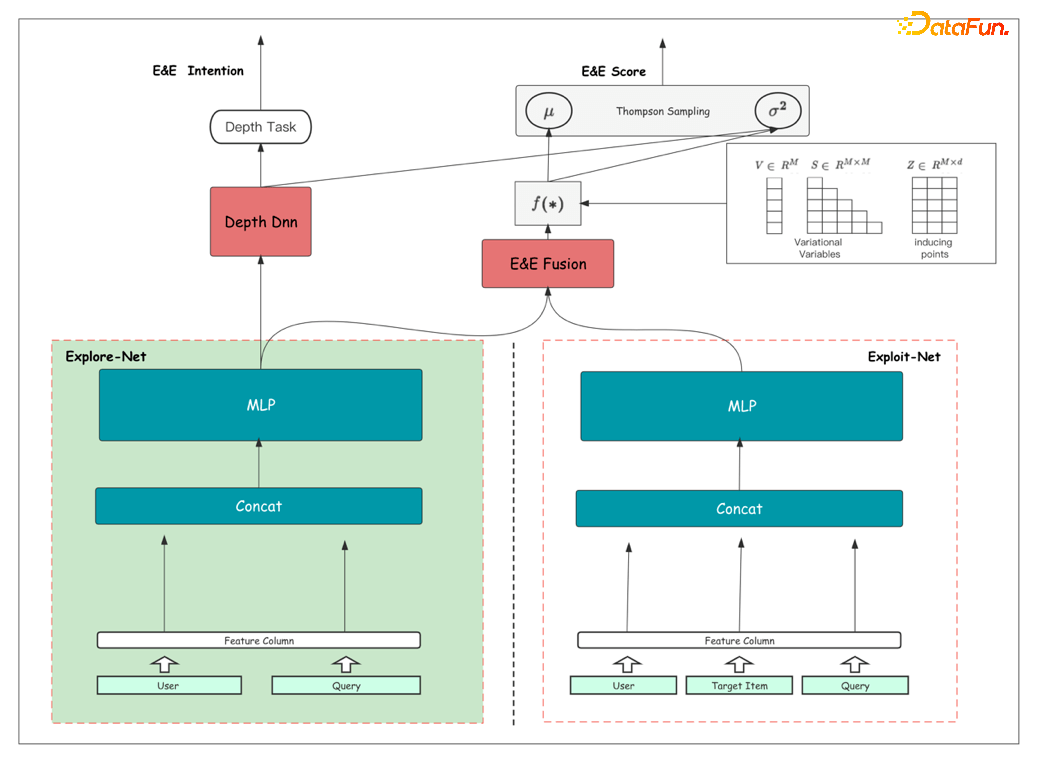
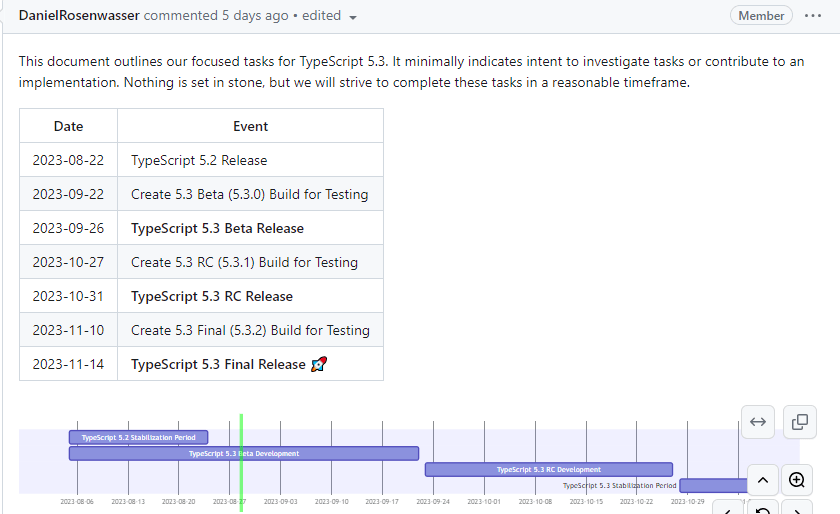
10倍提升API性能的8种方式
提起API,作为程序员来说并不陌生,很多程序员的大部分工作都是围绕着它, 然而很容易被大家忽略,API的性能会直接影响产品的用户体验,比如,一个视频软件,播放1s后需要加载5s,还有人会用它吗?API背后隐藏了很多复杂的业务逻辑,如何保证API的性能,直接体现了一个程序员的综合能力。今天我们就来聊聊8种提升API性能的常用方法。本文首发

一、什么是API?
在讲解方法之前,先对API做个简单的介绍。API,Application Programming Interface,翻译为:应用程序接口,它是一种允许两个软件组件使用一组定义和协议相互通信的机制。比如,手机上的天气预报软件,它通过 API 与远程气象系统“交互”,获取天气相关数据,最后再将数据展示在手机上。如下图:软件A通过API与软件B进行交互

二、API性能提升方法
1. 缓存
缓存,应该是最容易被大家使用,提升API性能的方法,如下图:

在日常的业务开发中,通常会包含对数据库的CRUD,但是数据库的读写性能是有限的,比如在一些场景中,需要对某些数据进行频繁的读取,这时候,可以考虑将这些数据缓存起来,下次读取时,直接从缓存中读取,减少对数据库的访问,提升API性能。举个例子:假如访问 DB的耗时是 100ms,访问缓存的耗时是10ms,那么整个API的性能就提升 10倍。常用的缓存工具有 redis 和 google Guava cache(本地缓存)。
可能有些小伙伴会问:一个 API的响应数据,100ms 和 10ms 对于用户来说,似乎没有很大的差异?
假如把时间放大 10倍,100倍,就能发现,这个差异非常明显,比如,一个 API的响应时间是 10s, 如果能够通过缓存将响应时间降低到 1ms,那么整个系统的吞吐量就提升了 10倍,性能提升相当可观,对于用户的体验来说也是天壤之别。
2. 连接池
连接池,是一种数据库连接管理技术,它可以在系统初始化时,创建一定数量的数据库连接,当有请求时,直接从连接池中获取连接,使用完毕后 ,再将连接放回连接池中,这样就可以避免频繁的创建和销毁数据库连接,提升API的性能。如下图:

