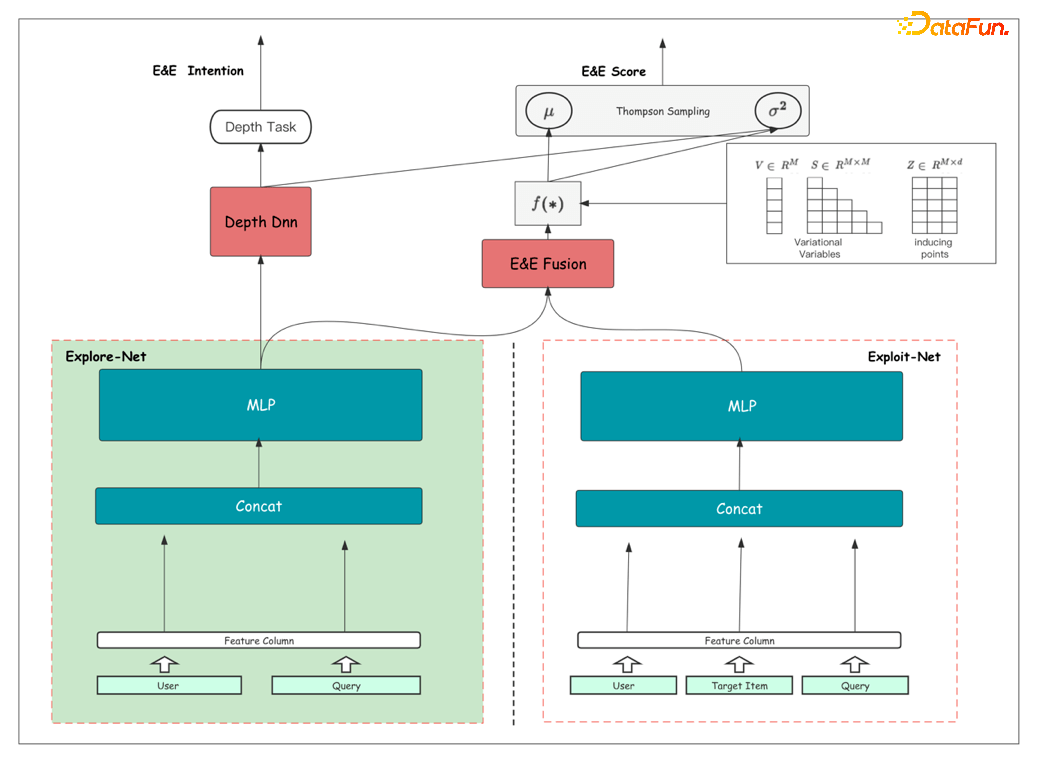
使用 *attr* DTO 为我们的 API 提供支持
帮助我们为全公司范围内的新 API 奠定基础是令人兴奋的。 2022 年初,我所在的团队为我们的新 API 开发了概念验证并建立了标准。 快进到今天,您会发现跨越 12 个产品领域的 150 多个端点每天处理数百万个请求。 在这篇文章中,我将深入探讨 API 的一个内部方面:数据传输对象 (DTO)。 我将讨论为什么我们选择 attrs 以及我们如何使用它。 我还将展示我们如何为开发人员标准化 API 实现流程,包括端点的版本控制。
API 工作非常艰巨,涉及多个工程和产品团队。 这需要讨论、技术设计文件,当然还有一些自行车脱落! 早期设计文档中的这句话捕捉到了这一愿景:
“Klaviyo 值得拥有一个长期、一致且灵活的 API,它可以在未来几年为 Klaviyo 内部和外部的开发人员提供服务,同时最大限度地减少我们内部开发人员的运营开销,并最大限度地提高我们外部开发人员的一致性和可用性。”
设置场景
我们的 API 符合 JSON:API 规范。 API 团队的 Chad Furman 写了一篇很棒的文章,介绍了我们为什么选择 JSON:API 以及我们如何使用它。 我们的实现是在 Python/ target=_blank class=infotextkey>Python 中使用 Django Rest Framework (DRF)。 我们利用 DRF 的可组合性和灵活性来定制 API 中的各种组件。
大致来说,实现如下:
API 路由注册在 Router 对象上,该对象将传入请求(正文、查询参数、标头等)分派到相应的 ViewSet 类。
通过在 ViewSet 类上配置自定义身份验证、许可和速率限制逻辑,将它们插入到 DRF 中。 这些由 DRF 在传入请求时调用。
ViewSet 类上实现的不同 HTTP 方法(GET、POST、PATCH 等)通过调用内部服务来处理传入请求。 这通常会通过适配器层来处理各个方向的有效负载,最终返回 HTTP 响应。
使用数据传输对象 (DTO)
在 Python 中,使用普通的旧字典很容易表示键值数据(例如 JSON 有效负载),但这种便利性可能会代价高昂:
缺乏结构:词典松散。 它们的外观没有界限。 很容易犯错别字、数值多余、数值不足等错误。
可变性:Python 中的字典是可变的,如果您使用该语言一段时间,您已经知道这可能会导致各种令人讨厌的错误。
从根本上讲,DTO 是仅封装数据的对象——它们内部几乎没有行为(最多是序列化逻辑)。 这些也称为纯数据类或数据类。 此类(或一般类)在实例化期间强制执行严格的模式。 也可以轻松地实现这些来实例化不可变对象。 另外,正如我们稍后将看到的,DTO 允许向属性添加类型提示,这极大地提高了代码的可读性。
我们使用 DTO 来代表我们的 API 合约。 每个端点(HTTP 方法)都有一个关联的入口 DTO(表示传入请求的 JSON 正文以及查询参数)和一个相关的响应 DTO(表示返回到客户端的 JSON 正文)。 例如,当使用我们的 API 创建目录项时,请求和响应数据字典将被建模为 DTO。
我们不鼓励使用可以跨多个端点重用的通用、稀疏实例化的 DTO。 尽管这增加了一些冗余,但它提供了清晰、严格的模式实施,并且还产生了模块化设计,可以轻松独立地对不同端点的合约进行版本控制。 此外,这种独特的 DTO 端点绑定有助于简化公共 API 文档的自动生成。
当时,一些库已经提供了创建纯数据类的出色解决方案,而开发人员无需编写标准 Python 类通常所需的样板代码。 最流行的是:dataclasses、pydantic 和 attrs。 我不会详细比较这三者,因为有很多文章(请参阅 Attrs、Dataclasses 和 Pydantic 以及为什么我使用 attrs 而不是 pydantic)。
在较高的层面上,第一个决定是在 attrs/dataclasses 和 pydantic 之间。 前两个与 pydantic 相似但又截然不同。 Pydantic 主要是一个验证库而不是数据容器。 尽管在这里使用 pydantic 很诱人,因为它适合我们的用例,但我们主要出于性能原因决定不使用它。 我们的 DTO 需要在每个 API 请求的 API Web 层上同步实例化,因此每个潜在的性能瓶颈都很重要。 这篇博文对这些库的性能进行了一些有趣的研究和基准测试。
