大规模语言模型--提示学习和语境学习
有监督微调 (Supervised F.NETuning, SFT) 又称指令微调 (Instruction Tuning) ,是指在已经训练好的语言模型 的基础上, 通过使用有标注的特定任务数据进行进一步的微调, 从而使得模型具备遵循指令的能力。经过海量 数据预训练后的语言模型虽然具备了大量的“知识”,但是由于其训练时的目标仅是进行下一个词的预测, 此时 的模型还不能够理解并遵循人类自然语言形式的指令。为了能够使得模型具有理解并响应人类指令的能力, 还 需要使用指令数据对其进行微调。指令数据如何构造, 如何高效低成本地进行指令微调训练, 以及如何在语言 模型基础上进一步扩大上下文等问题是大语言模型在有监督微调阶段所关注的核心。
在指令微调大模型的方法之前, 如何高效地使用预训练好的基座语言模型是学术界和工业界关注的热点。提 示学习逐渐成为大语言模式使用的新范式。与传统的微调方法不同, 提示学习基于语言模型方法来适应下游各 种任务, 通常不需要参数更新。然而, 由于所涉及的检索和推断方法多种多样, 不同模型、数据集和任务都有不同的预处理要求, 提示学习的实施十分复杂。下面介绍提示学习的大致框架, 以及基于提示学习演化而来的语境学习方法。
提示学习
提示学习 (Prompt-based Learning) 不同于传统的监督学习, 它直接利用了在大量原始文本上进行预训练的语言模型, 并通过定义一个新的提示函数, 使得该模型能够执行小样本甚至零样本学习, 以适应仅有少量标注或 没有标注数据的新场景。
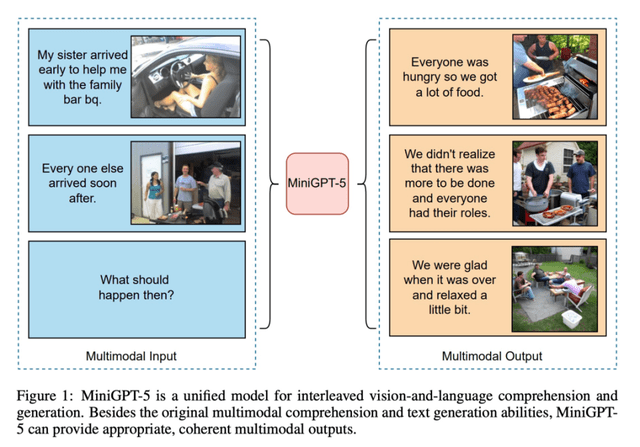
使用提示学习来完成预测任务的流程非常简洁, 如下图所示, 原始输入 x 经过一个模板, 被修改成一个带 有一些未填充槽的文本提示 x‘ ,然后将这段提示输入语言模型, 语言模型即以概率的方式填充模板中待填充的 信息, 然后根据模型的输出即可导出最终的预测标签 。使用提示学习完成预测的整个过程可以描述为三个阶段: 提示添加、答案搜索、答案映射。

提示学习示例
1. 提示添加: 在这一步骤中, 需要借助特定的模板, 将原始的文本和额外添加的提示拼接起来, 一并输入 到语言模型中。例如,在情感分类任务中,根据任务的特性,可以构建这样的含有两个插槽的模板:
“[X] 我感到 [Z]”,
其中 [X] 插槽中填入待分类的原始句子, [Z] 插槽中为需要语言模型生成的答案。假如原始文本
x = “我不小心错过了公共汽车。”,
通过此模板,整段提示将被拼接成
x’= “我不小心错过了公共汽车。我感到 [Z]”。
2. 答案搜索: 将构建好的提示整体输入语言模型后, 需要找出语言模型对 [Z] 处预测得分最高的文本 zˆ。根 据任务特性, 可以事先定义预测结果 z 的答案空间为 Z。在简单的生成任务中, 答案空间可以涵盖整个语言, 而 在一些分类任务中,答案空间可以是一些限定的词语,例如
Z= “太好了”,“好”,“一般”,“不好”,“糟糕”,
这些词语可以分别映射到该任务的最终的标签上。将给定提示 x’而模型输出为 z 的过程记录为函数 ffill(x‘, z), 对于每个答案空间中的候选答案,分别计算模型输出它的概率, 从而找到模型对 [Z] 插槽预测得分最高的输出:

