5分钟读懂Unicode
Unicode是涵盖世界上大多数书写系统。用在网络,大多数操作系统,JAVA和.NET的标准编码等。
在Unicode诞生之前,都有自己的编码,它们都不同,而且不兼容编码。而Unicode是几乎所有字符的超集,因此可以用于互换信息。
它诞生至今30多年了。
在开始下文之前,如果遇到查询unicode代码的,可以使用工具类网站https://unicode.yunser.com/unicode

Unicode 为每个字符(例如a,ã, ې,不和☃)定义一个代码/数字。从Unicode 6.2开始(http://www.unicode.org/versions/Unicode6.2.0/),共有109,976个代码!
它还包括组合字符,诸如◌̀之类,这些字符可以添加到其他字符中;这样,Unicode不需要字母和重音的每种可能组合设置一个代码。另一方面,Unicode的一般不关心字体或风格上的区别:比如下面两个是同一种字符:

Unicode不只是字符集合。它还涵盖了诸如UTF-8之类的标准编码。小写/大写/标题大小写映射,整理(排序),换行符,从右到左的脚本的渲染处理等。

通用归一化/消除重复性
因为Unicode是其他编码的超集,所以它有时包括同一个字符,但是却有多个不同的代码,例如,以下三个:
- 带环的Å 拉丁大写字母A(U + 00C5)
- 一个长度计量单位,一单位等于0.1nm(U + 212B)
- u'\u0041\u030a' , 大写拉丁字母 A(U + 0041) + ◌̊ 组合键(U + 030A)
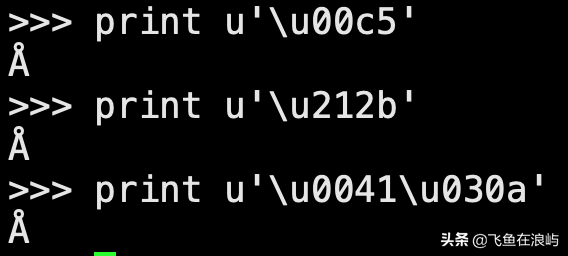
Python输出
为了使它们在相等性测试等中被视为相同的字符串,您应该通过Unicode规范(http://unicode.org/reports/tr15/)运行所有输入。最常见的形式是 NFC(Normalisation Form C),它尽可能使用预先组合字符,并如果存在多个,则一个严格的顺序定义这变音符号。NFD D(Normalisation Form D)则尽可能撰写1个字符。只要您保持一致,使用哪种形式都没有关系。NFD通常更快(代码点更少),建议通过NFD运行输入,并通过NFC输出。
Compatibility decomposition/兼容性分解(NFKC,compatibility decomposition + canonical composition)会把ffi,Ⅸ和甚至⁵映射为为“FFI”,“IX”和“5”分别。搜索文本时,这种NFKC规范化功能会起到帮助。
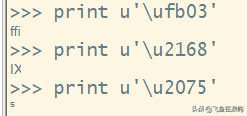
大小写折叠
在Unicode世界中,大小写并不是那么简单:
- 有些字符串在更改大小写时实际上会更改长度:ß将大写字母更改为“ SS”。
- 小号拉丁小写字母渴望着应为“s”和“S”在不区分大小写的比较被看作是相等的。
- Σ希腊大写字母 Sigma有两种小写形式: 单词的开头或中间写成σ,以及 ς在单词的结尾。
- 在希腊語中,若一个单字的最末一个字母是sigma,要把該字母寫成 ς。大寫Σ可以表示: 數學上的求和符號。 粒子物理學中的一類重子。 小寫σ可以表示: σ鍵
- 外壳大多是在地区之间基本一致,但土耳其是个例外:它既有一个点线和带点我,在这两个小写和大写。
为了确保您的代码能够处理这些情况以及任何新的情况,Unicode提供了 一种单向 “ casefold”操作,该操作允许不区分大小写的比较。
