1. 什么是Series?
Series是一种类似于一维数组的对象,与一维数组对象不同的是Series带有标签(索引),通俗来说就是一维带标签(索引)的一维数组。如下图所示:
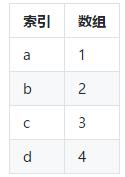
带有索引的一维数组
2. 如何创建Series?
Series是一维带标签(索引)的一维数组,对于Series最关键的也就是索引index和与之对应的value值。
一般格式 (这里的data就是value值的集合):
s = pd.Series( data , index )
data几种常见的取值类型:
- 标量值、list列表;
- ndarray对象;
- dict字典;
index取值规范:
- 索引值必须是可hashable的(如果一个对象是可散列的,那么在这个对象的生命周期中,他的散列值是不会变的(它需要实现__hash__()方法)),并且索引index的长度必须和value值的长度一致,如果不一致会抛出异常(这点需要格外的注意);
- 如果不设置索引,默认索引是从0到n-1的序列值[其中n为data值的长度];
- 如果data的类型为dict字典类型,对应的字典中的key值就是对应series对象中的index值;
- 相同的索引值也是可以的;
下面依照着data的几种常见的类型来分别介绍,中间会穿插着index的取值规范问题:
2.1 data为标量值、list列表
#data:标量值1
#index:不指定(默认索引)
import pandas as pd
s = pd.Series(1)
print(s)
result:
0 1
dtype: int64
#data:list列表
#index:通过list列表指定,其中data和index长度一致
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ["a","a","c","d","e"])
print(s)
result:
a 1
a 2
c 3
d 4
e 5
dtype: int64
注意:
- 当创建Series对象的时候指定index的时候,index元素个数(此处的index为一个list列表)要和data中元素个数相等;
- 使用相同的索引值"a",程序并没有发生异常,索引值可以是相同的;
2.2 data为ndarray对象
import numpy as np
import pandas as pd
data = np.arange(5)
#使用list作为index索引
index2 = ["a","b","c","d","e"]
#使用ndarray数组作为index索引
index3 = np.array(["a","b","c","d","e"])
s = pd.Series(data)
s2 = pd.Series(data,index2)
s3 = pd.Series(data,index3)
print(s)
print("-"*6)
print(s2)
print("-"*6)
print(s3)
result:
0 0
1 1
2 2
3 3
4 4
dtype: int32
------
a 0
b 1
c 2
d 3
e 4
dtype: int32
------
a 0
b 1
c 2
d 3
e 4
dtype: int32
注意:
- 此时的data是ndarray数组类型,而index分别指定了无参数的默认index索引、指定list列表以及指定ndarray数组类型的index。
2.3 data为dict字典
import pandas as pd
d = {"a":0,"b":1,"c":2}
s = pd.Series(d)
print(s)
result:
a 0
b 1
c 2
dtype: int64
这里由于将data位置的参数传入字典,将字典的键作为了Series对象的index,所以如果再次指定index的时候会出现一些新的情况:
- 指定的index中不包含字典中的键值;
- 指定的index中包含部分字典中的键值;
- 指定的index中包含全部的字典中键值;
下面就使用代码简单的介绍一下这三种情况。
- 指定的index中不包含字典中的键值
import pandas as pd
d = {"a":0,"b":1,"c":2}
s = pd.Series(d,index = ["d","e"])
print(s)
result:
d NaN
e NaN
dtype: float64
- 指定的index中包含部分字典中的键值
import pandas as pd
d = {"a":0,"b":1,"c":2}
s = pd.Series(d,index = ["a","d"])
print(s)
result:
a 0.0
d NaN
dtype: float64
- 指定的index中包含全部的字典中键值
import pandas as pd
d = {"a":0,"b":1,"c":2}
s = pd.Series(d,index = ["a","b","c"])
print(s)
result:
a 0
b 1
c 2
dtype: int64
总结:
我们知道创建Series对象的一般格式,包含两个参数data和index索引。我们使用Python字典作为创建Series的data,同时我们知道当将字典作为创建Series对象的data的话,Python字典中的key可以作为Series的index,但是此时我们仍然可以继续指定index,通过上面的三种情况的描述,可以得出结论,使用字典创建Series,同时指定index的话,此时的index起到一个筛选的作用,最终的输出结果就是指定的index,如果指定的index在字典中的key中,则将对应的值关联到指定的index中;如果指定的index不在字典中的key中,则将NaN关联到指定index中。由于Python中字典中的key不能够重复,所以虽然Series允许使用有重复的index值,但是如果使用字典创建Series的时候肯定不会有相同的index值。
