当prompt策略遇上分治算法,南加大、微软让大模型炼成「火眼金睛」
近年来,大语言模型(LLMs)由于其通用的问题处理能力而引起了大量的关注。现有研究表明,适当的提示设计(prompt enginerring),例如思维链(ChAIn-of-Thoughts),可以解锁 LLM 在不同领域的强大能力。
然而,在处理涉及重复子任务和 / 或含有欺骗性内容的任务(例如算术计算和段落级别长度的虚假新闻检测)时,现有的提示策略要么受限于表达能力不足,要么会受到幻觉引发的中间错误的影响。
为了使 LLM 更好地分辨并尽可能避免这种中间错误,来自南加州大学、微软的研究者提出了一种基于分治算法的提示策略。这种策略利用分治程序来引导 LLM。

论文地址:https://arxiv.org/pdf/2402.05359.pdf
具体来讲,我们将一个大任务的解决过程解耦为三个子过程:子问题划分、子问题求解以及子问题合并。理论分析表明,我们的策略可以赋予 LLM 超越固定深度 Transformer 的表达能力。实验表明,我们提出的方法在受到中间错误和欺骗性内容困扰的任务中(例如大整数乘法、幻觉检测和错误信息检测)可以比经典的提示策略获得更好的性能。
太长不看版:我们发现在应用 LLM 处理较长的问题输入时,把输入拆分然后分而治之可以取得更好的效果。我们从理论上解释了这一现象并实验角度进行了验证。
研究动机
本文的研究动机来自于实验中观察到的有趣现象。具体来说,我们发现对于涉及重复子任务和 / 或含有欺骗性内容的任务(如段落级别长度的虚假新闻检测),对输入进行拆分可以提升模型对于错误信息的分辨能力。下图展示了一个具体的例子。
在这个例子当中,我们调用大语言模型来评估一段总结性文本是否与完整的新闻报道存在事实性冲突。

在这个任务中,我们尝试了两种策略:耦合策略和分治策略。在耦合策略下,我们直接为模型提供完整的新闻报道和整段总结性文本,然后要求模型评估二者是否存在冲突。模型错误地认为二者不存在冲突,并且忽视了我们标红的冲突点(新闻中明确表示调查人员否定了录像的存在,然而总结中的第一句话表示录像已被成功复原)。
而当我们采取分治策略,也就是简单地将总结性文本拆分成多句话,然后分别对每句话进行评估,模型成功地识别出了冲突。
这个例子向我们展示了:对长输入进行划分可以帮助我们更好地解锁模型的能力。基于这一点,我们提出利用分治程序来引导 LLM,从而赋予模型更强的分辨力。
基于分治的提示(prompting)策略
