如何应对高并发的用户请求
互联网发展至今,各种互联网应用以及云计算的普及,使得架构设计和软件技术的关注点从如何实现复杂的业务逻辑(复杂的CRUD),转变为如何满足大量用户的高并发访问请求。
举个例子:比如一个简单的计算处理过程,如果一旦面对大量的用户访问,整个技术挑战就会变得完全不同,软件开发方法、技术团队组织、软件的过程管理都会完全不同。
新浪微博刚开始只有两个开发,一个前端一个后端,他们两个人一周就把新浪微博开发出来了,但这是都十几年前的事情了。现在新浪微博的技术团队有上千人,这些人要应对的挑战主要有两个方面:一是复杂的功能,二是用户量增加带来的高并发访问压力。
这种挑战和压力几乎是每个大型互联网公司都要面对的。一个应用给几个人用和给几亿人用是完全不同的。当用户不断增加的时候,需要消耗的计算资源也会不断增加,需要更多的CPU和内存去处理用户的计算请求,更多的网络带宽去传输用户的数据,以及磁盘空间存储用户数据。当消耗的资源超过了服务器资源的极限时,服务器就会崩溃,整个系统就无法使用了。
那么我们应该如何解决高并发的用户请求带来的问题?
一、垂直伸缩与水平伸缩
为了应对高并发用户访问带来的系统资源消耗,一种解决办法是垂直伸缩。所谓的垂直伸缩就是提升单台服务器的处理能力,花钱买更高配置的服务器来应对不断增加的请求量。
在大型的互联网出现之前,传统的行业,比如银行、电信这些企业的软件系统,主要是使用垂直伸缩这种手段实现系统能力的提升。但是随着用户数量的提升,就需要不断的去换配置更高的服务器,价格成本也越来越高,而且单台服务器的配置是有上限的,以目前的互联网发展状态来说,这种方式显然是不合适的,一般都采用水平伸缩。
