群,毕竟动态伸缩也不方便,更改配置后需要3~4小时才能生效。
如果要对Nginx实现集群,一般都会采用LVS去实现,也包括淘宝、腾讯等大部分企业,都使用了LVS技术,那什么是LVS呢?

LVS是linux Virtual Server的简称,意为Linux虚拟服务器,本项目在1998年5月由章文嵩博士成立,在Linux2.6版本中被正式加入系统内核,关于更多可参考:《LVS-百度百科》。
LVS一般被用作于负载调度器,它与Nginx的功能类似,但不同点在于:LVS工作在OSI七层网络模型中的第四层-网络层,而Nginx则是工作在第七层-应用层,同时LVS并非是以进程的方式运行在操作系统上的,而是直接位于Linux内核中工作,因此LVS的性能一般是Nginx的十倍以上。
其实在很多大型互联网企业中,都能看见LVS的身影,例如淘宝的接入层设计、阿里云中的SLB-CLB四层负载均衡服务等都是基于LVS实现的。
LVS相较于其他软件负载均衡技术(Nginx、HaProxy)的特点:
- ①工作在网络层,位于系统内核,拥有更高的性能、可用性。
- ②能够将许多低性能的服务器组合在一起形成一个高性能的超级服务器群。
- ③拥有四种工作模式以及十二种调度算法,适用于各类不同的业务场景。
- ④拥有健全的节点健康监测机制,并且拥有很强的拓展性,支持动态伸缩。
同时在LVS中存在大量专业术语,如下:
- Director:负载均衡器,指LVS本身。
- Balancer:请求分发器,也指LVS本身。
- Real Server(RS):后端负责请求处理的服务器。
- Client IP(CIP):客户端的IP地址。
- Virtural IP(VIP):虚拟IP地址。
- Director IP(DIP):LVS所在的服务器IP地址。
- Real Server IP(RIP):后端服务器的IP地址。
LVS基本工作原理
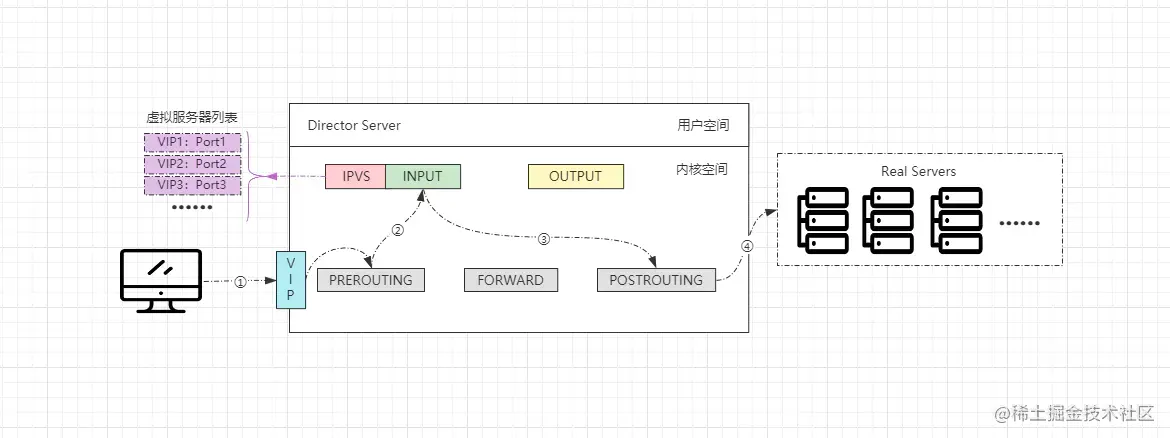
- ①客户端通过访问VIP发送请求报文,调度器收到后会将其发往内核空间。
- ②内核中的PREROUTING链会先收到请求,确认是发往自己的请求后会转给INPUT链。
- ③ip_vs是工作在INPUT链上的,IPVS会将用户请求和VIP列表进行匹配,匹配成功后会修改请求报文中的目的地址及端口,然后将新的报文发给POSTROUTING链。
- ④POSTROUTING链收到报文后,发现更改后的报文中目标地址正好是自己配置的后端服务器RS地址,那此时就会通过选路,最终将数据报文发送给后端服务器。
OK~,对于LVS有了一点基本认识之后,接着来看看LVS中四种工作模式以及十二种调度算法。
3.1、LVS四种工作模式
在LVS中,为了适应不同的应用场景,因此也专门研发了多种不同的工作模式,每种工作模式都有各自的应用场景,LVS中共计存在四种工作模式: NAT、DR、TUN、FULL-NAT,其中最为常用的是DR直接路由模式,接下来详细剖析看看。
3.1.1、网络地址转换模式(NAT)
NAT模式与带有防火墙的私有网络结构类似,LVS作为所有后端服务器节点的网关层,客户端请求与后端服务器的响应都会经过LVS,LVS在整个接入层中作为客户端的访问入口,作为服务端的返回出口,后端服务器位于内网环境,使用私有IP地址,与LVS位于同一物理网段,如下:
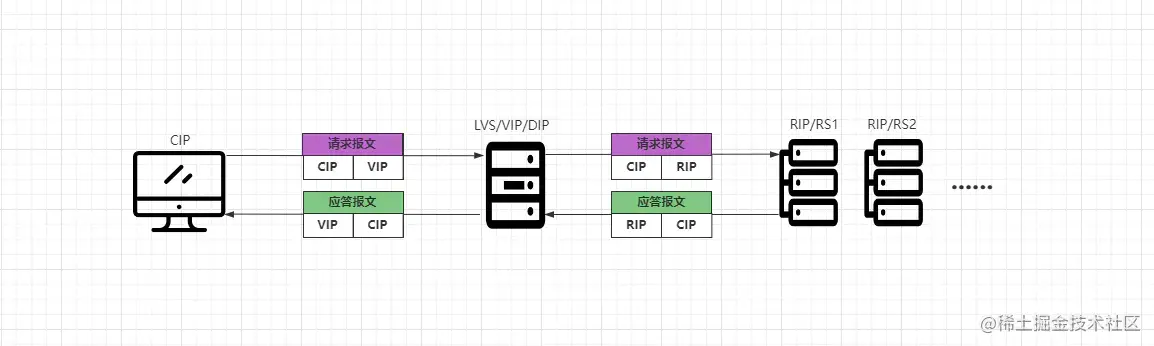
- ①客户端CIP请求VIP,VIP即DIP,也就是LVS本身。
- ②LVS将客户端请求报文中的目标地址改为后端一台具体的RIP地址。
- ③RS将请求处理完成后,会将响应结果组装成应答报文返回给LVS。
- ④LVS收到后端的响应数据后,会将响应报文中的目标地址改为自身的VIP。
在NAT模式中,由于请求/应答的双向流量都需要经过LVS,因此对于LVS的性能、带宽开销比较大,同时需要注意:如果采用NAT模式,那么DIP、RIP必须要在同一个物理网络中。
3.1.2、直接路由模式(DR)
DR模式中,是采用半开放式网络结构实现的,后端的各节点与LVS位于同一个物理网络,LVS在其中作为客户端的访问入口,但服务端返回响应时则不需要经过LVS,而是直接把数据响应给客户端,如下:
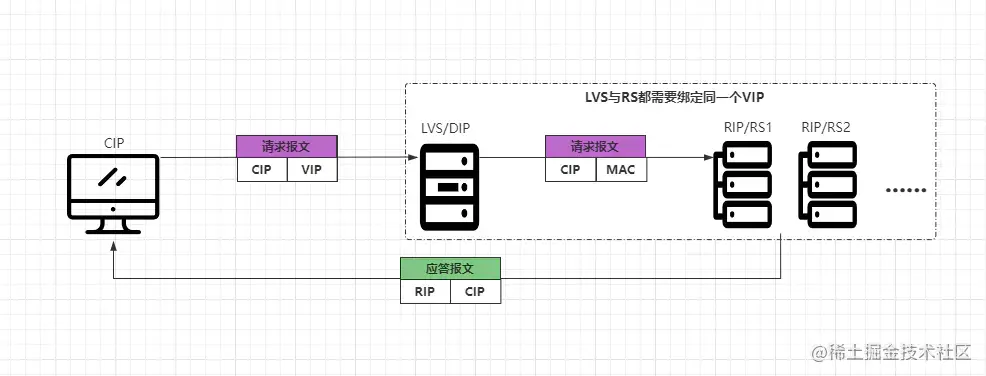
- ①客户端CIP请求VIP,请求报文中CIP为源地址,VIP为目标地址。
- ②请求会先到LVS上,LVS会将报文中的目标mac地址改变为某台RS的MAC地址。
- ③RS收到请求后发现是自己的MAC地址,并且也是自己的IP地址,则会处理请求。
- ④RS处理完成请求后,会根据请求报文中的源地址,直接将应答报文返回给CIP。
在DR模式中,很明显的可以看出,客户端请求的流量会通过LVS作为入口,但服务端的应答流量却不用通过LVS作为出口。因为在DR模式中,LVS与后端的RS都会绑定同一个VIP,然后LVS会通过修改目标MAC地址的方式实现请求分发,当RS收到请求后,发现目标MAC、IP地址都是自己后,就会开始处理请求。
在这个过程中,由于客户端请求的是VIP地址,而LVS、RS都绑定相同的VIP,所以LVS改掉目标MAC地址,转发请求后,在RS角度来看是无法感知的,毕竟自己的IP就是请求报文中的VIP,所以RS会认为该请求就是客户端直接请求自己的。