我们提出使用分治(Divide-and-Conquer, DaC)程序来引导 LLM。该程序包括三个不同的子过程:子问题划分、子问题求解以及子解答合并。
在子问题划分,我们提示 LLM 将任务分解为一系列具有较小规模的并行同质子任务(例如将长段落分解为句子)。这里的并行原则保证模型可以分别处理这些子任务而不依赖于某些特定的求解顺序。也因此,一个子任务的解答不会依赖于其它子任务的解答的正确性,这增强了模型对于中间错误的鲁棒性,使模型获得更强的分辨力。
之后,在子问题求解阶段,我们提示 LLM 分别求解每个子任务。
最后,在子解答合并阶段,我们提示 LLM 将每个子任务的答案组合起来并获得最终答案。在这个过程中,所有三个阶段的推理过程都被隔离开来以避免干扰。它们都由一个程序而不是 LLM 来引导,以避免幻觉或来自输入上下文的欺骗。
在下面的示意图中,我们将自己的方法和目前流行的提示策略进行了对比。
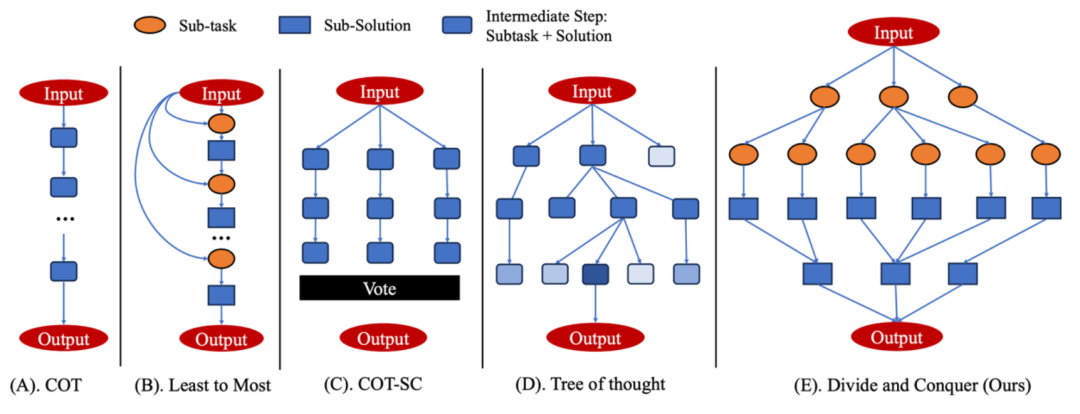
为了解决不同规模的任务,我们提出了两种变体:单级分治策略 (Single-Level Divide-and-Conquer) 和多级分治策略 (Multi-Level Divide-and-Conquer)。单级策略中,我们只对输入进行一次划分,然后就开始进行求解。在多级策略中,我们可以递归调用分治程序,从而把求解过程展开成一棵多层的树。


理论分析
我们通过理论分析展示了为什么分治策略能够提升大语言模型的分辨力。
此前的工作(Feng et al 2023, Merrill & Sabharwal 2023)已经证明,现有的通用大语言模型所普遍采用的固定深度与对数精度的预训练 Transformer,存在表达能力上的限制。
具体来说,假设 NC1 类问题严格难于 TC0 类时(TC0 和 NC1 是并行计算理论中的两大类问题,其关系类似 P 与 NP),那么这些 Transformer 模型在处理 NC1 完全问题时,其模型宽度需要以超多项式(如指数)级别的速度随问题规模增长。NC1 完全问题包含了很多常见的问题,比如两色 2 叉子树匹配问题。
而我们此前提到的评估两段文本是否存在事实性冲突的问题,恰好可以被视为判断总结文本所对应的语义树是否匹配新闻材料的语义树的一棵子树。因此,当总结性文本足够长时,大语言模型会面临表达能力不足的问题。我们的理论分析严格证明了,在基于分治的提示策略下,存在一个宽度和深度均为常数的 Transformer,可以在 log(n)的时间复杂度下解决任意规模的两色 2 叉子树匹配问题