所谓水平伸缩,就是通过多台计算机构成集群,通过这个集群对外统一提供服务,以此来提高系统的整体处理能力。这种方式是目前普遍采用的分布式架构方案。
二、互联网分布式架构演变
分布式架构是互联网企业在业务快速发展过程中,逐渐发展起来的一种技术架构,包括了一系列的分布式技术方案:分布式缓存、负载均衡、反向代理与 CDN、分布式消息队列、分布式数据库、NoSQL 数据库、分布式文件、搜索引擎、微服务等等,还有将这些分布式技术整合起来的分布式架构方案。
这些分布式技术和架构方案是互联网应用随着用户的不断增长,为了满足高并发用户访问不断增长的计算和存储需求,逐渐演化出来的。可以说,几乎所有这些技术都是由应用需求直接驱动产生的。
下面我们通过一个典型的互联网应用的发展历史,来看互联网系统是如何一步一步逐渐演化出各种分布式技术,并构成一个复杂庞大的分布式系统的。
发展初期:单机部署
在最早的时候,系统因为用户量比较少,可能只有几个用户,比如刚才提到的微博。一个应用访问自己服务器上的数据库,访问自己服务器的文件系统,构成了一个单机系统,这个系统就可以满足少量用户使用了。
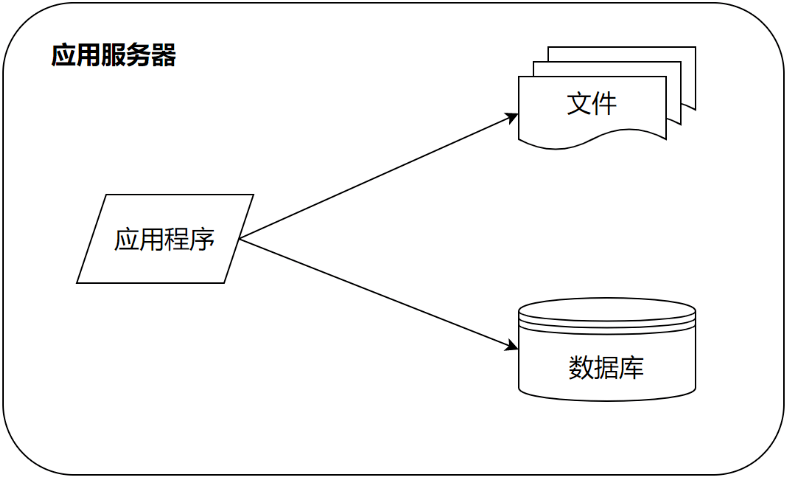
首次分离:数据库与应用独立部署
如果这个系统在业务上比较有价值,那么用户就会快速增长。比如像新浪微博引入了一些明星大V开通微博,于是迅速吸引了这些明星们的大批粉丝前来关注。这个时候服务器就不能承受访问压力了,需要进行第一次升级,数据库与应用分离。
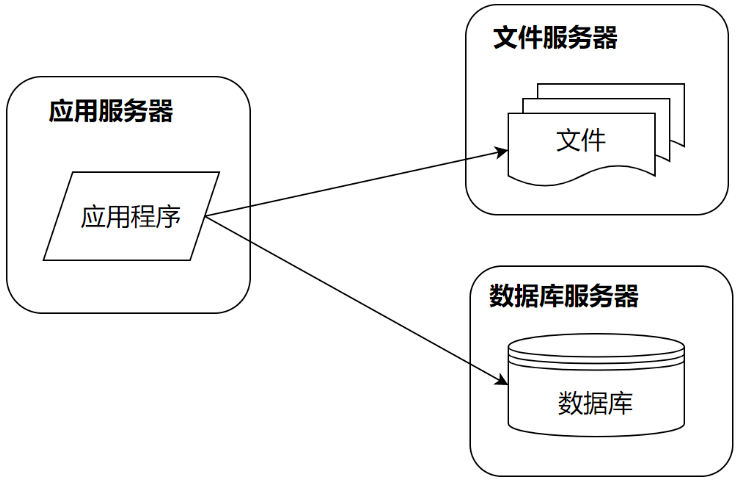