当RS将客户端的请求处理完成之后,会根据请求报文中的源IP地址,作为应答报文的目标IP地址,直接将响应结果返回给客户端,无需经过LVS再次包装,这样能够很好的解决之前NAT模式中存在的不足。
3.1.3、IP隧道模式(TUN)
TUN模式是采用开放式网络结构,服务端的各节点可以不与LVS位于同一网络,也就是后端服务器可以分散在互联网中的不同网络中,但每个后端节点必须要有独立的公网IP,因为LVS需要通过专用的IP隧道与后端节点相互通信。其中LVS主要作为客户端的访问入口,服务器响应结果时,直接通过各自的Internet连接返回给客户端,不需要经过LVS,如下:
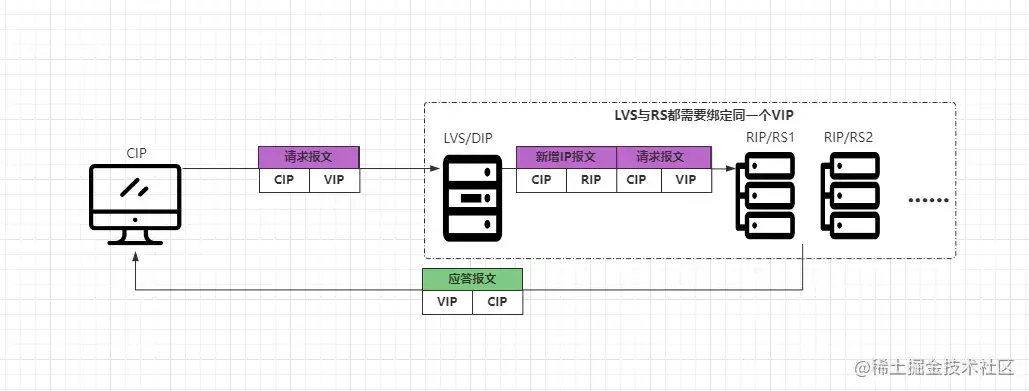
- ①客户端发送请求报文到LVS服务器,报文源IP为CIP,目标IP为VIP。
- ②LVS收到请求报文后,不会再修改报文内容,而是在报文前面再添加一个IP报文头。 新增的IP报文中源地址为CIP,目标地址为一台具体的RIP。
- ③RS收到新封装的报文后,会解封数据报,然后处理客户端请求。
- ④处理完成后会根据请求报文中的源IP:CIP,将应答报文直接返回给客户端。
从上述过程中会发现,TUN模式似乎与之前的DR模式有些类似,但与DR模式不同的是:TUN模式是基于IP隧道技术实现的,并且整个LVS集群中的所有节点,都可以不在一个物理网络中,也就是LVS、RS可以是分散在各地的服务器,但需要额外注意:VIP、DIP、RIP必须全部要为公网IP,不然无法使用IP隧道机制。
3.1.4、双向网络地址转换模式(FULL-NAT)
FULL-NAT模式在之前的版本中是不存在的,这个模式是章文嵩博士去了阿里之后,专门针对于阿里的业务研发的一种新模式,它是NAT模式的升级版本,在NAT模式中只做两次IP转换,而FULL-NAT模式会做四次,如下:
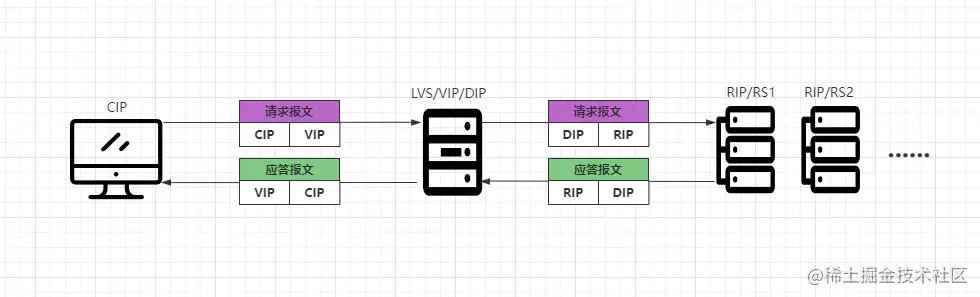
- ①客户端会先发送请求报文到LVS,报文中源IP为CIP,目标IP为VIP。
- ②LVS收到客户端的报文后,会将源地址改为自身的DIP,并将目标IP改为RIP。
- ③RS接收到请求后会进行处理,处理完成之后会将应答报文返回给LVS服务器。
- ④LVS会将应答报文中的源IP改为VIP,目标IP为CIP,从而将数据响应给客户端。
在FULL-NAT模式中,一共会做四次IP的转换,那为何要这样实现呢?因为之前的NAT模式中,DIP、VIP、RIP都必须要位于同一个VLAN物理网络中,那么此时就会导致RS集群的主机数量受到限制。
在FULL-NAT模式中,LVS收到客户端请求后,会将报文中的源地址改为自身的DIP,并将目标IP改为RIP,这样对于RS而言,DIP就成了客户端,因此可以实现跨VLAN、跨机房、跨网络进行请求分发。
当RS处理完对应的请求后,会将数据返回到LVS,LVS又会将应答报文中的源IP改为VIP,目标IP为CIP,从而由LVS作为响应者返回数据。
当然,FULL-NAT模式虽然能够实现跨网络分发,但由于其中进行了多次IP转换,因此对比普通的NAT模式而言,分发的效率要降低10%左右。
3.1.5、四种工作模式对比
|
对比项 |
NAT |
DR |
TUN |
FULL-NAT |
|
分发性能 |
NO.03 |
NO.01 |
NO.2 |
NO.4 |
|
网络结构 |
封闭式网络 |
半开放式网络 |
开放式网络 |
半开放式网络 |
|
数据响应 |
LVS |
RS |
RS |
LVS |
|
转发实现 |
改目标IP |
改目标MAC |
新增IP数据报 |
重构IP数据报 |
|
使用限制 |
局域网络 |
绑定同一VIP |
需支持Tunneling |
RS与LVS要能通信 |
|
模式特点 |
内外网隔离 |
性能最佳 |
远距离分发 |
可跨网络分发 |
在LVS的四种工作模式中,DR是性能最好的,也是正常情况下使用最为频繁的工作模式,同时也是LVS默认的工作模式。
3.2、LVS十二种调度算法
与其他的负载调度技术相同,在LVS中也提供了多种调度算法,主要也分为两大类:静态调度以及动态调度算法,两类算法共计十二种,如下:
- 静态调度算法: 轮询算法(RR) 加权轮询算法(WRR) 源地址哈希算法(SH) 目标地址哈希算法(DH)
- 动态调度算法: 最小连接数算法(LC) 加权最小连接数算法(WLC) 最短延迟算法(SED) 最少队列算法(NQ) 局部最少连接数算法(LBLC) 带复制的局部最少连接数算法(LBLCR) 加权故障转移算法(FO) 加权活动连接数算法(OVF)
其中动态算法对比静态算法而言会更为智能化,但分发效率也会更低,接下来简单看看LVS中提供的每种调度算法。
不会对每种算法进行原理剖析,大致分析其过程和思想,如想要了解调度算法具体实现的小伙伴可参考上篇:《网络编程之请求分发篇》。
3.2.1、轮询算法(RR)
轮询算法在LVS中也被称为轮叫、轮调算法,但本质上意思都是相同的,对于配置的多个服务端节点,依次分发请求处理。
在这种算法中,分发请求时讲究雨露均沾,会对配置的所有节点无差别的依次调度。
具体实现可参考《请求分发篇-轮询算法实现》。
3.2.2、加权轮询算法(WRR)
这种算法属于轮询算法的升级版本,主要是为了照顾到集群中硬件配置不同的节点,根据服务器自身的硬件基础,为不同服务器配置不同的权重值,性能越好的服务器配置越高的权重值,LVS在分发请求时,会根据配置的权重值,分发对应比例的请求数到每台服务器。
