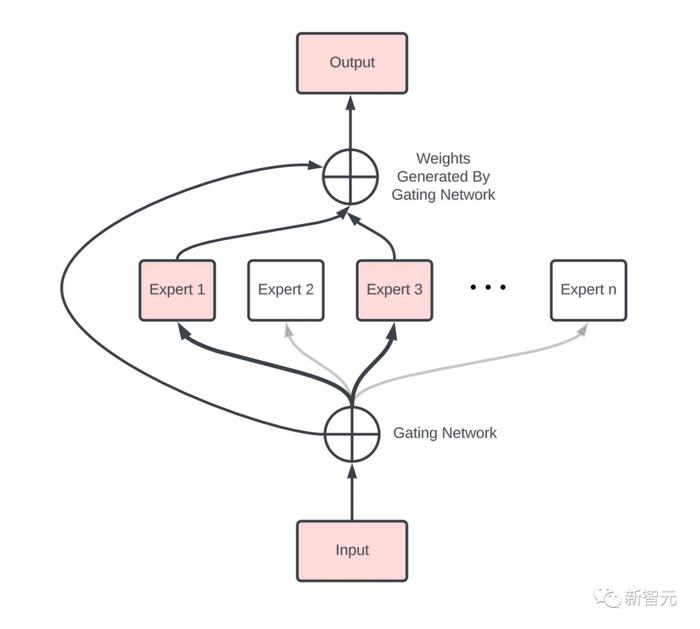
在机器学习领域,数据不平衡是一个常见的问题。数据不平衡指的是在训练数据集中,不同类别的样本数量存在明显的不均衡。例如,在二分类问题中,正样本和负样本的比例可能会相差很大。数据不平衡会对机器学习模型的性能和泛化能力产生负面影响。为了解决这个问题,研究人员提出了各种数据不平衡处理技术。本文将介绍数据不平衡处理技术在机器学习中的重要性,并讨论其应用和优势。
一、数据不平衡的影响
数据不平衡对机器学习模型的性能和泛化能力产生负面影响。在数据不平衡的情况下,模型倾向于偏向数量较多的类别,导致对数量较少的类别预测能力较差。例如,在医学诊断中,罕见疾病的样本数量往往较少,如果不处理数据不平衡,模型可能无法准确地识别罕见疾病。
二、数据不平衡处理技术
为了解决数据不平衡问题,研究人员提出了多种数据不平衡处理技术。这些技术可以分为两大类:基于采样的方法和基于算法的方法。
2.1 基于采样的方法
基于采样的方法通过对训练数据进行采样来平衡不同类别的样本数量。常见的基于采样的方法包括:
过采样:通过复制少数类别样本或生成合成样本来增加少数类别的样本数量。常用的过采样方法有SMOTE和ADASYN。
欠采样:通过删除多数类别样本来减少多数类别的样本数量。常用的欠采样方法有随机欠采样和集群中心欠采样。
2.2 基于算法的方法
基于算法的方法通过修改机器学习算法的损失函数或权重来处理数据不平衡。常见的基于算法的方法包括:
类别权重调整:通过调整不同类别样本的权重来平衡不同类别的重要性。常用的类别权重调整方法有加权交叉熵和FocalLoss。
阈值调整:通过调整分类阈值来平衡不同类别的预测结果。常用的阈值调整方法有ROC曲线和PR曲线。
三、数据不平衡处理技术的优势
数据不平衡处理技术具有以下优势:
提高模型性能:通过处理数据不平衡,可以提高模型对少数类别的预测能力,从而提高整体模型的性能。
改善模型泛化能力:数据不平衡处理技术可以减少模型对多数类别的过拟合,提高模型的泛化能力。
增加模型稳定性:数据不平衡处理技术可以减少模型对数据分布变化的敏感性,增加模型的稳定性。
综上所述,数据不平衡是机器学习中常见的问题,会对模型的性能和泛化能力产生负面影响。为了解决这个问题,研究人员提出了多种数据不平衡处理技术,包括基于采样的方法和基于算法的方法。这些技术可以提高模型的性能、改善模型的泛化能力,并增加模型的稳定性。在实际应用中,选择合适的数据不平衡处理技术需要考虑数据集的特点和具体问题的需求。