我们选择了 attrs,因为它高性能、功能丰富(与数据类相比)、灵活且易于使用。 另外,由于 attrs 不是标准库的一部分(与数据类不同),合并新功能不需要 Python 版本升级。 就我个人而言,我真的很喜欢他们的装饰器风格模式,而不是 pydantic 使用的继承。 他们在哲学上更倾向于组合而不是继承,这使得组合更加透明并且易于针对我们的用例进行定制。 attrs 将方法附加到类上,一旦类生成装饰器执行,它就是一个普通的旧 Python 类。
“它在运行时不执行任何动态操作,因此运行时开销为零。 这仍然是你的Class。 ” — attrs 文档
Klaviyo API DTO
一般来说,在合理的情况下包装第三方库被认为是良好的做法。 首先,它有助于统一使用,例如具有许多选项的库的所需设置和默认设置。 其次,它创建了一个应用普遍变革的中心点。 第三,它提供了抽象库细节的机会,从而提供了将其替换为替代方案的灵活性,在这种情况下,包装器充当适配器。 出于所有这些原因,我们将 attrs 包装在为开发人员提供的工具中。
在揭开该工具之前,让我们看一个简单的示例。 想象一下图书馆中有一个用于图书的简单 API。 此 API 的用户希望使用搜索参数来查询图书。 以下是我们的一位开发人员如何编写 API 的查询请求 DTO:
from App.views.apis.v3.dtos import api_dto, field
from app.views.apis.v3.validation import common_validators
@api_dto(ApiResourceEnum.BOOK, enable_boolean_filters=True)
class BookQueryDTO:
id: str | None = None
title: str | None = field(
default=None,
external_desc="Title of the book you are querying for",
example="Harry Potter and The Sorcerer's Stone",
filter_operators={FilterOperators.CONTAINS, FilterOperators.EQUALS},
validator=common_validators.max_len(100)
sortable=True
)
author_id: str | None = field(
default=None,
filter_operators={FilterOperators.EQUALS},
)
page_cursor: str | None = None
return_fields: list[str] | None = None
sort: str | None = None
上面的示例将我们将在接下来的部分中讨论的几个重要部分结合在一起:
@api_dto 装饰器
attrs 字段包装器
用于请求验证的 common_validators 模块
我们的 @api_dto 装饰器:包装 attrs @define
我们的 @api_dto 装饰器是用如下代码实现的:
from attrs import define, resolve_types
def api_dto(
resource: ApiResource,
enable_boolean_filters: bool = False,
non_dto_sort_fields: list | None = None,
min_max_page_size: tuple[int | None, int | None] | None = None,
) -> Callable:
# ...
# Arg validation
# ...
def inner(py_dto_cls: type) -> ApiDtoClass:
generated_attr_dto = resolve_types(
define(frozen=True, kw_only=True, auto_attribs=True)(py_dto_cls)
)
setattr(generated_attr_dto, "__api_dto__", True)