这种算法相较于基本的轮询调度而言,更加智能化一些,因为能够根据节点的性能去配置对应权重,能够在最大程度上将每台服务器的性能发挥到极致。
具体实现可参考《请求分发篇-平滑加权轮询算法实现》。
3.2.3、源地址哈希算法(SH)
之前的两种调度算法,都无法解决session不一致问题:
session不一致问题:好比最简单的登录功能,客户端发送请求登录成功,然后将其登录的状态保存在session中,结果客户端的第二次请求被分发到了另外一台机器,由于第二台服务器session中没有相关的登录信息,因此会要求客户端重新登录。
而源地址哈希算法中,LVS会根据请求报文中的源IP地址进行哈希计算,然后最终计算出一台服务器的IP,并将该请求分发到对应的节点处理,同时由于分发请求是基于哈希算法实现的,那么之后每当相同的客户端请求时,由于源IP地址是相同的,所以同一客户端的请求都会被分发到同一台服务器处理。
3.2.4、目标地址哈希算法(DH)
与源地址哈希算法相同,目标地址哈希算法也是一种基于哈希算法实现的,但该算法中是基于目标地址作为哈希条件去进行计算,从而计算出一台的具体服务器地址,最后将对应的请求转发到对应节点处理。
需要额外注意的是:这里的目标地址并非指请求报文中的目标IP地址,因为本质上客户端都是通过请求相同的VIP来访问LVS的,所以请求报文中的目标IP地址都是相同的,要是基于目标IP地址去计算,那么会将所有请求都分发到一个节点上。
既然不是通过请求报文中的目标IP地址进行计算,那这里所谓的“目标地址”究竟是什么呢?要搞清楚这个点之前,首先得理解DH算法的应用场景,一般DH算法都是应用在缓存场景中的,所以这里的“目标地址”其实是缓存的目标Key值,举例:
请求①:put name '竹子'
请求②:get name
复制代码
在上述案例中,请求①是写入操作,其Key为name,DH算法会以该值作为哈希计算的条件,从而算出一台服务器地址,并将其该Key值的缓存项写入到该节点中。请求②则是一个读取操作,由于读取的目标为name,与之前写入操作的Key相同,那么DH算法计算之后,最终得到的服务器地址也是相同的,就会将这个读取请求分发到之前写入缓存的节点,确保能够命中数据。
对于两种哈希算法的具体实现可参考《请求分发篇-一致性哈希算法实现》。
3.2.5、最小连接数算法(LC)
最小连接数算法,也可以被称为最小活跃数算法、最空闲节点算法等,该算法属于动态算法的一种,相较于之前的四种静态算法,该算法更为智能化,在这种算法中可以根据所有节点的负载情况,进行“相对合理”的请求分发,永远都会选取最为空闲的那台服务器来处理请求。
如果存在多个连接数都为最小的节点,则是类似于轮询的方式去依次调度。
这种算法中,能够根据线上各服务器的实际运行情况分发请求,能够将集群中“做事最少的节点揪出来”处理请求,从而做到“杜绝任何服务器出现摸鱼情况”。
3.2.6、加权最小连接数算法(WLC)
LC、WLC算法的关系就类似于之前的轮询和加权轮询算法,加权最小连接数算法是最小连接数算法的升级版本,也就是说可以为每个节点配置权重,当寻找连接数最小的节点时,如果集群中存在多个连接数都为最小的节点,那最终就会根据配置的权重值,来决定当前请求具体交由谁处理。
在Dubbo的负载均衡-最小活跃数算法的实现中,实现的就是加权最小活跃数版本。
对于最小连接数算法的具体实现感兴趣的小伙伴可参考《请求分发篇-最小活跃数算法实现》。
3.2.7、最短预期延迟算法(SED)
最短预期延迟算法是基于WLC算法实现的,WLC算法中,如果权重值和连接数都相同,那么会随机调度一个节点处理请求,这显然还并没有那么那么“智能”,因此SED算法的出现就是为了解决该问题。
在WLC算法中衡量连接数标准是综合考虑所有连接数的,而SED算法中则只考虑活动连接数,也就是说SED算法只会选择活动连接数最小的节点,这样能够确保选择的节点将会是整个集群中,预期延迟最短的RS,因为活动连接数最小,所以也就代表着该节点实际负载最低,那么响应速度也就最快。
3.2.8、最少队列算法(NQ)
最少队列算法也被称为永不排队算法,这种算法又是基于SED算法实现的,NQ算法在SED算法的基础上,实现了一个活跃连接数为0的判断,当有节点的活跃连接数为0时,那么无需经过SED运算,而是将请求直接分发过去,在没有节点活跃数为0的情况下,正常使用SED算法分发请求,
LC、WLC、SED、NQ四种算法,本质上都是递进的关系,后面的每种算法都基于之前的算法不足,然后优化后并推出的,最终的目的则是:让请求分发时更为智能,选择出的节点永远都是性能最好的。
不过在上篇文章中,我们也提到了另外一种更为智能的最优响应算法,该算法在开始前,会对服务列表中的各节点发出一个探测请求,然后根据各节点的响应时间来决定由哪台服务器处理客户端请求,该算法能更好根据节点列表中每台机器的当前运行状态分发请求,具体实现可参考《请求分发篇-最优响应算法实现》。
3.2.9、局部最少连接数算法(LBLC)
局部最少连接数算法其实比较鸡肋,属于DH算法的动态版本,相对来说使用的也较少,在该算法中会基于请求的目标地址进行分发,首先根据其目标地址找出该目标地址最近使用的服务器,如若对应的服务器目前可用并没有超载,就直接将该请求分发到这台服务器处理。如若找出的服务器不可用或请求负载过高,则根据LC算法找出集群中连接数最小的节点,并将该请求分发过去。
3.2.10、带复制的局部最少连接数算法(LBLCR)