前面单机部署的时候,数据库和应用程序是部署在一起的。进行第一次分离的时候,应用程序、数据库、文件系统分别部署在不同服务器上,从1台服务器变成了3台服务器,相应的处理能力也比之前的单机部署模式要高很多。这种分离基本上不需要花费什么技术成本,只需要把数据库,文件服务器进行远程部署,然后改下相应配置即可。
缓存登场:为数据库遮风挡雨
而随着用户进一步增加更多粉丝加入微博,3台服务器也不能够承受这样的压力了,那么就需要使用缓存改善性能了。
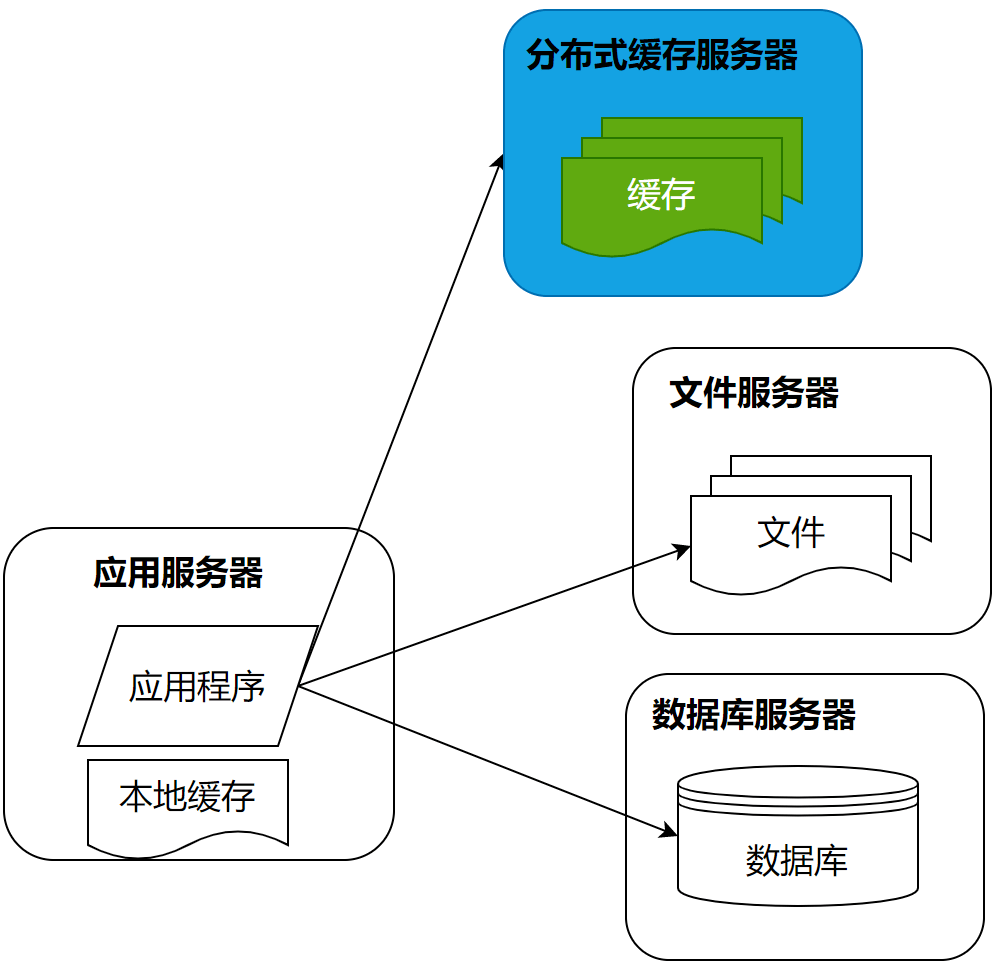
缓存就是将应用程序需要读取的数据放在缓存中,通过缓存读取数据,而不是通过数据库读取数据。缓存主要有分布式缓存和本地缓存两种。分布式缓存将多台服务器共同构成一个集群,存储更多的缓存数据,共同对应用程序提供缓存服务,提供更强大的缓存能力。
使用缓存,主要有两方面的好处:
- 一方面应用程序不需要去访问数据库,直接访问缓存,速度较快。
- 另一方面,数据库中的数据是以原始数据的形式存在的,而缓存中的数据通常是以结果形式存在,比如已经构建成某个对象,缓存的就是这个对象,不需要进行对象的计算,这样就减少了计算的时间,同时也减少了CPU的压力。
最主要的,应用通过访问缓存降低了对数据库的访问压力,而数据库通常是整个系统的瓶颈所在。降低了数据库的访问压力,就是改善整个系统的处理能力。
业务暴涨:应用服务器集群
随着用户的进一步增加,比如微博有更多的明星加入进来,并带来了更多粉丝。那么应用服务器可能又会成为瓶颈,因为连接大量的并发用户访问,这时候就需要对应用服务器进行升级。通过负载均衡服务器,将应用服务器部署为一个集群,添加更多的应用服务器去处理用户的访问。
