大模型激战正酣?“小模型”或许才是出路
图片来源@视觉中国
文 | 青橙财经,作者丨青沐编辑丨六子
7月26日,AI target=_blank class=infotextkey>OpenAI推出Android/ target=_blank class=infotextkey>安卓版ChatGPT,虽然目前仅限在美国、印度、孟加拉国和巴西四国使用,但OpenAI也表示,下周将在更多国家推广安卓版ChatGPT。这让近期热度稍降的ChatGPT重回大众视野。
ChatGPT在上线之初,用仅仅两个月的时间,就一跃成为历史上最快突破1亿用户的应用,沉寂了许久的全球科技市场再次沸腾,国内的投资人与创业者,纷纷飞往硅谷取经问道。
面对这一汹涌的AI浪潮,中国的创业者和投资人们行动很快。数月之后,中国科技行业已呈现“百模大战”的壮观姿态。2023年上半年,国内就已出现了80多个大模型产品,在最新的数据中,国内市场上已经有130家公司在做大模型。而在全球范围内,今年上半年新发布的大模型已超过400个。
中国的大模型玩家们在追逐商业利益和科技未来的同时,也被冠以民族情怀:做中国版的OpenAI。
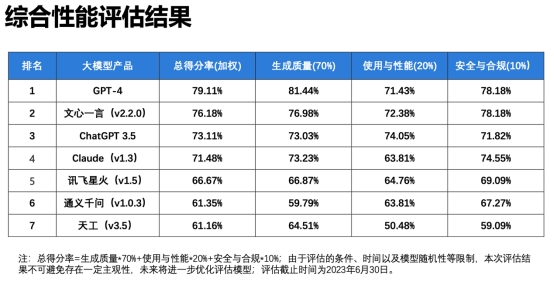
7月24日消息,安卓版ChatGPT上线前夕,IDC发布的大模型技术能力评估报告显示,百度文心大模型3.5拿下12项指标的7个满分,综合评分第一。百度副总裁吴甜表示,新版本的文心一言3.5能力已超越ChatGPT 3.5,这是在我们国内开展相关技术工作重要的里程碑。
科大讯飞则在此前就宣布,将在10月24日对星火大模型进行第三次迭代,全面对标ChatGPT,中文能力实现超越GPT3.5,英文能力与GPT3.5相当。
01 场景,场景
事实上,正如前google科学家、出门问问创始人兼CEO李志飞所说的那样,中国或许不会存在一个跟OpenAI一样的组织。
相比ChatGPT这种通用大模型,国内的大模型产品,更多注重应用和场景,即垂直大模型、行业大模型、产业大模型。对此,科技创投圈大佬们的意见几乎表达了同一个意思。
百度创始人李彦宏早就公开表示:“创业公司重新做一个ChatGPT其实没有多大意义。我觉得基于这种大语言模型开发应用机会很大,没有必要再重新发明一遍轮子,有了轮子之后,做汽车、飞机,价值可能比轮子大多了。”
金沙江创投董事总经理朱啸虎在朋友圈写道:“不要迷信通用大模型,因为明年GPT-3.5就成commodity(通用基础设施),而三年后,GPT-4也会是。对于大部分创业者,场景优先,数据为王!”
猎豹移动董事长兼CEO傅盛认为,大模型会分两条路。一条叫越来越牛的大模型,是“造一个爱因斯坦”。但很多工作岗位不需要“爱因斯坦”,大学毕业生就能做。这是另一条路。我相信一定有大量的人做“平民化大模型”。
华为云CEO张平安在盘古大模型3.0发布会上表示:“盘古大模型没有时间作诗和聊天。参数再多、对话能力做得再好,但如果解决不了实际问题,也没有多大用处。”
近期国内发布的大模型,大多都面向垂直产业落地,如京东发布的言犀大模型,携程发布的旅游行业垂直大模型“携程问道”,阅文集团发布的阅文妙笔大模型,网易有道发布的教育领域垂直大模型“子曰”等。
京东言犀大模型沉淀了京东在零售、物流、健康、金融等行业多年积累的知识,融合70%通用数据与30%京东数智供应链原生数据进行训练,带来了商品推荐、金融政策、理财规则、物流体验等领域的能力。京东云事业部总裁曹鹏认为,单一的大模型技术本身无法直接产生价值,技术只有放到场景里,才能产生实际价值。
携程旅游大模型问道筛选了200亿非结构性旅游数据,结合携程现有的结构性实时数据,以及携程历史训练的机器人和搜索算法,进行了自研垂直模型的训练,同时投入了巨大人力对旅行通用回复内容进行生成和校验。携程创始人、董事局主席梁建章表示,携程会不遗余力地为大模型投入,投资数额不设限。
在应用方面,百度近日与联想在AIGC领域达成合作,联想私人定制业务全面引入百度文心一格,消费者可通过官网 AIGC 主题绘画活动定制笔记本电脑外观。华为云盘古大模型与美图视觉大模型MiracleVision合作推出的AI模特试衣功能,可以有效提升服装类产品的电商上架效率。
垂直大模型虽然不如通用大模型那样对参数和算力有太高的要求,但对场景和数据有着更高的要求,需要开发者具备专业的知识、丰富的行业应用实践积累,对错误的容忍程度也更低,需要AI具备超强的稳定性和可靠性。所以越到垂直行业,垂直模型的优势也就更大。
“通用大模型可以在100个场景中,解决70%-80%的问题,但未必能100%满足企业某个场景的需求。企业如果基于行业大模型,再加上自身数据进行精调,可以建构专属模型,打造出高可用性的智能服务,而且模型参数比通用大模型少,训练和推理的成本更低,模型优化也更容易。”腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生表示。
从这个角度来说,“小模型”或许更性感,更能解决具体的问题。
商汤推出了千亿参数的大模型,也在推出针对不同垂直领域的百亿参数小模型。大模型的长处在于能够找到新的解法,帮助解决新问题,一旦解决以后可以在狭窄领域产生大量数据,重新训练小模型。有的小模型甚至可以跑在终端上,成本更低。但如果没有大模型,小模型也不会存在。
02 大厂赢家通吃,创业公司的机会在哪?