LBLCR算法也就是基于LBLC算法的升级版本,与LBLC算法的不同点在于:该算法会维护一个目的地址与一组服务器的映射表,而LBLC算法中只会维护目的地址与一个服务器的映射关系。
在LBLCR算法中,会根据请求的目标地址先找到映射的一组服务器,然后根据最少连接数算法从该组服务器中,选出一台节点处理请求,如若选择的节点不可用或负载过高,则会去RS集群中再根据LC算法选择一个节点,然后加入映射的服务器组中,并将请求分发到该服务器。
同时,如果映射的服务器组很长一段时间内都没被修改过,那会自动将“最忙”的服务器移除。
DH、LBLC、LBLCR算法一般都是用于Cache集群环境中,但目前用的也比较少,因为一般的缓存中间件都有成熟的集群方案,除非需要自研缓存集群时,才会用到LVS这些算法作为缓存分发策略。
3.2.11、加权故障转移算法(FO)
加权故障转移算法中,首先会遍历所有的RS节点列表,然后从中找到负载较低且权重值最高的服务器,并将请求分发到该服务器上处理。
对于负载过高的服务器,LVS会对其设置一个IP_VS_DEST_F_OVERLOAD标识,这里说的“找到负载较低的服务器”,即代表着找到未设置IP_VS_DEST_F_OVERLOAD标识的节点。
3.2.12、加权活动连接数算法(OVF)
加权活动连接数算法是基于服务器的活动连接数与权重值实现的,在该算法中会首先找到权重值最高的可用节点,可用节点要满足以下条件:
- ①未设置IP_VS_DEST_F_OVERLOAD标识,即负载较低。
- ②服务器当前的活动连接数小于其权重值。
- ③服务器的权重值不能为0。
找到权重值最高的可用节点后,会将请求分发到权重值最高的服务器,直至其活动连接数超过权重值为止。
FO、OVF算法都是后面新增加的算法,只在内核版本4.15及其以上的版本中才存在,如若你内核的版本低于4.15,那么需要额外打补丁后才能使用。
3.2.13、分发调度算法小结
经过上述分析后,不难得知的是:LVS前前后后共计提供了十二种调度算法,其中静态算法四种,动态算法八种,越到后面的算法,其实现过程就越为复杂,但其分发请求也越为智能。所有算法中用的比较频繁的是RR、WRR、SH、LC、WLC五种。
不过还是之前那句话,越智能的算法往往代表着开销越大,在超高并发的情况下,将所有节点的硬件配置统一标准,采用越普通、越简单的算法才是最佳的选择。
3.3、LVS的安装与管理
LVS因本身是被加入到Linux内核的,所以无需额外再安装,在内核中名为ip_vs。
①首先检测一下内核中是否有LVS模块:
[root@localhost]# lsmod | grep -i ip_vs
ip_vs 141432 0
nf_conntrack 133053 1 ip_vs
libcrc32c 12644 4 xfs,sctp,ip_vs,nf_conntrack
复制代码
②如果没有上面的内容,需要加载一下:
[root@localhost]# modprobe ip_vs
复制代码
将ip_vs模块加载到内核后,即可安装ipvsadm工具了,ipvsadm是LVS官方提供的管理工具,因为LVS本身就成为了内核的一部分,所以我们使用LVS本质上是通过工具对内核的ip_vs模块进行调用。
3.3.1、安装ipvsadm管理工具
①首先需要安装一下ipvsadm工具,在线安装方式:
[root@localhost]# yum install -y ipvsadm
复制代码
离线方式安装方式:
- 一、先创建存放离线包的目录并进入
- 二、通过wget命令从官网拉取源码包
- 三、解压拉取下来的源码包并编译
- 四、如若编译报错则需要安装相关的依赖包
[root@localhost]# mkdir /soft/tools && mkdir /soft/tools/ipvsadm
[root@localhost]# cd /soft/tools/ipvsadm
[root@localhost]# wget https://kernel.org/pub/linux/utils/kernel/ipvsadm/ipvsadm-1.31.tar.gz
[root@localhost]# tar -xzvf ipvsadm-1.31.tar.gz
[root@localhost]# cd ipvsadm-1.31
[root@localhost]# make && make install
# 编译报错请执行下述命令安装依赖包
yum install -y popt-static kernel-devel make gcc openssl-devel lftplibnl* popt* openssl-devel lftplibnl* popt* libnl* libpopt* gcc*
复制代码
②创建一个内核的软链接,提供给ipvsadm工具操作内核中的ip_vs模块:
[root@localhost]# ln -s /usr/src/kernels/3.10.0-862.el7.x86_64/ /usr/src/linux
复制代码
如果你不清楚内核的版本,可以通过uname -r查看,创建对应内核版本的软链接。
③检查ipvsadm是否安装成功:
[root@localhost]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
.......