排序
排序(或排序规则)是特定于语言环境的,并且像大小写一样充满特殊性:
- 德国和瑞典都有 ä和ö,但是它们排序不同。德国将它们视为相同的字母变体没有变音符号(即“aä bcdefghijklmno öpqrstuvwxyz”),而瑞典认为在年底这些新的字母,并把它们放在最后('ABCDEFGHIJKLMNOPQRSTUVWXYZ äö)务必按照用户期望的顺序对事物进行排序。
- 排序也因应用程序而异;例如,电话簿的排序方式通常与书本索引不同。
- 对于汉字和其他表意文字,有许多可能的顺序,例如拼音(注音),按笔划计数等。
- 可以根据用户偏好(例如,大写优先还是小写优先)来排序。
仅通过二进制比较进行排序是不够的。而且,代码点通常也不是明智的。幸运的是,Unicode指定了一种 可高度自定义的归类算法,该算法涵盖了所有边缘情况,并且做了一些巧妙的工作以使其变得相当快。这是一个示例:2
该UCA可以把“10”和“2”视为数值,如排序“10”“放在“2”后面?” 。把“?”视为字符串“问号”。
编码方式
大端序有UTF-8,UTF-16和UTF-32。每种编码都保证几乎每个码点和字节序列的可逆映射。
- UTF-32非常简单:每个代码点用四个字节。占用大量空间,不建议用作信息互换。
- UTF-8在网络上非常常见。它是面向字节的(无字节序问题),处理得很好,与ASCII兼容,并且对于大多数为ASCII(例如html)的文本占用最小的空间。U + 0800和U + FFFF之间的代码点(包括常用的CJKV 字符/ 中国日本韩国越南)将占用3个字节而不是2个字节。因此,UTF-16可能更节省空间。ASCII兼容性有助于允许UTF-8在不支持Unicode的脚本和进程也能运行。但是,如果这样的系统尝试对数据执行任何操作(大小写转换,子字符串,正则表达式),则该数据会被损坏。
- Java,.NET和windows使用UTF-16。它使用2个字节(16位)表示最常见的63K代码点,并使用4个字节表示不常见的1M代码点(使用两个“代理”代码点)。与通常的做法相反,UTF-16不是固定宽度的编码。但是,只要不包含代理代码点,就可以将其视为一个独立,从而可以加快字符串操作。UTF-16流通常以U + FEFF开头,以检测流的字节序(字节顺序)。否则,您可以通过'UTF-16BE'或'UTF-16LE'显式编码或解码以指定字节序。
Unicode和国际化域名
国际字符 给域名带来了一个大问题。就像 I (I 0049 拉丁文大写 I)和 l(l 006C拉丁L的小写) 看起来很相似一样,Unicode除了增加了许多不可见的控制字符,空格字符和从右到左的文本外,还将这个问题放大很多。
浏览器和注册商已针对此采取了几种措施:
- 许多顶级域名限制可以在域名中使用哪些字符。
- 如果域包含来自多个脚本的字符和/或不属于用户首选语言之一的字符,则浏览器可以使用Punycode显示该域(请参见下文)。
- 国际化的国家/地区代码,例如.рф(俄罗斯),仅接受西里尔字母名称。
名称准备/字符串准备
RFC 3491定义了nameprep,一种在字符串可以在域名中使用之前对字符串进行大小写折叠,规范化和清理的机制。如果使用了禁止的代码点,这将删除许多不可见的字符并抛出异常。
Punycode/域名代码
出于传统原因,DNS不允许ASCII之外的扩展字符,因此Punycode是ASCII兼容的编码方案。例如,café.com变为xn--caf-dma.com。所有Punycode编码的域组件都可以通过其xn--前缀立即识别。
