之前写过一篇文章, 并发编程的核心技术 – 多版本(Multi Versioning), 本文继续对并发编程做一次更全面的总结, 这样的总结并非具体的编程指导, 而概括性的理论, 是笔记性质的.
根据经验总结, 并发编程的指导思想可以总结为两个原则, 也即并发编程两原则:
Sharding 技术常见于分布式系统, 如果我举一个编程技巧里常用的技术, 估计你会比较熟悉 - 哈希锁. 例如 JAVA 语言里的 ConcurrentHashMap, 内部就是把整个容器分成独立的多个分段, 每个分段对应一把锁. 或者某些 KV 数据库, 预先分配若干个锁到数组中, 然后把每一个 key 根据 hash 算法对应不同的锁上面, 当需要对 key 加锁时, 加的是对应的那把锁, 两个 key 概率上可以同时加锁(并发).
分布式系统的核心之一就是 Sharding, 我曾经说过"无 Sharding, 不分布式", 指出没有严谨 Sharding 机制的多副本系统是伪分布式, 即使是所谓的强一致性多副本系统, 如无 Sharding 便是"伪分布式". Sharding 也是计算机科学领域核心思想之一的分而治之思想.
所以, 如果你遇到因为锁粒度太大导致多个并发操作相互阻塞的问题, 最直接的解决方案就是分析细化和拆分资源(做 Sharding), 不同的资源对应不同的锁, 这样就解决了阻塞问题. 一些初学者非常害怕和排斥锁, 我觉得没有必要. 程序的本质是串行化, 是锁, 我们能做的无非是: 减小锁粒度.
Sharding 是一种竖直分拆, 分拆出来的每一个 Shard 都是完全独立的(shared-nothing). 这一点和接下来要提到的 Leveling 在空间上刚好垂直.
Leveling 是一种水平分拆, 也叫 Layering(多层级). 在数据库领域, 它也叫 Multi Versioning(MVCC). 和 Photoshop 里作图类似, Leveling 包含多个 Level(层), 将不同的层级进行叠加(Merge), 最终形成一个统一的输出对象.
和 Photoshop 类似, 我们可以独立地操作每一个层, 如果需要加锁, 那就加在层上面, 因此, 也达到了减小锁粒度的效果. 看到了吧? 并发编程的唯一指导思想就是减小锁粒度. 妄图完全消除锁, 将在指导思想上发生根本错误.
Leveling 和 Sharding 技术的区别, 就在于它们如何对外展现. Leveling 需要将所有层进行合并, 才能输出结果. 而 Sharding 技术中的每一个 Shard, 可以独立地输出结果. 显然, 在这一点上 Sharding 技术要优于 Leveling. 既然 Sharding 更优, 为什么还需要 Leveling 呢? 因为, 事物并不总是可以做 Sharding, 有时候你做不了 Sharding.
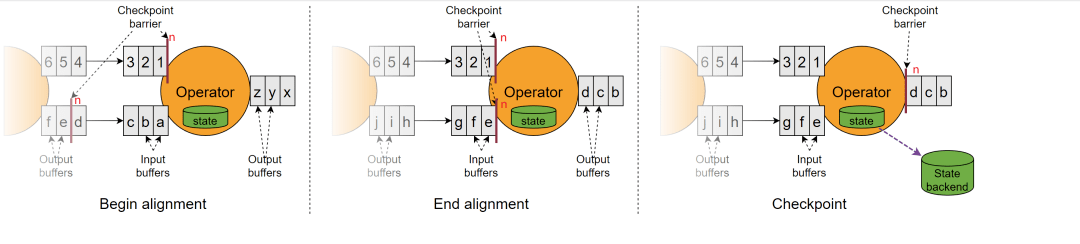
单点标记不是并发编程的核心原则, 而是 Leveling 技术的常见优化手段. 我们知道, Leveling 技术需要合并(Merge)操作, 合并操作可能成本较大, 这时, 我们需要把结果进行缓存. 但缓存和原始的层是同等地位的, 可能出现所谓的不一致(不相同)的问题, 所以, 需要引入一个单点标记, 对两者是否一致进行确认(check point, commit point), 就好像把两个子节点挂到了同一个父节点之下.
另外, 合并操作涉及很多算法, 某些算法不需要缓存, 仅仅是从多层(多个节点)之中选出一个 Winner, 以该 Winner 作为输出结果. 这时, 单点标记就是输出结果的指针, 指向 Winner.
总结出简洁的基础理论, 对我们的工作有什么帮助呢? 我认为, 一是可以帮助我们记忆, 二是掌握了基础理论之后, 可以随时推导出已有的大量纷纭复杂的技术, 不至于被乱花迷了眼.
另外, 并发编程和分布式系统本质上如此相似, 后面我将写一些文章, 用同样的基础理论对分布式系统进行分析.