复制代码
在任意位置输入ipvsadm命令,如果出现如上提示代表安装成功。
④ipvsadm安装成功后,主体文件位置:
- 离线安装的情况下,所有主体文件都会在解压后的目录中。
- 通过yum命令在线安装的情况下,各主体文件的所在位置: 主程序:/usr/sbin/ipvsadm 规则保存工具:/usr/sbin/ipvsadm-save 规则重载工具:/usr/sbin/ipvsadm-restore 配置文件:/etc/sysconfig/ipvsadm-config ipvs调度规则文件:/etc/sysconfig/ipvsadm
3.3.2、ipvsadm指令大全
ipvsadm是LVS工作在用户空间的管理工具,可以通过它管理工作在内核空间的ip_vs,ipvsadm的所有操作指令大体可分为三类:
- 对于虚拟服务器VIP的增、删、改指令。
- 对于真实服务器RS的增、删、改指令。
- 对于LVS自身的操作与查看指令。
用法如下:
ipvsadm [option] [value] ....
ipvsadm的参数选项有很多,如下:
- -h(--help):查看命令的帮助信息,列出ipvsadm的所有指令与参数。
- -A(--add service):在VIP服务器列表中添加一条新的虚拟服务器记录。
- -a(--add server):在RS服务器列表中添加一条新的真实服务器记录。
- -t(--tcp-service):代表对外提供TCP服务。
- -u(--udp-service):代表对外提供UDP服务。
- -r(--real-server):表示真实服务器的IP地址。
- -s(--scheduler):代表目前服务器列表使用何种调度算法。
- -w(--weight):为每个RS节点配置权重值。
- -m(--masquerading):指定LVS的工作模式为NAT模式。
- -g(--gatewaying):指定LVS的工作模式为DR模式。
- -i(--ipip):指定LVS的工作模式为TUN模式。
- -6(--IPv6):指定LVS支持IPv6类型的IP访问。
- -E(--edit-service):编辑VIP列表中的一条虚拟服务器记录。
- -D(--delete-service):删除VIP列表中一条虚拟服务器记录。
- -C(--clear):清空VIP列表中的所有虚拟服务器记录。
- -R(--restore):恢复VIP列表已配置的规则。
- -S(--save):将VIP列表中配置好的规则保存到指定文件中。
- -d(--delete-server):删除一个VIP中的某条真实服务器记录。
- -L|-l(--list):显示VIP服务器列表。
- -n(--numberic):以数字形式输出IP地址与端口。
- -stats:输出LVS自身的流量统计信息。
- -rete:输出LVS流量的出入速率信息。
- -Z(--zero):清空LVS统计的所有信息。
- .......
3.3.3、LVS-DR模式实操
①准备工作,准备三台Linux,所有的服务器都需要关闭防火墙以及selinux。
- 192.168.12.129:作为director,部署LVS。
- 192.168.12.130:作为真实服务器RS1,部署后端服务。
- 192.168.12.131:作为真实服务器RS2,部署后端服务。
②在LVS所在的Linux网卡上绑定VIP(需要根据机器的网卡类型绑定):
[root@localhost]# ip addr add dev ens33 192.168.12.111/32
复制代码
上述中,我的网卡为ens33,并绑定VIP:192.168.12.111/32。
③为了方便操作,我们把一些操作指令编写成一个lvs-dr.sh脚本,如下:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr.sh
#!/bin/sh
# 指定安装后的ipvsadm主程序位置
adm=/soft/tools/ipvsadm/ipvsadm-1.31/ipvsadm
# 先清除LVS之前配置好的所有规则
$adm -C
# 在VIP列表中添加一条虚拟服务器记录,调度算法会轮询
$adm -A -t 192.168.12.111:80 -s rr
# 在前面添加的VIP记录上新增两条真实服务器记录,工作模式为DR
$adm -a -t 192.168.12.111:80 -r 192.168.12.130 -g
$adm -a -t 192.168.12.111:80 -r 192.168.12.131 -g
# 将配置好的规则保存在文件中
$adm -S > /etc/sysconfig/ipvsadm
# 开启路由转发功能
echo 1 > /proc/sys/net/ipv4/ip_forward
复制代码
④编写的脚本文件需要更改编码格式,并赋予执行权限,否则可能执行失败:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr.sh
:set fileformat=unix # 在vi命令里面执行,修改编码格式
:set ff # 查看修改后的编码格式
[root@localhost]# chmod +x /soft/scripts/lvs/lvs-dr.sh
复制代码
⑤执行lvs_dr.sh脚本并查看配置后的结果:
[root@localhost]# ./soft/scripts/lvs/lvs-dr.sh
[root@localhost]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.12.111:80 rr
-> 192.168.12.130:80 Route 1 0 0
-> 192.168.12.131:80 Route 1 0 0
复制代码
从上面的结果中可以看出,我们添加了一条192.168.12.111:80的VIP记录,采用的调度算法为RR轮询算法,并且在该VIP记录下还添加了两条真实服务器RIP记录。不过由于目前还未开始测试,因此后面LVS的统计信息都为0。
⑥配置第一台RS真实服务器:192.168.12.130,首先可以在上面安装Nginx:
可以通过yum install -y nginx在线安装。
也可以参考之前文章《Nginx-环境搭建》中的离线安装方式。
⑦为RS真实服务器绑定VIP(DR模式中的LVS、RS必须要求绑定同一个VIP),但需要注意的是:RS节点的VIP一定要绑在lo口上,不要绑在ens33、eth0等这类网卡上:
[root@localhost]# ip addr add dev lo 192.168.12.111/32
复制代码
⑧将RS节点上需执行的一些命令编写成lvs-dr-rs.sh脚本:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr_rs.sh
#!/bin/sh
# 改写一下Nginx的默认的index.html首页内容
echo "I is Real Server 001" > /soft/nginx/html/index.html
# 忽略ARP广播,保持ARP静默,确保请求VIP时,能够首先落入到LVS上
echo 1 >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo 1 >/proc/sys/net/ipv4/conf/all/arp_ignore
# 开启精确匹配IP回包机制,确保RS处理完请求后能够直接响应数据给客户端
echo 2 >/proc/sys/net/ipv4/conf/lo/arp_announce
echo 2 >/proc/sys/net/ipv4/conf/all/arp_announce
# 启动nginx(由于没做反向代理,也未更改配置文件,直接启动即可)
/soft/nginx/sbin/nginx
复制代码
然后重复上述过程,配置第二台RS节点,也可以直接克隆一次,但第二个RS节点上,稍微将上述脚本第一条指令中的I is Real Server 001改为I is Real Server 002,这样做的好处在于:待会儿测试的时候方便观察效果。
⑨为两个RS节点的脚本文件开放执行权限并执行:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr-rs.sh
:set fileformat=unix # 在vi命令里面执行,修改编码格式
:set ff # 查看修改后的编码格式
[root@localhost]# chmod +x /soft/scripts/lvs/lvs-dr-rs.sh
[root@localhost]# ./soft/scripts/lvs/lvs-dr-rs.sh
复制代码
⑩用一台新的机器充当客户端,测试LVS-DR模式的分发效果,可以在windows浏览器访问VIP测试,也可直接通过curl命令测试:
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
.......