setattr(generated_attr_dto, "__resource__", resource)
setattr(generated_attr_dto, "__boolean_filters_enabled__", enable_boolean_filters)
if non_dto_sort_fields:
setattr(generated_attr_dto, "__non_dto_sort_fields__", non_dto_sort_fields)
if min_max_page_size:
setattr(generated_attr_dto, "__min_max_page_size__", min_max_page_size)
# ...
# More Validation to ensure proper setup
# ...
return generated_attr_dto
return inner
它将 attrs 定义装饰器应用到传入的类,并具有预定的配置:
freeze=True 这些 DTO 应被冻结,以在 API 请求中的整个生命周期中强制执行不变性。 这也使得对象可散列,这有利于缓存请求和响应。
kw_only=True 由于这些 DTO 可能具有多个属性,因此为了清楚起见,必须仅使用关键字参数来实例化这些属性。
auto_attribs=True 这是 attrs 的一个很好的功能,它避免了将每个属性分配给字段的需要。 它还强制执行类型注释。
这里一个更重要的细节是,define 装饰器默认生成一个开槽类 (slots=True),因此这些 DTO 的内存占用较小,这是有助于扩展的又一个因素。
尽管 attrs 在定义装饰器中还有其他几个参数,但到目前为止我们的 API DTO 还不需要它们,而且我们的包装器使我们的内部开发人员不必考虑它们。
最后,我们在这个修饰类上解析_types(),以允许前向引用的字符串类型提示。 这可确保定义每个属性的类型并准备好用于序列化/反序列化。
您可能已经注意到,生成此类对象后,接下来的几行会在类(而不是实例)上设置一些属性值:
__resource__ 属性引用 ApiResource 对象。该对象存储此 DTO 建模的资源的类型等。 然后由序列化和文档工具使用。 每个域都有一个枚举来保存其所有 ApiResource 对象。 然后在装饰器上提供枚举,例如 ApiResourceEnum.BOOK。
__api_dto__ 是一个标志,指示此类是使用此装饰器生成的。 这充当在 DTO 注册表期间进行验证的水印,以确保所有 API DTO 都是从此装饰器生成的。
__boolean_filters_enabled__ 属性是一个开关,允许使用 AND / OR / NOT 布尔运算符过滤 DTO 中的字段。
__non_dto_sort_fields__ 和 __min_max_page_size__ 帮助解析和处理此 DTO 的请求查询参数。
我们的 API DTO 字段:包装 attrs 字段
attrs 允许将元数据附加到属性,事实证明,这非常漂亮! 我们用它来存储 API 不同部分使用的属性信息:文档、过滤、编辑等。
我们没有依赖开发人员在这个字典中自由设置值,而是在 attrs 字段函数周围添加了一个简单的包装器。 该包装器提供了一个一致的接口,用于设置其他关键字参数,如filter_operators、sortable、external_desc 等(见下文)。 这是代表我们的字段包装器的片段:
from attrs import field as attrs_field
def field(
*args,
filter_operators: set[FilterOperators] | None = None,
non_filterable: bool = False,
sortable: bool = False,
accept_multiple_query_param: bool = False,
external_desc: str | None = None,
example: Any | None = None,
data_classification: DataClassification = DataClassification.DEFAULT,
meta: bool = False,
**kwargs,
):