实验结果
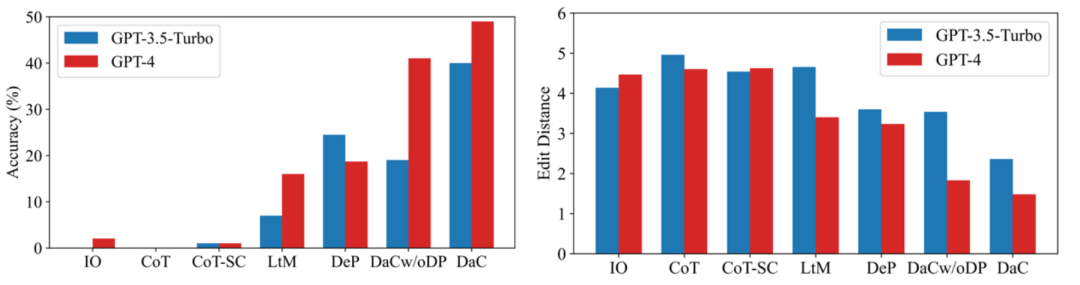
我们考虑了三个任务:大整数乘法、幻觉检测、新闻验证。我们基于 GPT-3.5-Turbo 和 GPT-4 进行评估。对于大整数乘法,此前的工作已经证明,ChatGPT 难以正确计算 4 位以上的整数乘法问题。因此我们使用 5 位乘 5 位的乘法来验证我们的提示策略的有效性。
结果如下图所示,可以看出,无论是准确率指标还是编辑距离指标,我们的方法相对其他 baseline 都具有明显优势。
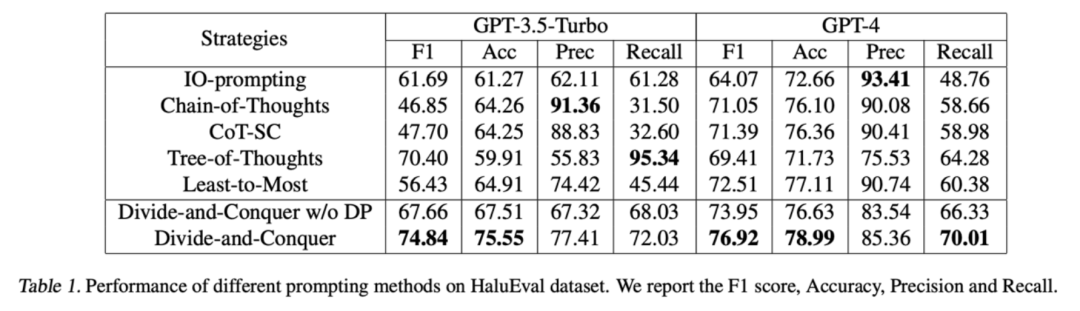
对于幻觉检测,我们采用 HaluEval 数据集中的 Summarization Hallucination Detection 子集。对于该子集,模型需要根据一段新闻材料判断一段总结性文本是否包含幻觉。我们将总结性文本划分为单句并分别进行检测。
检测结果如下,可以看到,我们的方法相对 baseline 更好的平衡了精确度和召回率,从而取得了更好的准确率和 F1 score。
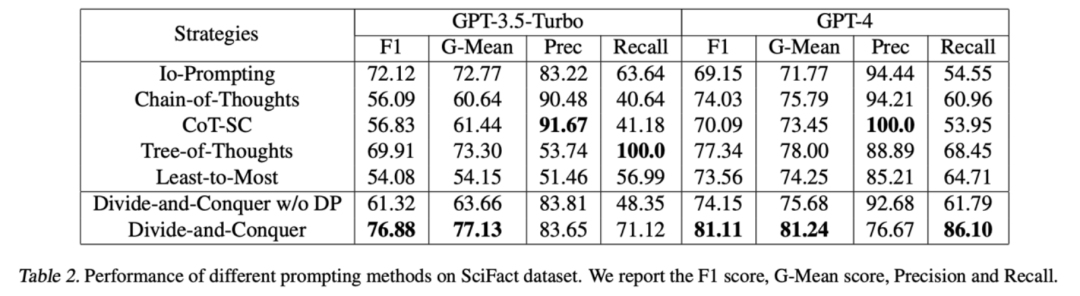
对于新闻验证,我们基于 SciFact 数据集构造了一个段落验证数据集。对于该数据集,模型需要根据一篇学术论文中的段落判断一段新闻报道是真新闻还是假新闻。我们将新闻报道划分为单句并分别进行检测。
检测结果如下,可以看到,我们的方法相对 baseline 取得了更好的准确率和 G-Mean score。
引用
Merrill, W. and Sabharwal, A. The parallelism tradeoff: Limitations of log-precision transformers. Transactions of the Association for Computational Linguistics.
Feng, Guhao, et al. "Towards revealing the mystery behind chain of thought: a theoretical perspective." Advances in Neural Information Processing Systems 36 (2024).