复制代码
观察如上结果,很明显可看出LVS在根据我们配置好的RR轮询算法进行请求分发。
整个LVS-DR模式实验测试到此便告一段落了,但实际过程中一般很少用ipvsadm去操作LVS,因为这种方式步骤比较繁杂,并且没有健康检查机制,也就是说当某个RS节点宕机后,LVS依旧会为其分发请求。
正是由于不方便管理以及没有健康检查机制,因此实际情况下都是采用Keepalived去管理LVS的,其实Keepalived最开始就是为LVS专门研发的,用于快捷管理、确保高可用以及健康检查的工具。
3.4、结合Keepalived管理LVS
Keepalived在《Nginx-高可用》篇章中初次提到了它,我们使用它对Nginx实现了最基本的宕机重启以及VIP漂移的高可用机制,因此对于Keepalived基本概念与环境构建过程,在本文中则不再重复赘述,可直接参考之前的内容,在这里重点讲一下如何通过Keepalived管理LVS。
通过Keepalived管理LVS其实还是配置之前的keepalived.conf文件。
环境:四台Linux,其中两台作为RS,一台作为LVS主,另一台作为LVS从。
首先根据之前说过的Keepalived安装步骤,先在LVS主、从两台机器上安装Keepalived,然后开始配置keepalived.conf文件。
LVS主节点上的keepalived.conf文件:
# -------全局配置---------
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.129
}
# -------Keepalived自身实例配置---------
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state MASTER
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.129
# 节点权重优先级,主节点要比从节点优先级高
priority 100
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111/32
}
}
# -------LVS集群配置---------
# 配置一个虚拟服务器(VIP),可配置多个组成VIP集群
virtual_server 192.168.12.129 80 {
# 对每个RS健康检查的时间间隔
delay_loop 6
# 当前VIP所采用的分发调度算法:RR轮询
lb_algo rr
# 当前LVS采用的工作模式:DR直接路由
lb_kind DR
# 同一个客户端的请求在多少秒内都发往同一台RS服务器
persistence_timeout 50
# 当前LVS所采用的通信协议
protocol TCP
# 定义备用节点,当所有RS都故障时,用sorry_server来响应客户端
sorry_server 127.0.0.1 80
# 配置第一台RS真实服务器的信息
real_server 192.168.12.130 80 {
# 设定权重值,默认为1
weight 1
# 配置TCP信息
TCP_CHECK {
# 连接的端口号
connect_port 80
# 连接超时时间
connect_timeout 3
# 请求失败后的重试次数
nb_get_retry 3
# 重试的超时时间
delay_before_retry 3
}
}
# 配置第二台RS真实服务器的信息
real_server 192.168.12.131 80 {
# 设定权重值,默认为1
weight 1
# 配置TCP信息
TCP_CHECK {
# 连接的端口号
connect_port 80
# 连接超时时间
connect_timeout 3
# 请求失败后的重试次数
nb_get_retry 3
# 重试的超时时间
delay_before_retry 3
}
}
}
复制代码
观察上述配置文件,其实与之前的并未有太大区别,仅仅只是多增加了一个virtual_server模块,而后在内配置了LVS的规则,以及两个真实服务器节点real_server。当然,LVS作为整个系统请求分发的“咽喉要塞”,自然也要确保其高可用的特性,因此可再为其配置一台从机,确保当前机器发生意外不能正常工作时,依旧能够确保整个系统的可用性。
LVS从节点上的keepalived.conf文件:
# -------Keepalived全局配置---------
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.132
}
# -------Keepalived自身实例配置---------
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state BACKUP
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.132
# 节点权重优先级,主节点要比从节点优先级高
priority 90
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111/32
}
}
# -------LVS集群配置---------
# 配置一个虚拟服务器(VIP),可配置多个组成VIP集群
virtual_server 192.168.12.129 80 {
# 对每个RS健康检查的时间间隔
delay_loop 6
# 当前VIP所采用的分发调度算法:RR轮询
lb_algo rr
# 当前LVS采用的工作模式:DR直接路由
lb_kind DR
# 同一个客户端的请求在多少秒内都发往同一台RS服务器
persistence_timeout 50
# 当前LVS所采用的通信协议
protocol TCP
# 定义备用节点,当所有RS都故障时,用sorry_server来响应客户端
sorry_server 127.0.0.1 80
# 配置第一台RS真实服务器的信息
real_server 192.168.12.130 80 {
# 设定权重值,默认为1
weight 1
# 配置TCP信息
TCP_CHECK {
# 连接的端口号
connect_port 80
# 连接超时时间
connect_timeout 3
# 请求失败后的重试次数
nb_get_retry 3
# 重试的超时时间
delay_before_retry 3
}
}
# 配置第二台RS真实服务器的信息
real_server 192.168.12.131 80 {
# 设定权重值,默认为1
weight 1
# 配置TCP信息
TCP_CHECK {
# 连接的端口号
connect_port 80
# 连接超时时间
connect_timeout 3
# 请求失败后的重试次数
nb_get_retry 3
# 重试的超时时间
delay_before_retry 3
}
}
}
复制代码
两个RS节点还是按照之前的方式配置,然后分别启动LVS主、从机器上的keepalived服务以及RS节点上的Nginx服务,接着来测试结果看看:
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
.......
