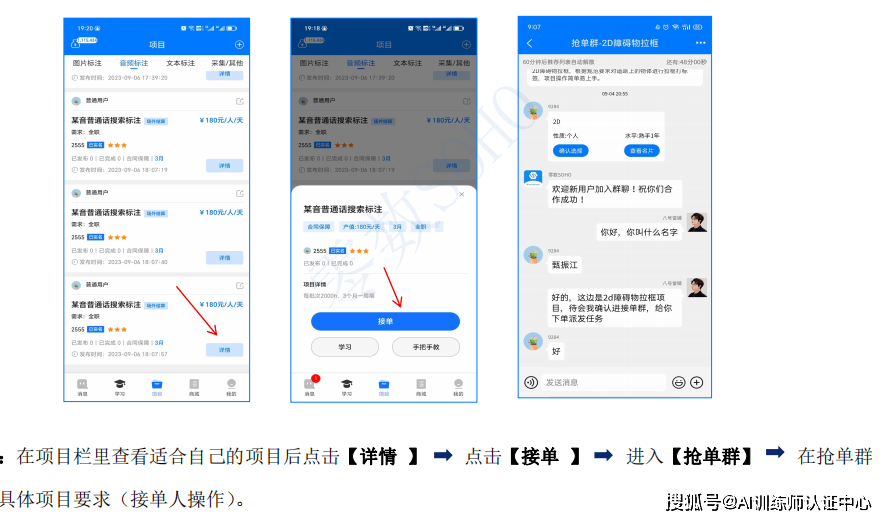
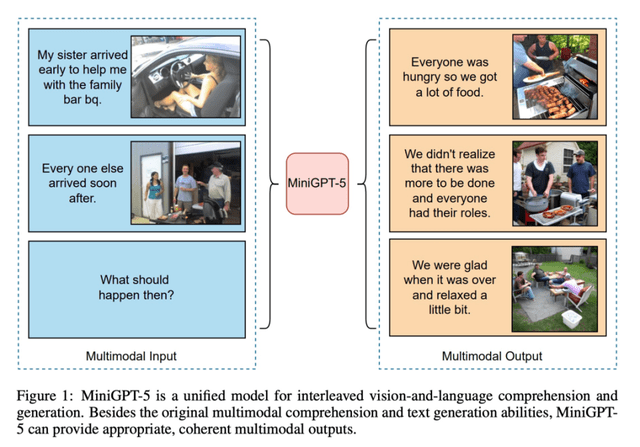
近年来,自然语言处理(NaturalLanguage Processing,NLP)领域取得了长足的进步,其中NLP通用模型成为了关注的焦点。作为一种能够完成多个NLP任务的通用预训练语言模型,NLP通用模型引领了NLP技术的发展潮流。本文将深入介绍NLP通用模型的基本概念、原理以及应用,一起来看看吧。
NLP通用模型,全称为自然语言处理通用模型(NaturalLanguage Processing GeneralModel),是一种具备广泛适应性的预训练语言模型。它通过大规模语料库的预训练,在多个NLP任务上展现出卓越的性能和可迁移能力。与传统的单一任务模型相比,NLP通用模型可以同时处理诸如文本分类、机器翻译、命名实体识别等多样的任务。
NLP通用模型的核心原理是基于Transformer架构的预训练和微调方法。首先,通过大规模无监督的语料库进行预训练,使模型能够捕捉到文本中的隐含信息和语言结构。在预训练阶段,通用模型以自编码器的方式完成对上下文的理解和特征提取。
接下来,通过微调阶段,将通用模型应用到具体的任务中。在微调过程中,通过有监督的学习方式,使用带标签的数据对模型进行继续训练,使其适应特定任务的要求。通过这种方式,NLP通用模型可以利用大规模预训练所获得的丰富知识,为各类NLP任务提供强大的预测和推断能力。
NLP通用模型的优势在于两个方面:
高效性:传统的NLP模型需要针对不同任务进行独立的训练,而NLP通用模型只需进行一次大规模的预训练,然后可以直接应用于多个任务中。这使得模型的开发和部署更加高效,并且能够更快地适应新的任务需求。
可迁移性:NLP通用模型在多个任务上展现出良好的迁移能力。它可以将在一个任务上学到的知识和模式迁移到其他任务中,无需重新训练或调整网络结构。这种可迁移性使得NLP通用模型成为解决不同领域和问题的有力工具。
第四部分:NLP通用模型的应用场景
NLP通用模型在各个领域都有广泛的应用。以下是几个典型的应用场景:
文本分类:通过学习大量文本数据,NLP通用模型可以自动识别和分类文本内容,辅助信息检索、情感分析等任务。
机器翻译:NLP通用模型可以将源语言翻译成目标语言,实现高质量的机器翻译,为跨语言交流提供便利。
命名实体识别:通用模型可以从文本中识别出人名、地名、机构名等具有特定意义的实体,对实体关系分析和信息提取等任务具有重要意义。
总之,NLP通用模型作为一种能够完成多个NLP任务的通用预训练语言模型,拥有广泛的应用前景和研究价值。它以其高效性和可迁移性,正在推动NLP技术的快速发展,并为我们带来更多便捷和智能的自然语言处理应用。随着科技的不断进步,我们有理由相信NLP通用模型将在未来继续发挥重要作用,引领着智能化时代的语言处理技术