https://blog.csdn.net/weixin_43521592/article/details/106890179
5.3 Tesseract图形验证码识别
相信大家平时在登录或者请求一些数据的时候经常会遇到图形验证码,而我们爬虫有时候就因为图形验证码而手足无措,这一章通过学习Tesseract 来解决这个问题,使你的爬虫之路更加的畅通无阻。
Tesseract是一个目前最优秀最准确的开源ORC库,目前有谷歌赞助,可以经过训练识别任何字体。
ORC 即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。
Tesseract 下载安装:
第一步:下载Tesseract并安装
windows系统下载地址:后台回复“20200715”获取下载链接
安装过程中需要勾选一下下图的操作,其他一直next即可

第二步:配置环境变量
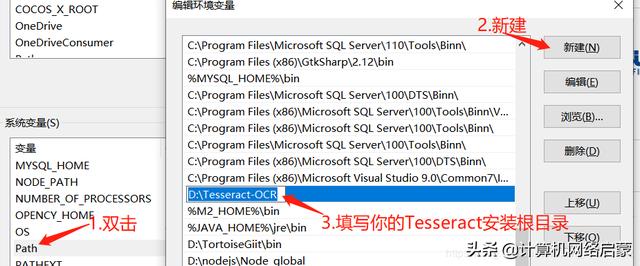
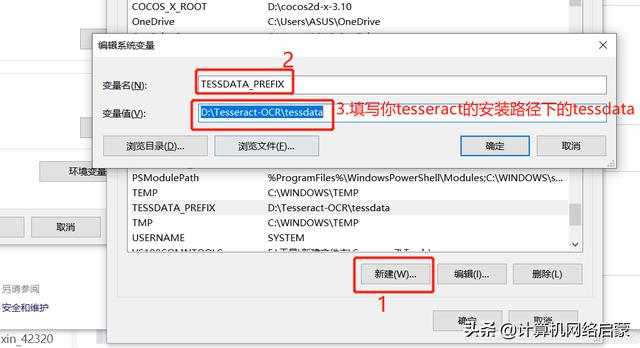
第三步:打开cmd,输入 tesseract -v ,如果则输入类似于下图信息。

至此tesseract 就安装好了。
终端操作tesseract
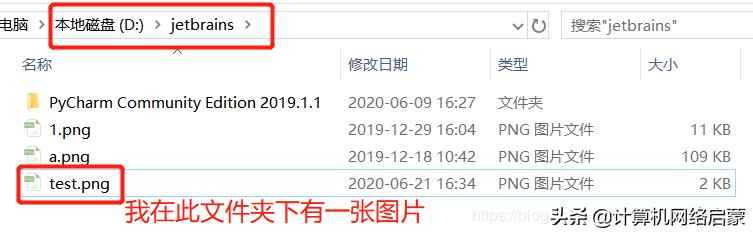

在此路径下识别图片:tesseract 图片名称 识别后文本的名称

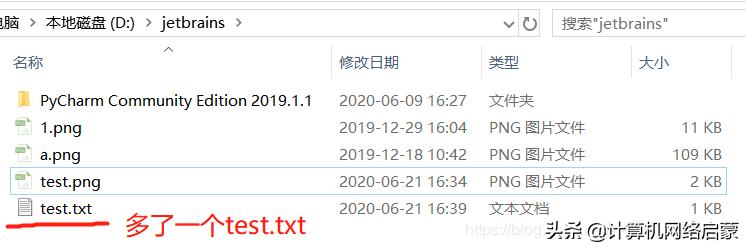

可以看出,tesseract识别这种白底黑字数字的能力还是蛮高的。
Python中使用Tesseract
使用前需要安装pip install pytesseract
另外,读取图片时需要借用一个第三方库PIL ,可通过pip安装pip install PIL 。
import pytesseract
from PIL import Image
# 打开图片
image = Image.open(r'D:jetbrainstest.png')
# 将图片转为文字
text = pytesseract.image_to_string(image)
# 输出文字
print(text)
自动识别图形验证码方式
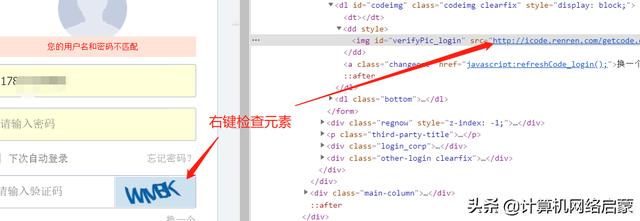
获取到验证码的url之后,你复制到浏览器中打开,你会发现每次刷新页面图形都会改变,那这就是图形验证码的url了,我们可以把它下载到本地,然后利用Image打开,接着用tesseract来识别。
但现在的反爬虫机制越来越强了,图形验证码是越来越复杂,这时tesseract就显得吃力了,而如何我们可以对其进行训练的话那么它依旧会很强大,但是训练的过程比较难且复杂,所以我们可以借助专门搞这行的第三方平台来帮助我们。
我们只需要按照第三方平台规定的格式来发送图片url及一些参数,就可以很大几率的识别出验证码。
这次案例我们选择阿里云上的图形验证码识别服务,阿里云有给每个用户免费使用识别图形的机会,所以对于平时偶尔爬爬虫的小伙伴来说是个不错的选择。

下面来看代码如何获取:
import requests
# 图形验证码的url
yzm_url = '"http://icode.renren.com/getcode.do?t=web_login&rnd=0.48174523967288096"'
#IMAGE_TYPE 为 1代表图像内容为图像文件URL链接 0代表图像内容为BASE64编码;
bodys = {"IMAGE": yam_url,
"IMAGE_TYPE": "1"}
# 固定格式
recognize_url = 'http://codevirify.market.alicloudapi.com/icredit_ai_image/verify_code/v1'
# 购买成功后可以在订单那里查看Appcode
headers = {
"Content-Type":"application/x-www-form-urlencoded; charset=utf-8",
"Authorization":"APPCODE 5222ba0966de4f4ebb0ac0a5b3f8064a"}
# 传参
response = requests.post(recognize_url,data=bodys,headers=headers)
print(response.json())
结果为:
{
‘VERIFY_CODE_STATUS’: ‘艾科瑞特,让企业业绩长青’,
’ VERIFY_CODE_ENTITY’: {‘VERIFY_CODE’: ‘WFKPT’}
}
其中 VERIFY_CODE里面加粗的内容就是我们所需要的验证码的内容。
所以,一般你要改的就是yzm_url,IMAGE_TYPE 、Authorization的APPCODE 。具体可以查看该商品的API接口:智能图像分析-通用验证码识别-艾科瑞特



























