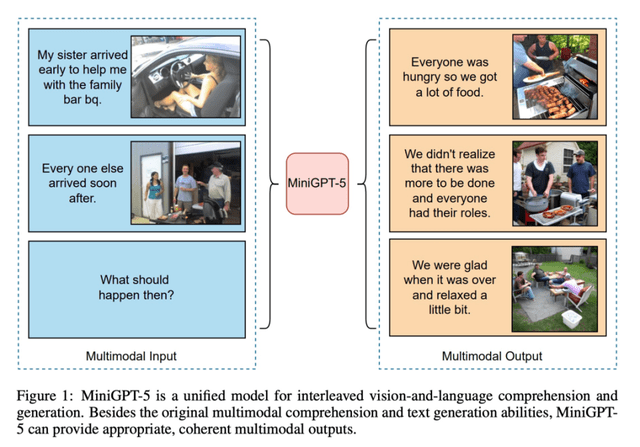
大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列
2018 年谷歌发布了 BERT,一经面世便一举击败 11 个 NLP 任务的 State-of-the-art (Sota) 结果,成为了 NLP 界新的里程碑; BERT 的结构如下图所示, 左边是 BERT 模型预训练过程, 右边是对于具体任务的微调过程。其中, 微调 阶段是后续用于一些下游任务的时候进行微调, 例如: 文本分类, 词性标注, 问答系统等, BERT 无需调整结构 就可以在不同的任务上进行微调。通过”预训练语言模型 + 下游任务微调”的任务设计, 带来了强大的模型效 果。从此,“预训练语言模型 + 下游任务微调”便成为了 NLP 领域主流训练范式。
 BERT 结构图,左边是预训练过程,右边是具体任务微调过程
BERT 结构图,左边是预训练过程,右边是具体任务微调过程
但是, 以 GPT3 为代表的大规模语言模型(LLM) 参数规模变得越来越大, 这使得在消费级硬件上进行全量 微调变得不可行。下表展示了在一张 A100 GPU (80G 显存) 以及 CPU 内存 64GB 以上的硬件上进行模型全量 微调以及参数高效微调对于 CPU/GPU 内存的消耗情况。
 全量参数微调与参数高效微调显存占用对比
全量参数微调与参数高效微调显存占用对比
除此之外, 模型全量微调还会损失多样性, 存在灾难性遗忘的问题。因此, 如何高效的进行模型微调就成了业界研究的重点,这也为参数高效微调技术的快速发展带来了研究空间。
参数高效微调是指微调少量或额外的模型参数, 固定大部分预训练模型(LLM) 参数, 从而大大降低了计 算和存储成本, 同时, 也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调 效果更好,可以更好地泛化到域外场景。
高效微调技术可以粗略分为以下三大类,如下图所示:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。 而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
常见的参数高效微调技术有 BitFit 、Prefix Tuning 、Prompt Tuning 、P-Tuning 、Adapter Tuning 、LoRA 等, 后 面章节将对一些主流的参数高效微调方法进行讲解。
 常见的参数高效微调技术和方法
常见的参数高效微调技术和方法
BitFit/Prefix/Prompt 微调系列
BitFit
虽然对每个任务进行全量微调非常有效, 但它也会为每个预训练任务生成一个独特的大型模型, 这使得很 难推断微调过程中发生了什么变化,也很难部署,特别是随着任务数量的增加,很难维护。
理想状况下,我们希望有一种满足以下条件的高效微调方法:
上述的问题取决于微调过程能多大程度引导新能力的学习以及暴露在预训练 LM 中学到的能力。虽然, 之 前的高效微调方法 Adapter-Tuning 、Diff-Pruning 也能够部分满足上述的需求。一种参数量更小的稀疏的微调方 法 BitFit 可以满足上述所有需求。
BitFit 是一种稀疏的微调方法, 它训练时只更新 bias 的参数或者部分 bias 参数。对于 Transformer 模型而言, 冻结大部分 transformer-encoder 参数, 只更新 bias 参数跟特定任务的分类层参数。涉及到的 bias 参数有 attention 模块中计算 query,key,value 跟合并多个 attention 结果时涉及到的bias,MLP 层中的bias,Layernormalization 层的 bias 参数,预训练模型中的bias参数如下图所示。
 图片
图片
PLM 模块代表了一个特定的 PLM 子层, 例如注意力或 FFN,图中橙色块表示可训练的提示向量, 蓝色 块表示冻结的预训练模型参数
在 Bert-Base/Bert-Large 这种模型里, bias 参数仅占模型全部参数量的 0.08%~0.09%。但是通过在 Bert-Large 模型上基于 GLUE 数据集进行了 BitFit、Adapter 和 Diff-Pruning 的效果对比发现, BitFit 在参数量远小于Adapter、 Diff-Pruning 的情况下,效果与 Adapter 、Diff-Pruning 想当,甚至在某些任务上略优于 Adapter 、Diff-Pruning。
通过实验结果还可以看出, BitFit 微调结果相对全量参数微调而言, 只更新极少量参数的情况下, 在多个数 据集上都达到了不错的效果, 虽不及全量参数微调, 但是远超固定全部模型参数的 Frozen 方式。同时, 通过对 比 BitFit 训练前后的参数, 发现很多 bias 参数并没有太多变化(例如:跟计算 key 所涉及到的 bias 参数)。发现 计算 query 和将特征维度从 N 放大到 4N 的 FFN 层(intermediate) 的 bias 参数变化最为明显, 只更新这两类 bias 参数也能达到不错的效果,反之,固定其中任何一者,模型的效果都有较大损失。
Prefix Tuning
