计算机世界里的“堆栈”你真的懂吗?
如果你学过数据结构,就一定会遇到“堆”,"栈","堆栈",这些对于小白来说有些头大,下面就来科普一下何谓堆栈?
按照WIKI的定义:
堆栈(英语:stack),是计算机科学中一种特殊的串列形式的抽象数据类型,其特殊之处在于只能允许在链表或数组的一端(称为堆栈顶端指针,英语:top)进行加入数据(英语:push)和输出数据(英语:pop)的运算。另外堆栈也可以用一维数组或链表的形式来完成。堆栈的另外一个相对的操作方式称为队列。需要记住的是,堆:顺序随意,栈:后进先出(Last-In/First-Out)。

这里的pop和push到都是什么意思?其实这是堆栈数据结构使用两种基本操作:推入(压栈,push)和弹出(弹栈,pop):
推入:将数据放入堆栈的顶端(数组形式或串列形式),堆栈顶端top指针加一。
弹出:将顶端数据数据输出(回传),堆栈顶端数据减一。

如要了解堆栈,应将之拆开分析。
堆的概念:
堆(英语:Heap)是计算机科学中的一种特别的树状数据结构。通常是一个可以被看做一棵树的数组对象。若是满足以下特性,即可称为堆:“给定堆中任意节点 P 和 C,若 P 是 C 的父节点,那么 P 的值会小于等于(或大于等于) C 的值”。若父节点的值恒小于等于子节点的值,此堆称为最小堆(英语:min heap);反之,若父节点的值恒大于等于子节点的值,此堆称为最大堆(英语:max heap)。在堆中最顶端的那一个节点,称作根节点(英语:root node),根节点本身没有父节点(英语:parent node)。
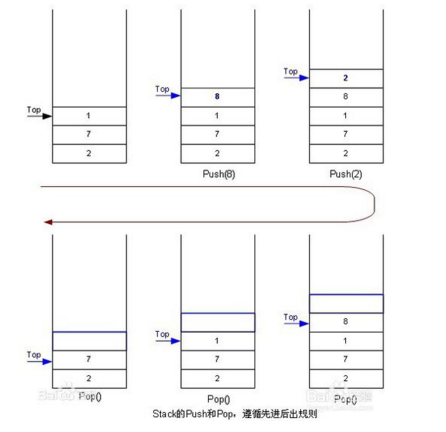
栈的概念
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来(先进后出)
栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有FIFO的特性,在编译的时候可以指定需要的Stack的大小。

堆栈
其实堆栈本身就是栈,只是换了个抽象的名字。其特性是: 最后一个放入堆栈中的物体总是被最先拿出来,这个特性通常称为后进先出(LIFO)队列。堆栈中定义了一些操作。 两个最重要就是上述提到的PUSH和POP。PUSH操作在堆栈的顶部加入一个元素,POP操作相反,在堆栈顶部移去一个元素,并将堆栈的大小减一。

工作原理
对于工作方式你可能还是一头雾水,以自助餐托盘为例解释一下,你就会更加明了:
作为堆栈如何工作的一个例子,可以把它看成一个弹簧加载托盘分发器,这种类型经常在自助餐厅中发现。每个托盘上都刻有数字。托盘依次从顶部装入,每个托盘都放置在已经装入的托盘上,弹簧进行压缩,以便在必要时为更多托盘留出空间。例如,在图中,托盘编号为42、23、2、9,先装载42个托盘,后装载9个托盘。

最后一个托盘是9号。因此,“第一个出来”的盘子也是9号。当顾客从托盘堆的顶部取出托盘时,第一个托盘是9号,第二个托盘是2号。然后更多的托盘被添加。这些托盘将不得不在我们装载第一个托盘之前从堆栈上下来。在托盘堆的任意顺序的push和pop出之后,托盘42仍然在底部。只有在42号托盘从堆栈顶部弹出后,堆栈才会再次清空。
而堆栈通常被放置在机器的最上面的地址区域。它们通常从最高的内存位置增长到较低的内存位置,允许在程序内存末端和堆栈“顶部”之间的内存使用中获得最大的灵活性。在我们的讨论中,堆栈在内存中是“向上”增长还是“向下”增长基本上是不相关的。堆栈的“top”元素是最后被推入并将首先被弹出的元素。堆栈的“底部”元素在删除时将使堆栈为空。
二者区别
堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。它由程序员分配和回收。
栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)由系统自动分配和回收。
堆栈缓存方式
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。
栈:在windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
作为“堆”的数据空间,必须是灵活的,因为成千上万的程序员在写什么程序是未知的。但可知道的一点,就是他们是跑在确定的某个OS里面的。因此,也不过就是给系统管理的数据空间起了个名字,叫栈;给程序员使用的空间,起了个名,叫堆。



