行业里有一种观点认为,中国版的ChatGPT只会在5家公司产生:百度、阿里、腾讯、字节、华为。
互联网时代,是典型的“721”,第一名吃香喝辣,第二名勉强生存,第三名往后朝不保夕。
眼下,百模混战,谁都想在大模型里分一杯羹。但有一个很现实的问题是,大厂做大模型,有着创业公司无法比拟的优势。小而美的创业公司,想靠三五个人就干翻大厂,大概率只是一种幻觉。
大模型离不开云平台。大模型落地需要不断进行微调、训练、都需要在云平台上运行。百度、阿里、腾讯、字节、华为都有自己的云业务,百度和华为还完成了从还完成了从芯片到应用的布局,百度是“昆仑芯+飞桨平台+文心大模型”,华为是“昇腾芯片+MindSpore框架+盘古大模型”,这都是创业公司难以企及的优势。
此外,在资金储备、人才资源、使用场景、数据积累方面,大公司都有着天然的优势。创业公司没有落地场景,技术就没法迭代,无法持续优化,无法形成数据网络效应。
那么小公司就一点机会都没有了吗?
不妨重提那个淘金时代的喻言:“这个时代跟淘金时代很像,如果你那个时候去加州淘金,一大堆人会死掉。但是卖勺子、卖铲子的人永远可以赚钱。”这也是奇绩创坛创始人兼CEO陆奇在近期对创业者的分享。陆奇希望帮助中国创业者认清这次历史性的拐点时刻,定位今天的时代坐标、找准自己的位置。
7月初,加州大学伯克利分校计算机科学教授、《人工智能——现代方法》作者斯图尔特·罗素(Stuart Russell)发出警告称,ChatGPT等人工智能驱动的机器人可能很快就会“耗尽宇宙中的文本”,通过收集大量文本来训练机器人的技术“开始遇到困难”。
上周,8500多名作家签署了一封信,要求OpenAI、微软、Meta和Alphabet等公司领导者不要在未经许可或未支付报酬的情况下使用这些作家的作品来训练人工智能系统,并要求这些人工智能公司赔偿其版权损失。
存量的互联网数据即将被耗尽,优质数据正变得越来越稀缺。一个模型的好坏,20%由算法决定,80%由数据质量决定。在数据、算力、算法“三驾马车”里,数据是最核心、最长远、最基础性的要素。大模型需要用海量数据进行喂养,才能持续优化、迭代。
接下来,真正的价值将会变成可持续性的高质量数据。如何持续获取合法合规、合商业逻辑的数据源,将成为大模型性能提升的关键因素。因此,数据运营商或将成为制约大模型发展的重要角色。
比较理想的状态是,模型不断为用户提供服务,用户不断为模型生成新的数据。至于下一步,则会拼私有数据。更个性化的服务,意味着需要更私有化的数据,而人类不太可能将私人化数据毫无保留地展示给大模型。
任何时代,“卖水人”永远是一门好生意。颇具意味的是,无论是开创者、探索者还是掘金者,都离不开水。当然也可以卖勺子、卖铲子。
03 结语
前几个月,社交平台上有一则帖子流传甚广:
把AI想象成一个小孩。欧美的AI属于精英教育路线,出生后家里就一路砸钱供他读书到博士,等到毕业后,一出场就王炸,惊艳全场。
中国的AI属于功利教育路线,出生就接受生存养育,养到15岁,就开始逼着他想办法给家里挣钱,学的都是如何市场化的技巧。
寥寥数语,细细品来,滋味万千。
虽然不一定对,但这或许也在某种程度上解释了OpenAI、ChatGPT为什么没有出现在中国。事实上,国内的一些投资人和创业者,在刚开始也是信心满满,要做中国版的OpenAI。在折腾了几个月后,发现还是要寻找盈利模式,探索业务应用场景和商业化的能力。
值得一提的是,近来部分C端用户感知到ChatGPT-4在某些任务上性能表现太差,这被认为是OpenAI使用混合专家模型(MOE)进行降本增效,将重心转向企业级服务的动作之一。
放眼望去,苹果也在研发自己的大语言模型Apple GPT,高通则已经在研究如何在今年底实现,让100亿-150亿参数级别的模型在手机上离线运行,无需云端处理运算。
大模型是生产力的重塑,是范式转换。200年前,人类用蒸汽机第一次把热能变成动能,工业化时代开启。今天,人类用大模型把电能转换成脑力和通用智力,一个新的时代正在开启。
轮子固然不需要太多,但我们仍然需要好用的轮子。
任重道远。