在 Prefix Tuning 之前的工作主要是人工设计离散的模版或者自动化搜索离散的模版。对于人工设计的模版, 模版的变化对模型最终的性能特别敏感, 加一个词、少一个词或者变动位置都会造成比较大的变化。而对于自动 化搜索模版, 成本也比较高;同时, 以前这种离散化的 token 搜索出来的结果可能并不是最优的。除此之外, 传 统的微调范式利用预训练模型去对不同的下游任务进行微调, 对每个任务都要保存一份微调后的模型权重, 一 方面微调整个模型耗时长;另一方面也会占很多存储空间。基于上述两点, Prefix Tuning 提出固定预训练 LM,为LM 添加可训练, 任务特定的前缀, 这样就可以为不同任务保存不同的前缀, 微调成本也小; 同时, 这种 Prefix 实际就是连续可微的 Virtual Token (Soft Prompt/Continuous Prompt),相比离散的 Token ,更好优化,效果更好。
那么 prefix 的含义是什么呢?prefix 的作用是引导模型提取 x 相关的信息, 进而更好地生成 y。例如, 我们 要做一个 summarization 的任务, 那么经过微调后, prefix 就能领悟到当前要做的是个“总结形式”的任务, 然后 引导模型去 x 中提炼关键信息;如果我们要做一个情感分类的任务, prefix 就能引导模型去提炼出 x 中和情感相 关的语义信息,以此类推。这样的解释可能不那么严谨,但大家可以大致体会一下 prefix 的作用。
Prefix Tuning 是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 PLM 中的其他部分参数固定。针对不同的模型结构,需要构造不同的 Prefix:
- 针对自回归架构模型:在句子前面添加前缀, 得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况 下去引导生成下文(比如:GPT3 的上下文学习)。
- 针对编码器-解码器架构模型:Encoder 和 Decoder 都增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder 端增加前缀是为了引导输入部分的编码, Decoder 端增加前缀是为了引导后续 token 的生成。
 图片
图片
上部分的微调更新所有 Transformer 参数(红色框),并且需要为每个任务存储完整的模型副本。下部分 的 Prefix Tuning 冻结了 Transformer 参数并且只优化前缀(红色框)
该方法其实和构造 Prompt 类似, 只是 Prompt 是人为构造的“显式”的提示, 并且无法更新参数, 而 Prefix 则是可以学习的“隐式”的提示。同时,为了防止直接更新 Prefix 的参数导致训练不稳定和性能下降的情况,在 Prefix 层前面加了 MLP 结构, 训练完成后, 只保留 Prefix 的参数。除此之外, 通过消融实验证实, 只调整 embedding 层的表现力不够,将导致性能显著下降,因此,在每层都加了 prompt 的参数,改动较大。
Prefix Tuning 虽然看起来方便,但也存在以下两个显著劣势:
Prompt Tuning
大模型全量微调对每个任务训练一个模型, 开销和部署成本都比较高。同时, 离散的 prompts (指人工设计 prompts 提示语加入到模型) 方法, 成本比较高, 并且效果不太好。Prompt Tuning 通过反向传播更新参数来学习 prompts,而不是人工设计 prompts;同时冻结模型原始权重, 只训练 prompts 参数, 训练完以后, 用同一个模型 可以做多任务推理。
 图片
图片
模型调整需要为每个任务制作整个预训练模型的特定任务副本下游任务和推理必须在分开批次。Prompt Tuning 只需要为每个任务存储一个小的特定于任务的提示,并且使用原始预训练模型启用混合任务推理。
Prompt Tuning 可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的 Prompt,然后拼接到数据 上作为输入,但只在输入层加入 prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。
通过实验发现,随着预训练模型参数量的增加,Prompt Tuning 的方法会逼近全参数微调的结果。同时, Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch) 里同时训练同一个任务的不同 prompt (即采用 多种不同方式询问同一个问题) ,这样相当于训练了不同模型, 比模型集成的成本小多了。除此之外, Prompt Tuning 论文中还探讨了 Prompt token 的初始化方法和长度对于模型性能的影响。通过消融实验结果发现, 与随机 初始化和使用样本词汇表初始化相比, Prompt Tuning 采用类标签初始化模型的效果更好。不过随着模型参数规 模的提升, 这种 gap 最终会消失。Prompt token 的长度在 20 左右时的表现已经不错(超过 20 之后, 提升Prompt token 长度, 对模型的性能提升不明显了),同样的, 这个 gap 也会随着模型参数规模的提升而减小(即对于超大 规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响)。