3. 答案映射: 得到的模型输出 zˆ 并不一定就是最终的标签。在分类任务中, 还需要将模型的输出与最终的 标签做映射。而这些映射规则是人为制定的, 比如, 将“太好了”、“好”映射为“正面”标签, 将“不好”、“糟 糕”映射为“负面”标签,将“一般”映射为“中立”标签。

此外, 由于提示构建的目的是找到一种方法, 从而使语言模型有效地执行任务, 并不需要将提示仅限制为 人类可解释的自然语言。因此, 也有研究连续提示的方法, 即软提示 (SoftPrompt)),其直接在模型的嵌入空间中 执行提示。具体来说, 连续提示删除了两个约束: (1) 放松了模板词的嵌入是自然语言词嵌入的约束。 (2) 模板不 再受限于语言模型自身参数的限制。相反,模板有自己的参数,可以根据下游任务的训练数据进行调整。
提示学习方法易于理解且效果显著, 提示工程、答案工程、多提示学习方法、基于提示的训练策略等已经成 为从提示学习衍生出的新的研究方向。
语境学习
语境学习 (IncontextLearning,ICL),也称上下文学习, 其概念最早随着 GPT-3 的诞生而提出。语境学习是指 模型可以从上下文中的几个例子中学习:向模型输入特定任务的一些具体例子 (也称示例 (Demonstration)) 以及 要测试的样例, 模型可以根据给定的示例续写出测试样例的答案。如下图所示, 以情感分类任务为例, 向模型 中输入一些带有情感极性的句子、每条句子相应的标签、以及待测试的句子, 模型可以自然地续写出它的情感 极性为“Positive”。语境学习可以看作是提示学习的一个子类, 其中示例是提示的一部分。语境学习的关键思想是从类比中学习, 整个过程并不需要对模型进行参数更新, 仅执行向前的推理。大语言模型可以通过语境学习执行许多复杂的推理任务。

ICL 的关键思想是从任务相关的类比样本中学习。上图给出了一个描述语言模型如何使用 ICL 进行情感分类任务的例子。
-
首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。
-
然后,ICL 将查询的问题(即你需要预测标签的输入)和一个上下文演示(一些相关的示例)连接在一起,形成带有提示的输入,与监督学习需要使用反向梯度更新模型参数的训练阶段不同,ICL 不进行参数更新,而是直接在预训练的语言模型上进行预测。模型预计将从演示中学习到的模式进行正确的预测。
-
最后,利用训练有素的语言模型根据演示的示例来估计候选答案的可能性。简单理解,就是通过若干个完整的示例,让语言模型更好地理解当前的任务,从而做出更加准确的预测。
语境学习作为大语言模型时代的一种新的范式, 具有许多独特的优势。
-
首先, 其示例是用自然语言编写的, 这提供了一个可解释的界面来与大语言模型进行交互,可以让我们更好地跟语言模型交互,通过修改模版和示例说明我们想要什么,甚至可以把一些知识直接输入给模型,通过这些示例跟模版让语言模型更容易利用到人类的知识。
-
其次, 不同于以往的监督训练, 语境学习本身无需参数 更新, 这可以大大降低使得大模型适应新任务的计算成本,更容易应用到更多真实场景的任务。
语境学习作为一种新兴的方法, 其作用机制仍有待深入研究。
-
1.语境学习中示例的标签正确性 (即输入和输出的具体对应关系) 并不是使其行之有效的关键因素, 认为起到更重要作用的是输入和输入配对的格式、输入和输出分布等。
-
2.语境学习的性能对特定设置很敏感, 包括提示模板、上下文内示例的选择以及示例的顺序。如何通过语境学习方法更好的激活大模型已有的知识成为一个新的研究方向。