3. Series的属性
此处介绍Series属性包括两个方面(因为此处介绍的是Series的属性不是Series的方法,所以不要在后面加小括号):
- 获取Series的index索引和value值,顺便介绍统计index和value相同类别的个数的方法;
- 获取Series的名称以及index的名称;
#实验所用到的Series对象
import pandas as pd
s = pd.Series([1,2,3],index = ["a","b","a"])
print(s)
3.1 获取index索引和value值,并统计index和value相同类别的个数
下面将index和value分开来介绍:
#获取Series的索引
print(s.index)
result:
Index(['a', 'b', 'a'], dtype='object')
此时返回的索引是一个迭代器对象,这个对象还可能会有其他的属性。如果我们想要获取其中的具体值的话,可以使用for循环进行遍历,还可以使用下面这些简单的属性将迭代转换为ndarray数组或者是list列表:
print(s.index.values)
print(type(s.index.values))
print("-"*6)
print(list(s.index.values))
print(type(list(s.index.values)))
result:
['a' 'b' 'a']
<class 'numpy.ndarray'>
------
['a', 'b', 'a']
<class 'list'>
如果我们想要统计Series中索引相同索引的个数,可以使用下面的方法(注意此时是方法不在是属性了):
print(s.index.value_counts())
result:
a 2
b 1
dtype: int64
values其实和index类似,下面简单的介绍一下:
print(s.values)
print(type(s.values))
result:
[1 2 3]
<class 'numpy.ndarray'>
与获取index不同的是,使用s.values返回的就是包含值的ndarray数组类型。下面统计相同value值的个数,同样这个也是一个方法,这个方法还是很常用的:
print(s.value_counts())
result:
3 1
2 1
1 1
dtype: int64
3.2 获取Series的名称以及index的名称
Series有本身以及index和value,除了value没有名称外,Series本身和index都可以指定名称,如果不指定的话默认为None。
s.name = "my Series"
s.index.name = "my index"
print(s)
result:
my index
a 1
b 2
a 3
Name: my Series, dtype: int64
4. Series的索引获取指定值
Series简单来说就是带有索引的一维数组,我们很自然的可以通过索引来获取对应的value值,我们有三种方式进行索引:
- 位置索引。通过0 ~ n-1[n为Series中索引个数]进行索引;
- 名称索引。通过传入指定的index名称来进行索引;
- 获取单个索引值;
- 获取多个索引值;
- 点索引。通过".index名称"的形式进行索引;
下面来分别介绍这三种索引方式以及需要注意的地方。
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
print(s)
4.1 位置索引
# 位置索引
print(s[0])
print(s[-1])
print(s[2])
result:
1
4
3
此处的位置索引类似python中的list列表,不仅能够正向索引[从0开始]而且还能够反向索引[从-1开始反向索引]。
4.2 名称索引
# index名称索引
#获取单个索引值
print(s["a"])
print("*"*6)
#获取多个索引值
print(s[["a","b","c"]])
result:
1
******
a 1
b 2
c 3
dtype: int64
使用名称索引不仅可以索引单个value值,也可以索引多个value值。平时用的最多的就是位置索引和名称索引,说一说使用他们的时候需要注意的地方:
- 我们知道Series的index索引可以是任意类型,如果index为整数类型,那么位置索引就会失效。
import pandas as pd
s = pd.Series(["a","b","c","d"],index = [1,3,4,5])
# 此处使用位置索引会抛出异常KeyError
# print(s[-1])
# print(s[2])
#此处得到的结果是名称索引
print(s[3])
result:
b
- 由于Series的index是可以重复的,对于位置索引来说无论index是否重复都与索引没有关系,但是如果使用名称索引的话,索引出来的是结果是一个具有相同index的Series对象。
import pandas as pd
s = pd.Series(["a","b","c","d"],index = [1,1,4,5])
# 此处使用的是名称索引
print(s[1])
result:
1 a
1 b
dtype: object
4.3 点索引