# ...
# Parse and validate args
# ...
# ...
# Construct field metadata in a standardized fashion (fixed keys, internal to API machinery)
# eg. metadata["__external_desc__"] = external_desc
# ...
return attrs_field(*args, **kwargs, metadata=(metadata or None))
这以可预测、干净且稳健的方式构建元数据。 该包装器中有一些有趣的参数:
filter_operators 用于在 API 请求中指定该字段可能的过滤运算符。 我们有自己的过滤语法(使用 pyparsing 实现),可以解析 JSON API 过滤器并使用此处指定的运算符验证请求。 这个 kwarg 只是冰山一角,我认为我们的 API 过滤语法值得单独写一篇文章。
external_desc 和 example 字段由生成 OpenAPI 规范文档的内部工具使用。 这通过 DTO 代码更改(我们的 API 合约)简化了文档更新。 开发人员只需使用此 kwarg 在 DTO 字段上配置新信息,文档就会使用该信息进行更新!
验证工具箱

如前所述,我们使用 DTO 来表示请求中的 JSON 正文。 我们添加了一个层,即使在无效负载进入内部服务边界之前,它也会给我们带来拒绝无效负载的温暖模糊感觉!
此验证将在 API Web 服务器上同步进行,因此,我们需要谨慎对待这些 DTO 的验证范围。 例如,我们不想在这里进行数据库调用; 这将发生在内部服务边界。 我们的想法是进行轻量级验证,足以拒绝不必要地使用堆栈更深层次资源的不良有效负载。
attrs 通过将验证器函数指定为字段上的 kwarg,可以轻松验证这些数据类。 这些验证器在对象实例化时运行(在本例中将原始 JSON 反序列化为请求 DTO)。 我们的内部开发人员可以访问这些验证器的精益包装器,以生成一致的错误消息。 使用装饰器来定义错误消息,我们现在可以中继回状态为 400 的 HTTP 响应。 通常,我们会对代表请求的 DTO 添加严格的验证,而不是对响应的 DTO 进行太多验证。 这是因为我们可以控制后者的生成,并且可以使用自动化测试来确保正确性。
我们的 API 代码库中的 Python 模块封装了可供所有团队使用的通用 DTO 验证器。 在这些验证器中,许多只是 attrs 验证器的包装器,而其他验证器则是在这些验证器的基础上构建的。 它们构成了实现 DTO 时使用的工具箱。 许多团队最终编写了自己的验证器模块,特定于他们的领域,并基于这些基本验证器构建。 如果验证器足够通用,足以对其他团队有用,那么它就会进入基本验证器模块。
我们还有一个模块,用于维护生成验证器函数的 Python 闭包。 这里的想法是,有时不同的团队可能最终会实现具有相同验证逻辑的类似验证器,只是不同的“参数”。 拥有这个模块有助于消除冗余。 此闭包的一个简单示例如下所示:
def divisible_by__validator_closure(divisor: int) -> Callable:
if not isinstance(divisor, int):
raise ValueError(f"divisor must be of type int, got {type(divisor)}")
if divisor == 0:
raise ZeroDivisionError("Cannot use 0 as a divisor")
@api_custom_validator
def generated_validator_fn(instance, attribute, value):
if value % divisor != 0:
raise ValueError(f"{value=} is not divisible by {divisor=}")
return generated_validator_fn
# Example use:
# divisible_by_two_validator = divisible_by__validator_closure(2)
这总结了(抱歉,我无法抗拒)如何为 Klaviyo 的 API 创建 DTO。 JSON:API 关系也在这些 DTO 中建模,但为了简洁起见,我们不会在本文中介绍它们。
DTO 和 ViewSet 元编程的注册表
到目前为止,在这篇文章中,我们揭示了 DTO 在 API 中代表什么以及它们是如何以标准化方式创建的。 但是,每个版本的 API 端点如何知道要使用哪个 DTO? 此外,一旦解决了这个问题,入站原始 JSON 如何转换为该 DTO(其他方向也类似)?