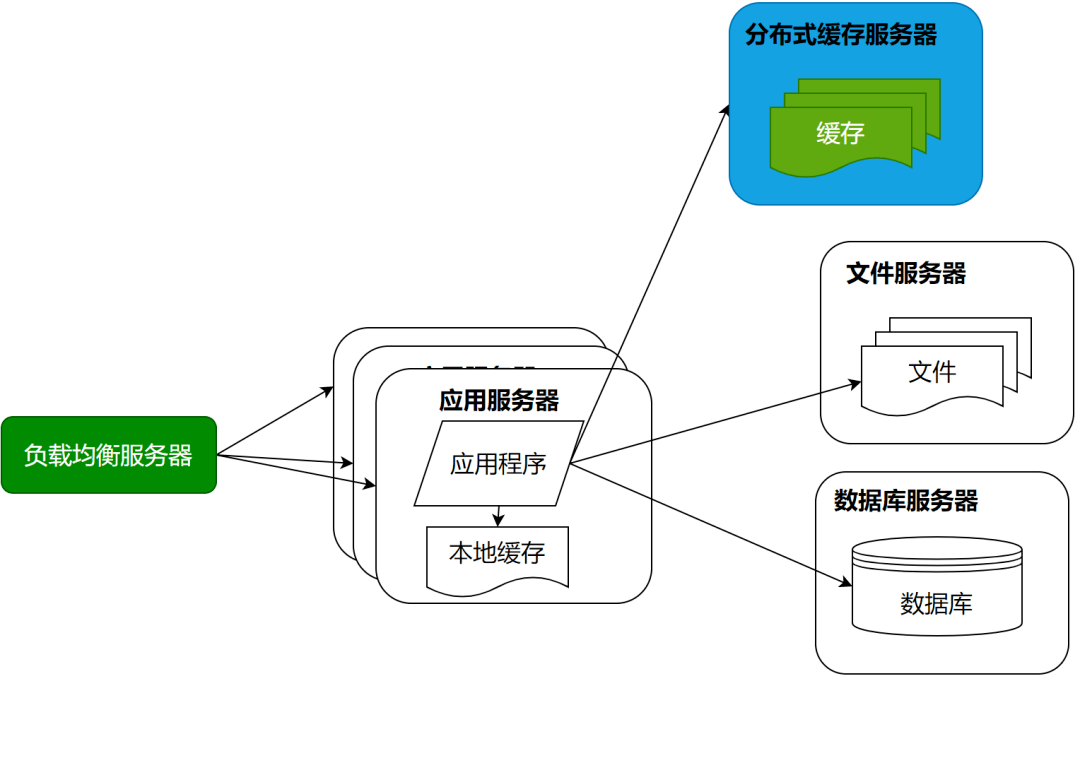
数据库再减负:读写分离
在微博上,我们主要操作是刷微博,也就是读微博数据。如果只是明星们发微博,粉丝读微博,那么对数据库的访问压力并不大,因为之前还有缓存。但是粉丝也是会发微博的,发微博就是向数据库中写数据,这样数据库会再一次成为整个系统的瓶颈点。单一数据库不能承受这么大的访问压力。
这时候的解决方案就是数据库的读写分离,将一个数据库通过数据复制的方式,分裂为两个数据库,主数据库主要负责写数据,然后写后的数据同步到从数据库上,保证从数据库和主数据库的数据一致。从数据库主要提供数据库的读操作。
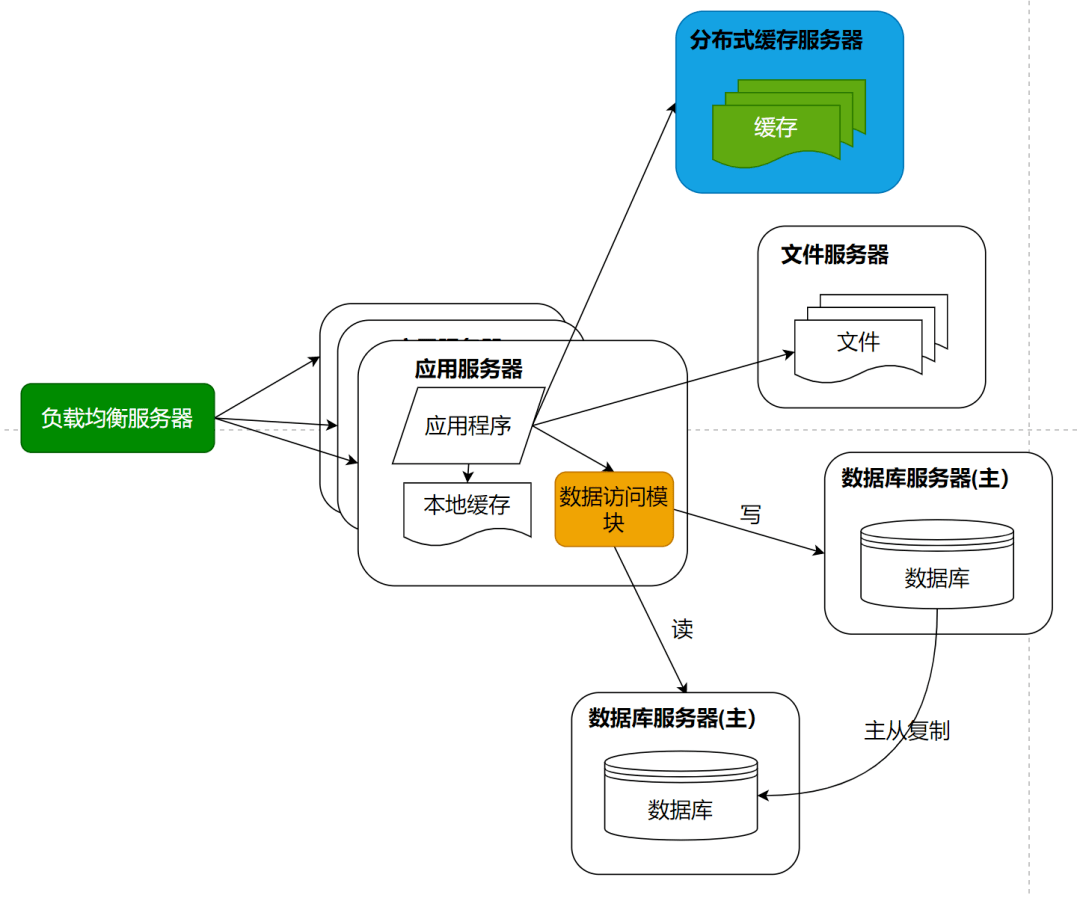
通过这样一种手段,将一台数据库服务器水平伸缩成两台数据库服务器,可以提供更强大的数据处理能力。
究极进化:完全分布式
对于大多数的互联网应用而言,目前的分布式架构就已经可以满足用户的并发访问压力了。但是对于更大规模的互联网应用而言,比如新浪微博,还需要解决海量数据的存储与查询,以及由此产生的网络带宽压力以及访问延迟等问题。此外随着业务的不断复杂化,如何实现系统的低耦合与模块开发、部署也成为了重要的技术挑战。
海量数据存储主要是通过分布式数据库、分布式文件系统、NoSQL数据库解决。直接在数据库上查询已经无法满足这些数据的查询性能要求,还需要部署独立的搜索引擎提供查询服务。同时减少数据中心的网络带宽压力,提供更短的访问延时。使用CDN和反向代理提供前置缓存,尽快返回静态文件资源给用户。