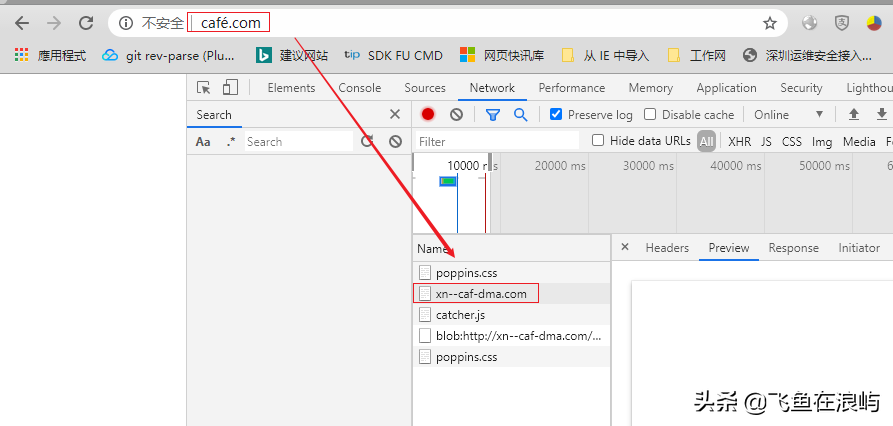
这也适用于顶级域名 :比如中国的代码为xn-fiqs8s。
“用户脚本”的问题
在Perl至少,一切(substr,length,index,reverse...)操作是以代码点为准。但这通常不是你想要的,因为用户认为像ў这样的字符实际上是两个代码点(y + ◌̆)。
甚至看似没问题的东西,例如printf "%-10s", $str完全中断组合字符,全角字符(例如中文/日文)或零角字符的操作。
换行
一旦涉及到Unicode ,换行(或自动换行)就变得异常复杂。您必须考虑各种不间断和不间断的控制和空格字符,每种语言中的标点符号(例如«和»引号或数字中使用的句号或逗号)以及每个字符的宽度。
文件系统
当您使用Unicode字符串作为文件或目录名称时,所有操作都不好用。使用什么编码?使用什么API?(Windows有两种,一种使用Unicode,另一种尝试使用与语言环境相关的编码)。mac OSX文件系统则会执行规范化,例如对文件名执行NFD。如果您的平台不了解分解后的Unicode,则可能会出现问题。
汉字统一
汉字是中文,日文(汉字)以及韩文和越南文的共同特征。根据脚本的不同,许多脚本都有独特的视觉外观,但是Unicode出于简化和性能的原因将它们统一为一个代码点(示例)。

这引起了争议,因为角色的视觉形式可能有意义;可能不会向用户显示他们的国家/地区版本,而是其他国家/地区的版本。在某些情况下,它们看起来可能非常不同(例如,直)。正如西方名称的变化(例如“ John”或“ Jon”)一样,日语名称可能使用Unicode无法提供的特定字形变体,因此人们实际上无法以自己喜欢的方式来写自己的名字!
实际上,用户选择一种字体以其想要的样式呈现字形,无论是日语还是中文。变体选择器(参见下文)是解决该问题的另一种方法。
由于政治和遗留原因(与旧字符集兼容),Unicode不会尝试统一简体和繁体中文。
表情符号
Unicode 6.0版增加了722个“表情符号”字符,这些表情符号通常在日语手机上使用,但最近在Mac OS X(Lion),Gmail,iphone和Windows Phone 7中使用。某些字体可能选择将其呈现为全彩色表情符号。 ; 有些则可能根本不支持他们。
表情符号的Unicode表示,包含你熟悉的LOVE HOTEL 和PILE OF POO
区域国旗符号
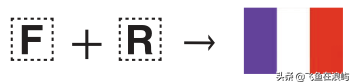
Unicode 6.0的表情符号为许多国家(地区)标志引入了符号,但并不是全部国家。作为一种可选方案,范围U + 1F1E6 .. U + 1F1FF 定义了从A到Z的符号。如果该范围中的两个符号形成了ISO-3166-1国家代码(例如,法国的“ FR”),则渲染器可以显示为国旗!
变体选择器
变体选择器是代码点,可更改渲染字符之前的字符方式。有256个,它们占据的范围为U + FE00 .. U + FE0F 和U + E0100.. U + E01EF加上U + 180B,U + 180C和U + 180D。
它们对于蒙古语脚本来说是必不可少的,蒙古语脚本具有不同的字形形式,具体取决于其在单词中的位置,单词的性别,附近有哪些字母,单词是否为外国单词以及现代与传统拼字法(详细信息)。
预计这些将用于提供由Han Unification统一的字形的变体。
它们还用于更深奥的事物,例如数学运算符的衬线版本。



