为了回答这些问题,让我们了解 ViewSet 类是如何实现和版本控制的。 使用上面的 Books API 示例,Klaviyo API ViewSet 如下所示:
class BooksViewSet(BaseApiViewSet):
@api_revision(
"2020-01-01",
ingress_dto_type=BooksListQuery,
egress_dto_type=BooksResponse,
)
def list(self, request: Request, request_dto: API_DTO) -> JsonApiResponse:
...
@api_revision(
"2023-06-01",
ingress_dto_type=BooksListQuery,
egress_dto_type=BooksResponse,
)
def list(self, request: Request, request_dto: API_DTO) -> JsonApiResponse:
...
@api_revision(
"2020-05-05",
auto_deprecate=False,
ingress_dto_type=BookCreateQuery,
egress_dto_type=BookResponse,
)
def create(self, request, request_dto: API_DTO) -> JsonApiResponse:
...
上面的示例中发生了一些有趣的事情,我们将看看它是如何在幕后引导的(包括使同一个类中可以具有相同名称的方法而无需任何真正的重载的魔力) )。
准备 Klaviyo API ViewSet 类大致分为三个步骤:
@api_revision 装饰器将所有 ViewSet 的所有方法的全局注册表填充到特定修订版,并按类名键入。 例如:
{
"BooksViewSet": {
"list": [Revision(...), Revision(...)],
"create": [Revision(...)],
},
"FooViewSet": {
"list": [Revision(...), Revision(...), Revision(...)],
"create": [Revision(...)],
"retrieve": [Revision(...), Revision(...)],
"update": [Revision(...)],
"partial_update": [Revision(...)],
"destroy": [Revision(...)],
},
"BarViewSet": {...}
}
上面注册表中的 Revision 对象是简单的数据类:
@dataclass
class Revision:
"""A single API method revision's information, defaults are set in the api_revision decorator"""
revision_date: str
func: Callable
auto_deprecate: bool
deprecation_date: str
removal_date: str
ingress_dto_cls: Type[API_DTO]
egress_dto_cls: Type[API_DTO] = None
这意味着每个方法修订版都有一个与其绑定的 DTO,并存储在该全局注册表中。
2. BaseApiViewSet 是使用 ApiV3Metaclass 元类构建的。 元类读取此全局注册表,并将方法名称的映射附加到所有端点修订版,作为相应 ViewSet 上的类属性。
元类大致如下所示:
class ApiV3Metaclass(type):
def __new__(mcs, class_name, bases, attrs):
# attributes to attach to the class
attrs_to_build = dict()
# collection of our api methods and revisions, we want to structure this data
# to make incoming requests as fast as possible to route at runtime
# { method_name -> [Revision(...), Revision(...), ...] }
revision_list_by_viewset_method = defaultdict(list)
# Create the revision methods on the class based on the revision fed into the
# @api_revision decorator
for (
viewset_method_name,
revisions,
) in _funcs_and_revisions_by_class_and_method[class_name].items():
revision_list_by_viewset_method[viewset_method_name] = sorted(
revisions,
key=lambda revision: RevisionDate(revision.revision_date),
reverse=True,
)