服务器和数据库建立连接是基于 TCP协议,而TCP 需要3次握手,这个过程比较耗时,如果每次请求都需要创建一个连接,那么就会频繁的进行3次握手,从而影响 API的性能。所以在日常开发中,和数据库连接时,通常都会使用一些三方的池化工具,以达到复用连接的目的。常用的池化工具有:JDBC,HikariCP,Druid,C3P0,DBCP,BoneCP等。
3. 异步
异步,是一种编程模型,它可以在一个线程中执行多个任务,如下图:

在日常的业务开发中,通常包含核心链路和非核心链路,比如:订单支付中,支付是核心链路,支付后邮件通知是非核心链路,因此,可以把这些非核心链路的操作,改成异步实现,这样就可以提升API的性能。常用的异步方式有:线程池,消息队列,事件总线等。比如:上面的邮件发送,当用户支付完之后,可以使用线程池去实现邮件发送,也可以往消息队列中发送一条消息,由消费服务去消费,实现邮件发送。
4. N + 1问题
“N+1 问题” 是一个在数据库查询性能优化领域常见的概念,指的是在进行关联查询时,当你需要获取主表中的 N 条记录以及每条记录关联的另一个表中的相关信息时,会导致在获取相关信息时产生额外的查询操作,从而造成额外的负担和性能问题。如下图:

举个例子:假如有两张表,文章 “post”表 和文章评论”comment”表,现在要统计每篇文章的评论数,通常SQL语句写法如下:
sql复制代码SELECT id FROM post; // 1
//for each post
SELECT count(*) FROM comment WHERE post_id = ? // N
如上文的例子,查询 1次 post表,假如 post中有 N条数据,这样就需要额外查询 N次 comment表,因此,产生了 N + 1次查询。
解决”N+1 问题”的通常方法为:使用 JOIN 进行关联查询,如下SQL:
sql复制代码SELECT post.id, count(comment.id) FROM post
LEFT JOIN comment ON post.id = comment.post_id GROUP BY post.id;
但是,在一些分库分表的情况下,无法进行 JOIN查询,该如何解决这种 N+1问题?
通常的做法有:数据冗余,说白了就是空间换时间。比如:在 post表中,增加一个 comment_count字段,用于存储评论数,这样就可以避免 N+1问题,但是会造成数据冗余,增加了存储空间。
因此,在程序员的世界,很多时候都是在时间和空间上的权衡(trade off)。
5. 分页
分页(Pagination),是一种常见的数据查询方式,它可以将大量的数据,分成多个页面进行展示,如下图:

分页也是业务开发中比较常见的一种方式,当数据量比较大时,通常会使用分页的方式进行查询,这样可以避免一次性查询大量的数据,造成内存溢出的问题。
6. JSON 序列化
JSON(JAVAScript Object Notation)序列化是将数据结构或对象转换为JSON格式的字符串的过程,以便在网络传输、存储或与其他程序交互时进行数据交换。JSON是一种轻量级的数据交换格式,易于人类阅读和编写,同时也易于解析和生成。在各种编程语言中,可以使用库或内置函数来进行JSON序列化和反序列化操作。如下图:

7. 压缩 payload
在API开发中有个默认的约定:参数要尽量的少。因为参数越多,API的复杂度就越高,维护成本也就越高。因此,通常我们会对参数进行压缩。如下图:

比如:上传文件,通常会对文件进行压缩,以减少文件的大小,提升上传速度。
8. 精简Log或者异步log
在业务流程中,通常会增加 log来标记一些核心的流程,以及记录错误信息,方便排查问题。但是,log通常是磁盘操作,如果log过多,就会影响API的性能。因此,通常会对log进行精简,或者异步log。如下图:

异步日志(Asynchronous Logging)是一种在计算机程序中进行日志记录的技术。与传统的同步日志记录不同,异步日志记录允许程序在记录日志时不必等待日志写入磁盘或其他存储介质完成,而是将日志数据放入队列或缓冲区中,然后由另一个线程或进程负责将日志异步地写入存储介质。异步日志记录通常会涉及以下一些组件:
- 日志缓冲区或队列:程序将要记录的日志信息放入缓冲区或队列中,然后可以继续执行其他任务。
- 日志写入线程:另一个线程负责从缓冲区或队列中获取日志数据,并将其写入实际的存储介质(如磁盘)中。这个过程是异步的,不会阻塞主程序的执行。
- 同步机制:由于异步操作涉及多线程,可能需要适当的同步机制来确保线程之间的安全性,避免竞态条件等问题。
异步日志的优点可以减少主程序的延迟和性能损失的同时,提升性能。需要注意的是,在实现异步日志时,要小心处理缓冲区溢出、数据丢失以及确保正确的日志顺序等问题。
三、总结
本文分别了介绍了API的性能优化方案,包括:
- 缓存
- 连接池
- 异步
- N+1问题
- 分页
- JSON序列化
- 压缩payload
- 精简log等
当然,这些方案并不是一定要使用,而是根据实际的业务场景,具体问题具体分析,选择合适的方案。
另外,在API的开发中我们通常需要关注三个最常见的问题:
- 性能
- 安全性
- 健壮性