为了使各个子系统更灵活易于扩展,则使用分布式消息队列将相关子系统解耦,通过消息的发布订阅完成子系统间的协作。使用微服务架构将逻辑上独立的模块在物理上也独立部署,单独维护,应用系统通过组合多个微服务完成自己的业务逻辑,实现模块更高级别的复用,从而更快速的开发系统和维护系统。
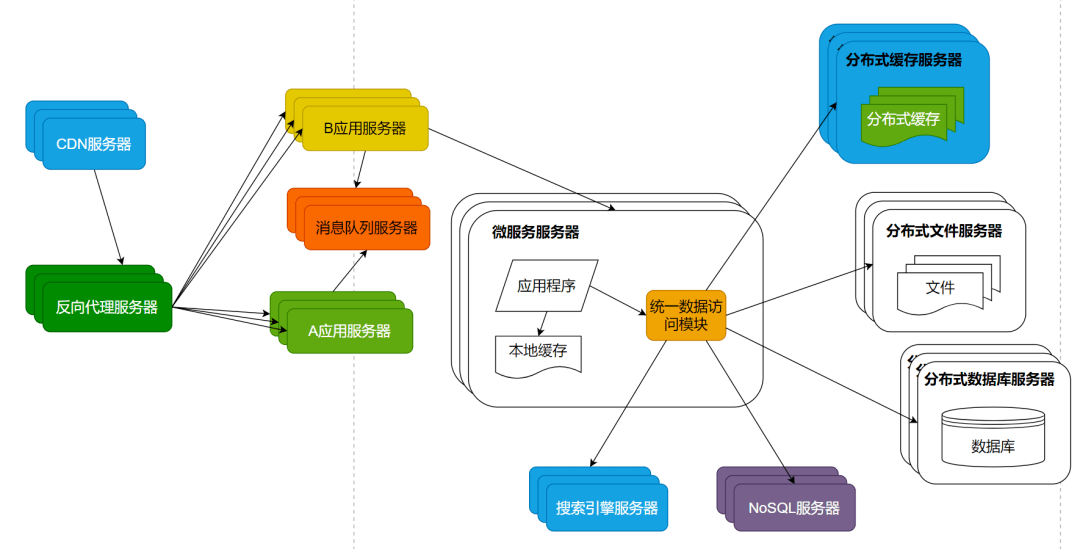
微服务、消息队列、NoSQL等这些分布式技术在出现早期的时候,比较有技术难度和使用门槛,只在相对比较大规模的互联网系统中使用。但是这些年随着技术的不断成熟,特别是云计算的普及,使用门槛逐渐降低,许多中小规模的系统,也已经普遍使用这些分布式技术架构设计自己的互联网系统了。
总结
目前越来越多的企业采用互联网的方式开展自己的业务。传统系统的用户量是有限而确定的,仓储系统主要面向的是仓库管理员,企业内部系统主要面向的是企业内部人员。但是如果企业要对外开展业务,而且这个业务很有价值,那么用户的增长速度会非常快。大量的用户访问企业系统,就会产生高并发的压力,需要消耗大量的计算资源,如何合理并充分的利用增加的计算资源处理业务就是系统架构设计的核心驱动力。主要就是用各种分布式技术去应对高并发量的用户请求。
但是为了解决高并发问题而采用分布式系统,引入一个集群必然带来集群所需要处理的问题,比如启用数据库集群必然带来数据如何在集群间分发、主库读写分离如何避免读库的同步延迟导致数据不一致性、分布式系统之间的调用如何确保事务性、引入缓存如何避免缓存和数据库的一致性问题等等