attrs_to_build["revisions_by_method"] = revision_list_by_viewset_method
# ...
# More setup
# ...
return super(APIV3Metaclass, mcs).__new__(
mcs, class_name, bases, attrs_to_build
)
每个视图集都有一个 revisions_by_method 属性,如下所示:
{
"list": [Revision(...), Revision(...), Revision(...)],
"create": [Revision(...)],
"retrieve": [Revision(...), Revision(...)],
"update": [Revision(...)],
"partial_update": [Revision(...)],
"destroy": [Revision(...)],
}
有一个有趣的 Python 解释器细节,它使装饰器与元类无缝工作,从而使此设置成为可能:
在Python中,类主体在使用确定的元类设置类之前执行。 这里有关于这个过程的更多细节,但对于我们的场景来说,这意味着装饰器首先执行(填充全局注册表),然后执行元类 __new__ 方法,该方法使用此全局注册表创建一个类属性,该属性存储修订 方法。
修饰方法从未真正附加到类,而仅作为 Revision 对象中的引用存在。 这就是为什么可以有同名的方法!
3. 基础方法(来自BaseApiViewSet)根据版本头查找要调用的方法
BaseApiViewset 类包含所有 ViewSet 操作方法(列表、创建、检索等)的简单实现。 这个简单的部分实际上是将所有这些组合在一起的:
(回顾)路由器将请求分派到相应的 ViewSet 类。 由于装饰方法从未附加,因此存在的这些方法的唯一实现来自基本方法,该方法在此处被调用。
基本方法解析请求标头以获取所请求端点的修订日期。 它从 ViewSet 类上的 revisions_by_method 查找中获取特定的 Revision 对象。 回想一下,此 Revision 对象保存对端点特定版本的 DTO 和函数引用。
最后,序列化器将 JSON 构建到绑定到该修订版的 DTO 中,并将其传递给函数,执行该函数并将响应序列化回 JSON!
所有 API ViewSet 都继承自 BaseApiViewset 并使用此机制工作。
序列化
我们的 API 使用 cattrs 来完成与 JSON 的序列化/反序列化。 这是一个方便的 Python 库,可以帮助构建非结构化数据(如字典),反之亦然。 该库功能强大,提供多种可能的转换。 (尽管这听起来似乎没什么大不了的,但我认为将原始值转换为枚举的能力非常方便且非常简洁。)
cattrs 与 attrs 集成得很好,这使得它成为我们 API 的一个简单选择。 我还喜欢使用 ExceptionGroups 在 cattrs 中进行异常处理:它在序列化器层中很有用,我们需要精确地(外部或内部)查明 DTO 未能创建的位置及其原因。
cattrs 的使用是 API 系统内部的。 我们有一个特定的 APIConverter 类,其中注册了一些默认挂钩,还有一个注册表,其他团队可以在其中帮助处理特定的罕见边缘情况。 默认钩子的用途不仅仅是提供各种转换。 在某些情况下,此处注册的挂钩可以充当特定类型的全局验证器。 例如,日期和日期时间类型可以接受各种格式,并且此转换器负责验证这些格式(而不是每个 DTO 都必须验证它),并在出现问题时引发验证错误。
总的来说,我们对cattrs有一个普通的用法,并且事实证明它是有效的。
结论
我所描述的摘要:
我们的 API 使用 DTO 表示请求正文、查询参数和响应。
我们包装了 attrs 来简化和标准化开发人员的使用。
我们采用装饰器和元类等 Python 模式来大规模简化实现、对 API 进行版本控制,并将 DTO 绑定到端点版本。
用 cattrs 补充 attrs 简化了 DTO 的序列化和反序列化。
我们对 2022 年初做出的决定感到满意。与每个端点直接接受和生成 JSON 或字典相比,我们基于 DTO 的方法有助于实现上面提到的愿景:
“Klaviyo 值得拥有一个长期、一致且灵活的 API,它可以在未来几年为 Klaviyo 内部和外部的开发人员提供服务,同时最大限度地减少我们内部开发人员的运营开销,并最大限度地提高我们外部开发人员的一致性和可用性。”