平时使用名称索引以及位置索引足够使用。点索引使用有很多局限性:
- 点索引只使用于Series的index类型为非数值类型才可以使用;
- 如果Series中的index中有一些索引名称与Python的一些关键字或者一些函数名重名的话,会导致无法获取Series的值;
import pandas as pd
# 此时的index为数值类型
s = pd.Series(["a","b","c","d"],index = [1,2,3,4])
# 会抛出语法错误的异常SyntaxError
# print(s.2)
import pandas as pd
# 此时的index为数值类型
s = pd.Series([1,2,3,4],index = ["a","b","c","def"])
# 通过点索引获取value值
print(s.a)
# 会抛出语法错误的异常SyntaxError
# print(s.def)
result:
1
5. Series的切片slice
通过Series的切片来获取连续的多个索引对应的值,Series的切片有两种方式:
- 使用位置切片,类似s[start_index : end_index],熟悉python都知道这种切片方式,需要注意的这种方式切片同样是包左不包右;
- 使用名称切片,类似s [start_index_name , end_index_name],这种方式和上面使用位置切片的最大区别就是名称切片,即包左又包右;
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
print(s)
result:
a 1
b 2
c 3
d 4
dtype: int64
5.1 位置切片
# 使用位置切片
print(s[0:2])
result:
a 1
b 2
dtype: int64
5.2 名称切片
# 使用名称切片
print(s["b":"d"])
result:
b 2
c 3
d 4
dtype: int64
注意:
在上面的索引方式,我们知道了位置索引和名称索引在index为数值类型时候的不同,当index为数值类型的时候,使用位置索引会抛出keyerror的异常,也就是说当index为数值类型的时候,索引使用的是名称索引。但是在切片的时候,有很大的不同,如果index为数值类型的时候,切片使用的是位置切片。总的来说,当index为数值类型的时候:
- 进行索引的时候,相当于使用的是名称索引;
- 进行切片的时候,相当于使用的是位置切片;
6. Series的增删改查
6.1 添加Series的值(增)
为Series添加新的值的方式有两种:
- 使用series.Append(pd.Series(data,index))的方式添加,这种方式会返回一个新的Series对象,这种方式最大的特点就是可以添加多个Series值;
- 使用series["new_index"] = value的方式添加,这种方式会直接在原来的Series上进行修改,并且这种方式每次只能够添加一个Series值;
import pandas as pd
s = pd.Series(1,index =["a"])
print(s)
print("*"*6)
# 使用append方式添加多个Series值
# 此处将返回的值赋值给了原来的Series,因为使用append添加的话返回的是新的Series对象
s = s.append(pd.Series([2,3],index = ["b","c"]))
print(s)
print("*"*6)
# 使用s[new_index] = value方式添加
s["d"] = 4
print(s)
result:
a 1
dtype: int64
******
a 1
b 2
c 3
dtype: int64
******
a 1
b 2
c 3
d 4
dtype: int64
6.2 删除series的值(删)
删除直接使用del关键字删除即可。
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
print(s)
print("*"*6)
del s["b"]
print(s)
result:
a 1
b 2
c 3
d 4
dtype: int64
******
a 1
c 3
d 4
dtype: int64
6.3 通过索引修改Series的值(改)
其实此时介绍的修改Series的值和在4中介绍的一致,只不过将4中介绍的获取到的Series值进行重新的赋值即是修改对应Series的值,因此此处也有三种方式:
- 通过位置索引修改value值;
- 通过名称索引修改value值;
- 通过点索引修改value值;
此处因为类似,所以只选择一个进行实验:
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
s["a"] = 100
print(s)
result:
a 100
b 2
c 3
d 4
dtype: int64
6.4 判断索引是否在Series中(查)
判断index是否在Series中很简单,其实和python中查看元素是否在list列表中的方法是一样的。
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
print("a" in s)
print("q" in s)
result:
True
False
7. 过滤Series的值
我们可以通过布尔选择器,也就是条件筛选来过滤一些特定的值,从而仅仅获取满足条件的值。过滤Series的值的方式分为两种:
- 单条件筛选;
- 多条件筛选;
import pandas as pd