复制代码
测试结果与之前通过ipvsadm工具管理的LVS相同,而通过keepalived之后,所有配置可以统一化管理,同时还能对每个VIP下的真实服务器节点进行健康检测,并且还能对LVS实现高可用,因此实际生产环境中,当项目使用LVS时,一般都会采用keepalived管理。
当然,对于LVS的高可用特性、RS节点的健康检测机制,大家可以自行停掉对应的机器,然后测试观察结果(也包括其他的工作模式也可以自行测试,但一般最常用的就是DR模式)。
四、亿级吞吐第四战-Nginx与Gateway网关高可用
前面过程中简单的对LVS-DR模式进行了简单实验,其中我们通过Nginx作为WEB服务,但实际系统中,Nginx是提供反向代理的作用,它并不处理客户端的请求,最终的业务处理还是交由后端的Tomcat处理。
4.1、Nginx高可用设计
前面实验中基于LVS对Nginx实现了水平集群拓展,因此让整个系统拥有了更高的并发处理能力,而对于每个Nginx节点,也可以对其实现高可用,具体过程可参考:《全解Nginx篇-Keepalived实现Nginx高可用》。
相较而言,如果仅是为了容灾,都为每台Nginx配置一台备机,那么硬件成本会直线增高,因此通过Keepalived对Nginx实现宕机重启就够了,无需再为其实现VIP漂移,毕竟带来的收益远小于硬件成本,但如若系统要保障更高程度上的高可用,那么可以再为每个Nginx节点配置从机。
如若要保证更高的可用性,那依旧可以为每个Nginx节点配置从节点容灾。
4.1.1、为Nginx配置从机后的接入层架构
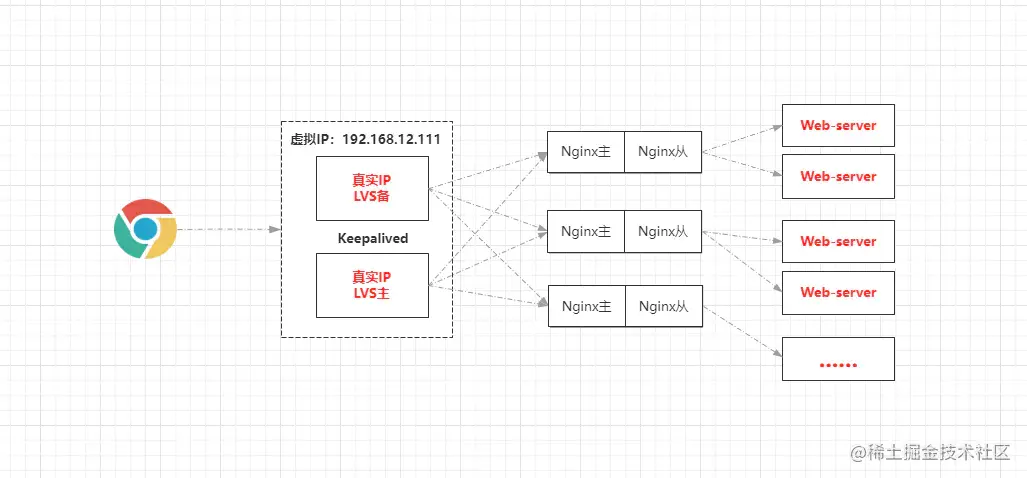
由于每个Nginx都配置了从机,因此每个Nginx节点都具备容灾能力,因此可以让每台Nginx负责不同WEB服务器的请求分发,这样做的好处在于:能够一定程度上提升些许性能。
4.1.2、不为Nginx配置从机的接入层架构
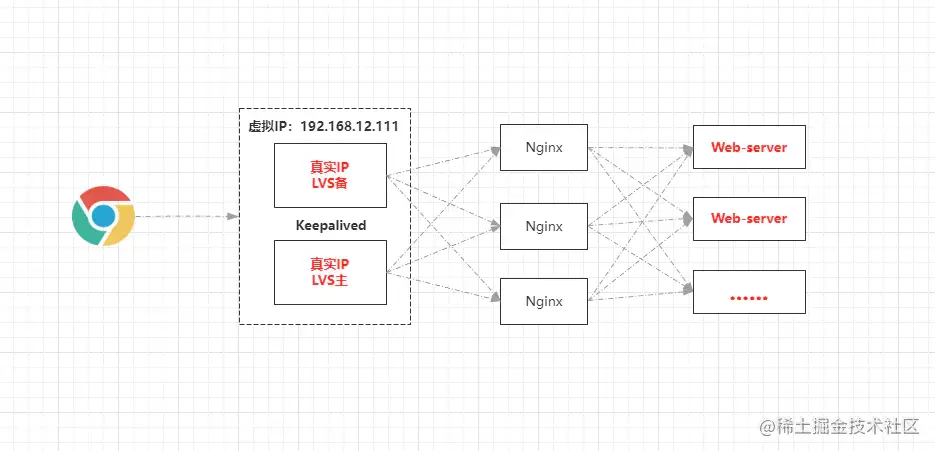
但如若不为Nginx配置从机,那每个Nginx节点的不具备很强的容灾能力,再通过上述的那种方式配置反向代理,就会存在问题,因为如果一个节点宕机,会导致该节点所代理的Web-server节点都不可用。
因此如果不给Nginx配置从机,那么可以将每个Nginx的反向代理,都配置成所有Web-sever的列表,这样就算一台Nginx节点宕机,也不会影响系统的正常运转。
4.2、Gateway网关高可用集群
前面Nginx负责代理的是普通Web-server,但大型网站必然会做业务切割,对于分布式/微服务架构而言,一般会划分出多个子服务,但服务太多不方便相互之间调用,并且也不方便对外提供,因此在微服务中都会存在一个服务网关,由网关统一对外提供接口,目前微服务架构中主流的网关技术是Gateway(在早期的SOA架构中是服务总线)。
因此对于分布式/微服务系统而言,Nginx代理的实则为网关节点,由于网关作为整个后端系统的流量入口,因此必须要保证其高可用,也就是说会对其做集群部署,也就是在多台服务器上部署网关(结构完全相同),然后Nginx的配置中,将upstream配置成每个Gateway节点的IP+Port即可,最终整个接入层的架构如下:
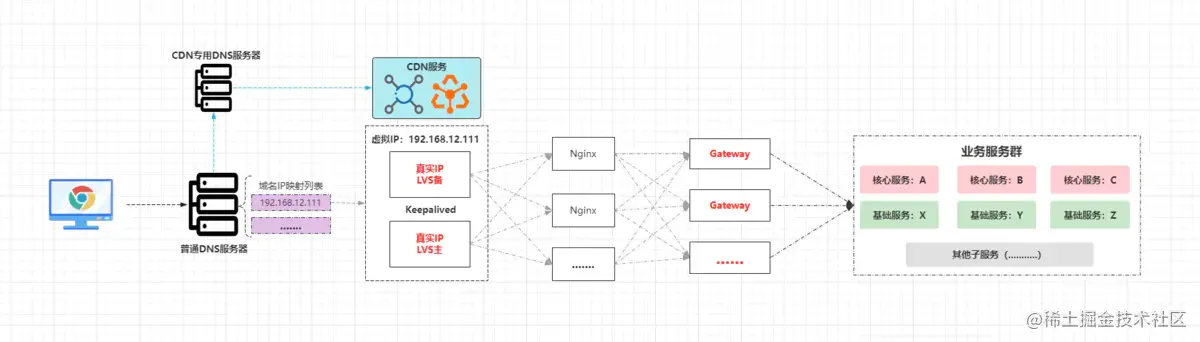
在这套架构中,CDN至少能够为系统分担一半的流量,而LVS作为接入层的“首个守关将”,它的并发性是极强的,几乎是Nginx的十倍以上,那假设此时LVS每秒的并发吞吐量为20W,为整个系统单日接入上亿、十忆、百亿流量都行。
五、千台实例构建日均百亿流量架构
这小节主要是为了拓展一下,类似于yy阶段,说简单一点就是让诸位在吹牛逼的时候多点谈资,不过在讲述之前,首先需要搞懂几个平台常用的数据指标:
- PV:平台页面被浏览/点击的总次数,每次访问或刷新都会计入一次PV。
- UV:一天内访问平台的总用户数(以客户端cookie作为计算依据)。
- IP:一天内访问平台的独立IP总数(以客户端IP地址作为计算依据)。
- QPS:平台一秒内接收到的请求总数。
- TPS:平台一秒内接收到的事务总数。
- RPS:平台每秒能够处理的请求总数(吞吐量)。
- RT:执行一个请求从访问到响应的总体时间。
- 最大并发数:平台能够在同一时刻同时处理的最大请求数。
- 单日流量:一天内平台收到的请求总数。
QPS、TPS的区别:TPS中的事务是指客户端请求、服务端处理、服务端响应 这个过程,一个事务是指客户端访问一次页面,但QPS是每次对服务器发起请求都会计入一次,而访问一个页面往往会产生多个请求,因此一个TPS中往往会包含多个QPS。
OK~,对于上述的些许指标有了简单了解后,接着来聊聊百亿架构的事情,在思考该问题之前,首先需要计算出一个关键指标:峰值QPS,因为峰值QPS代表着系统将面临的最高并发,峰值QPS计算公式如下:
峰值QPS = (单日流量 * 80%) / (60 * 60 * 24 * 20%)
由于每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间,因此只需要用单日流量去计算出这20%中的QPS,那么就能的到单日峰值QPS。
在有些地方并非用单日流量作为计算条件,而是单日的PV总值,但在咱们这里就用现有的百亿单日流量 作为计算的基础条件,如下:
(10000000000*0.8)/(60*60*24*0.2)≈462963
通过如上公式计算,可以得知大概的峰值QPS在46.3W左右。的到峰值QPS后,就可以根据该值计算出每个层面的服务节点大概数量了,但首先要根据峰值QPS计算出每个节点的单机QPS上限,以及峰值QPS情况下会造成的最大并发数:
①根据峰值QPS计算出系统流量的最大并发数:
计算公式:QPS / (一秒 / 平均响应时间)
假设此时系统中每个请求的平均响应时间为500ms,那么根据公式计算出系统在同一时间会出现流量的最大并发数:462963/(1/0.5)=231481.5。
②计算出每个层面单机QPS处理的上限值:
计算公式:节点最大并发数 * (一秒 / 请求处理时间)
假设一个节点处理每个请求的平均时间为200ms,最大并发数为800,那么该节点的单机QPS上限为4000。
得到了流量的最大并发数以及单机QPS上限后,那么就可以根据这两个值去计算每个层面需要的节点数量了,可以通过最大并发数计算,也可以通过单机的QPS上限计算:
- 通过最大并发数计算:节点数量 = 流量最大并发数 / 节点最大并发数。
- 通过单机QPS上限计算:节点数量 = 峰值QPS / 单机QPS上限。
通过第二种方式计算出来的节点数量是最准确的,毕竟每个层面处理请求的时间并不同,比如MySQL处理一个请求需要200ms,而redis可能只需10ms甚至更低,因但为了简单,咱们就通过第一种方式去计算每个层面的节点数量(毕竟只是模拟):
- 接入层: LVS一主一备(LVS-DR的最大连接数上限大概在30-50W) 但为了容错需要再搭建一个容灾集群,因此LVS共计四台。 Nginx(单节点并发连接数5W左右,线上做反向代理实际3W左右) 231481.5/30000≈8,Nginx大概需要8台。 Gateway网关由于不做具体的业务处理,默认最大连接数在1W左右 231481.5/10000≈24,Gateway网关大概需要24台左右。
- 系统服务层: SpringBoot内嵌的Tomcat:默认最大连接数也是1W,但由于要处理业务请求,因此线上能达到2000左右已算极致 231481.5/2000≈116,Tomcat大概需要116台左右。 还要考虑到微服务的生态圈,服务不可能单独部署,注册中心、服务保护、系统监控、定时调度、授权中心、CI/CD自动化等..... 因此系统服务层的完整构建,至少需要大概180+台左右的实例。
- 中间件层: 缓存中间件Redis,线上单机性能大概在5W左右的最大连接数。 231481.5/50000≈5,但由于缓存的特殊性,至少需部署20台以上。 分库分表中间件:8台左右。 ELK分布式日志收集10台左右。 Kafka、RabbitMQ消息中间件共计30台左右。 ElasticSearch搜索中间件共计30台左右。 ..........
- 存储层: Mongodb大概需要30台左右。 MySQL与Tomcat的数量大致对应,100台左右(有些库需要水平集群)。 大数据CDH全家桶50台以上。 FastDFS分布式文件存储共计20台左右。
- .......
其中除开Redis外,其他实例都可采用“一物理机四实例”的方式部署,但想要构建出整个完整的架构,估摸着需要几千台上万实例,大几百上千台物理机器。当然, 上述的节点数量并不作为生产环境下的的推荐,但计算方式是相同的,实际情况下可先计算出峰值QPS,然后再根据峰值QPS去与每个层面上的单机QPS上限做计算,从而得到准确的节点数量。
但实际情况下,还需要参考物理服务器的内存、CPU、磁盘的配置,还需要依据项目的业务类型、开发人员的技术水平去综合性考虑具体要使用多少个节点,因为性能好的超级服务器再加一定程度上的性能调优,能够极大程度上去节省服务器成本。