s = pd.Series([1,2,3,4],index = ["a","b","c","d"])
7.1 单条件筛选
print("-"*5 + "布尔选择器" + "-"*5)
print(s < 3)
print("-"*5 + "单条件查询" + "-"*5)
print(s[s<3])
result:
-----布尔选择器-----
a True
b True
c False
d False
dtype: bool
-----单条件查询-----
a 1
b 2
dtype: int64
7.2 多条件查询
print("-"*5 + "多条件查询" + "-"*5)
print(s[(s > 2) & (s < 4) ])
result:
-----多条件查询-----
c 3
dtype: int64
注意:
- 多条件查询中的and以及or必须使用对应的符号来表示,and用&,or用|来表示;
- 使用多条件的时候,为了避免出错,在每个条件上最好加上括号;
8. Series缺失值的处理
- 判断Value值是否为缺失值,isnull()判断series中的缺失值以及s.notnull()判断series中的非缺失值;
- 删除缺失值
- 使用dropna();
- 使用isnull()以及notnull();
- 填充缺失值
- 使用fillna;
- 使用指定值填充缺失值;
- 使用插值填充缺失值;
- 向前填充ffill;
- 向后填充bfill;
- 使用fillna;
# 创建一个带缺失值的Series
import pandas as pd
s = pd.Series([1,2,None,4])
print(s)
result:
0 1.0
1 2.0
2 NaN
3 4.0
dtype: float64
8.1 判断value值是否为缺失值
有两种方式判断:
- s.isnull()判断s中的缺失值;
- s.notnull()判断s中的非缺失值;
# 缺失值的地方为True
print("-"*5 + "使用s.isnull判断" + "-"*5)
print(s.isnull())
#缺失值的地方为False
print("-"*5 + "使用s.notnull判断" + "-"*5)
print(s.notnull())
result:
-----使用s.isnull判断-----
0 False
1 False
2 True
3 False
dtype: bool
-----使用s.notnull判断-----
0 True
1 True
2 False
3 True
dtype: bool
8.2 删除缺失值
- 使用dropna()方法删除缺失值,返回新的Series对象;
- 使用series.isnull()以及series.notnull()方法,使用布尔筛选进行过滤出非缺失值;
print("-"*5 + "使用dropna()删除所有的缺失值" + "-"*5)
print(s.dropna())
print("-"*5 + "使用isnull()删除所有的缺失值" + "-"*5)
print(s[~s.isnull()])
print("-"*5 + "使用notnull()删除所有的缺失值" + "-"*5)
print(s[s.notnull()])
result:
-----使用dropna()删除所有的缺失值-----
0 1.0
1 2.0
3 4.0
dtype: float64
-----使用isnull()删除所有的缺失值-----
0 1.0
1 2.0
3 4.0
dtype: float64
-----使用notnull()删除所有的缺失值-----
0 1.0
1 2.0
3 4.0
dtype: float64
8.3 使用fillna()填充缺失值
- 使用指定值填充缺失值;
- 使用插值填充缺失值;
print("-"*5 + "原来的Series" + "-"*5)
print(s)
print("-"*5 + "指定填充值0" + "-"*5)
print(s.fillna(value = 0))
print("-"*5 + "向前填充ffill" + "-"*5)
print(s.fillna(method = "ffill"))
print("-"*5 + "向后填充bfill" + "-"*5)
print(s.fillna(method = "bfill"))
result:
-----原来的Series-----
0 1.0
1 2.0
2 NaN
3 4.0
dtype: float64
-----指定填充值0-----
0 1.0
1 2.0
2 0.0
3 4.0
dtype: float64
-----向前填充ffill-----
0 1.0
1 2.0
2 2.0
3 4.0
dtype: float64
-----向后填充bfill-----
0 1.0
1 2.0
2 4.0
3 4.0
dtype: float64
注意:
默认情况下,填充缺失值都会创建一个新的Series对象,如果希望直接在原来的Series上进行修改的话,可以使用下面两种方式:
- 直接进行赋值;
- 给fillna()函数添加一个新的参数,inplace = True参数;
9. Series排序
series的排序有两种:
- 根据索引进行排序,使用series.sort_index(ascending = True);
- 根据值进行排序,使用series.sort_value(ascending = True);
10. Series的描述性统计

Series的描述性统计
更多原创干货,欢迎关注我的知乎"触摸壹缕阳光"以及公众号"AI机器学习与深度学习算法"



























