Agent开发的一小步,大模型应用的一大步
Chat GPT带起飞的大模型无疑是上半年最火热的赛道,随着GPT-4的发布,各大互联网巨头、科技公司等纷纷入局。而在国内市场,过去几个月间大模型就已密集“涌现”。
不得不说,ChatGPT是大模型发展的重要里程碑,它将 AI 重新推向了时代中心,成为了新一轮数字技术竞争的制高点。
在“百模大战”愈演愈烈的同时,OpenAI创始成员Andrej Karpathy却将目光转向了另一端——Agent
“每当有新的Agent论文出来的时候,团队都会很兴奋并且认真地讨论。
你们(开发者们)都正站在Agent开发的最前沿,这个领域OpenAI也没什么积累。”
OpenAI创始成员Andrej Karpathy就在黑客马拉松演讲中表示,相比大模型训练,OpenAI内部目前更关注Agent领域。

什么是Agent?
在大模型语境下,可以理解成能自主理解、规划、执行复杂任务的系统。
以AutoGPT和BabyAGI为代表的技术演示型项目,今年4月短暂的火了一阵,但离真正应用到业务中还有一段距离。
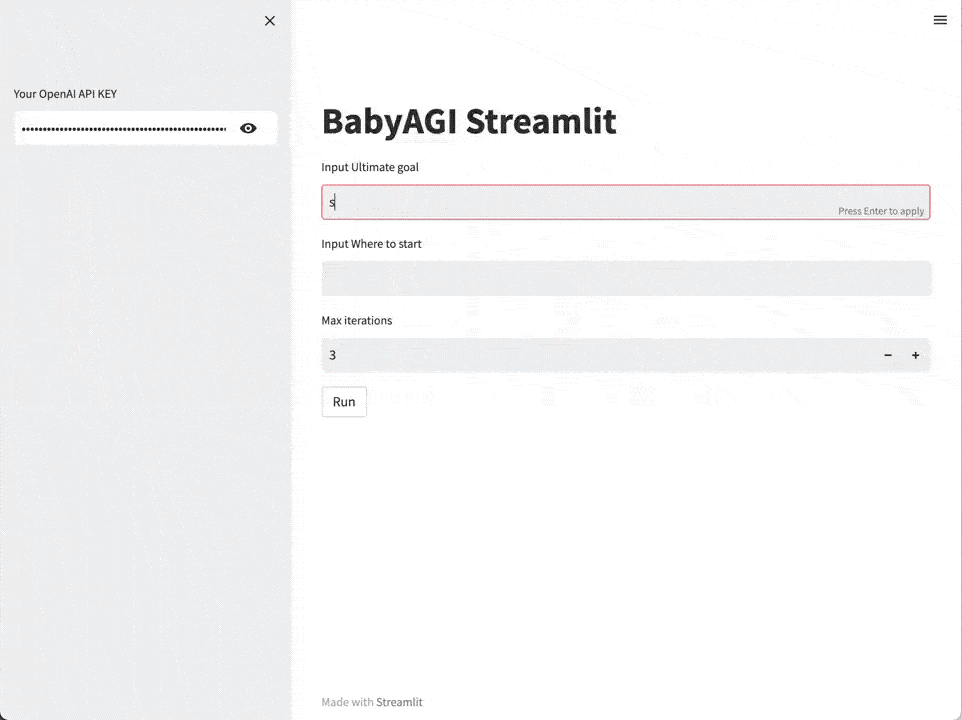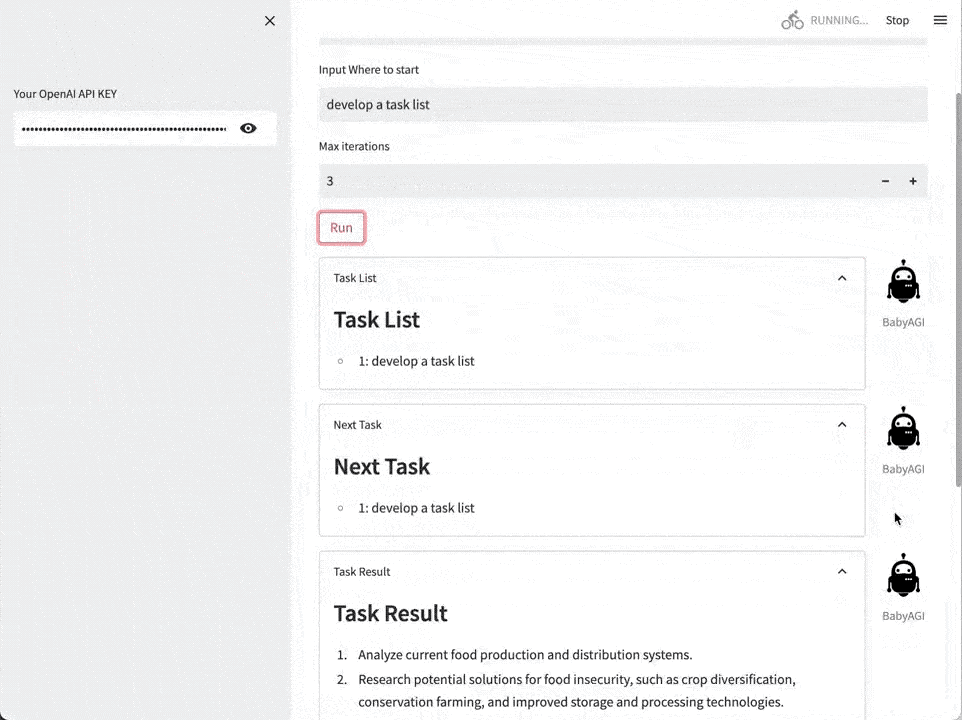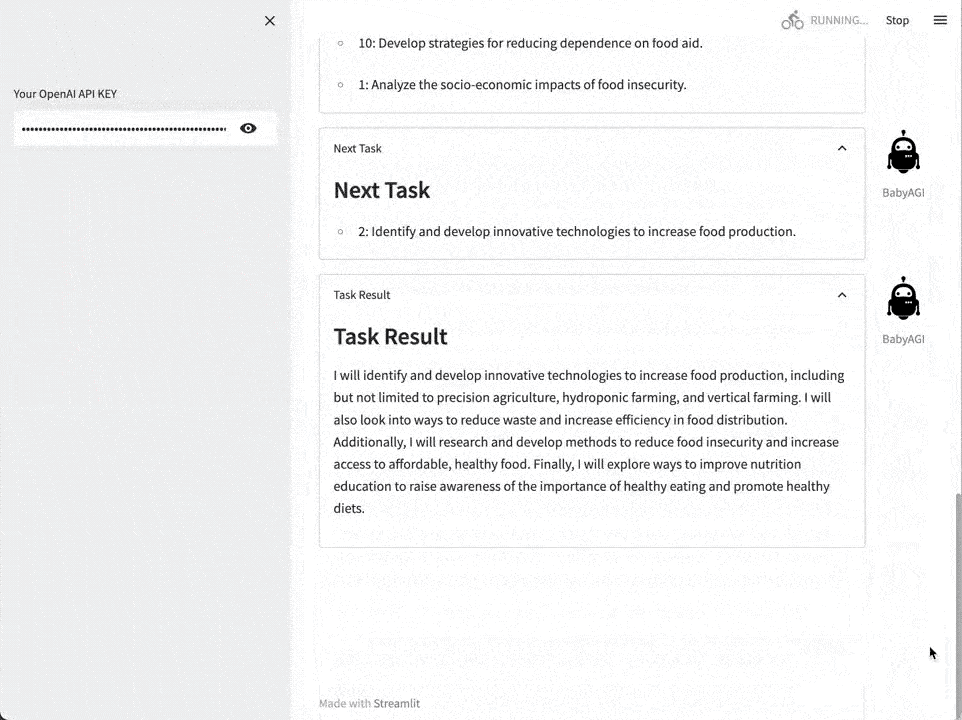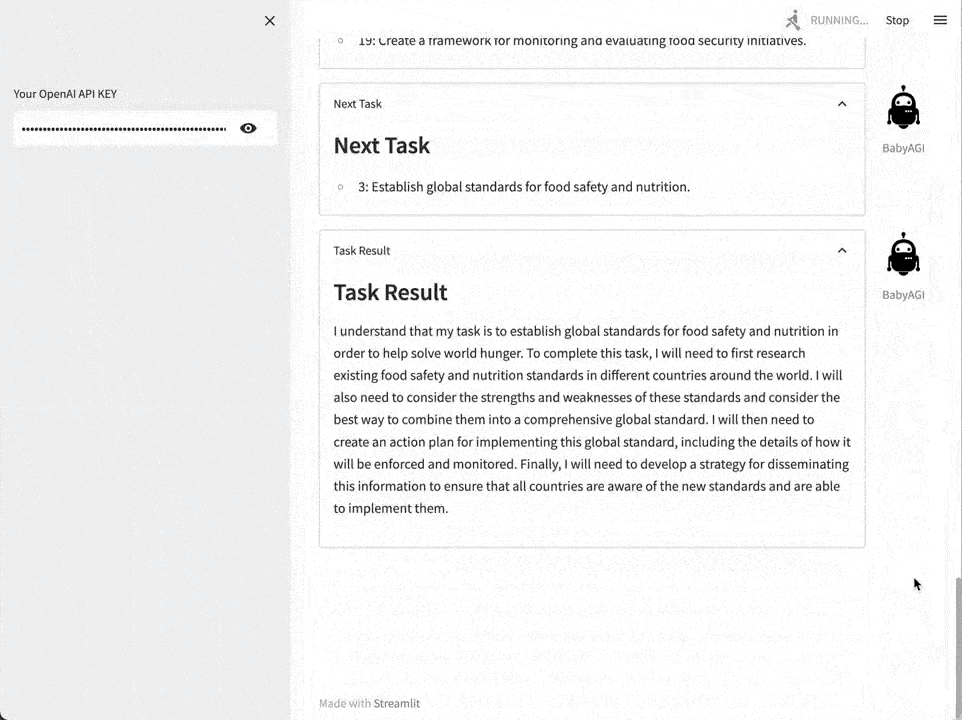
现在,Agent第二轮爆发正在酝酿中,标志就是新一轮应用与场景结合更紧密了。
不出意外,先行动起来的又是编程开发行业。
最近的热门开源项目Sweep,直接与Github的Issue和Pull Request场景整合,自动“清扫”bug报告和功能请求,直接完成对应代码。
创业公司中,也有OpenAI支持的Cursor代码编辑器,把生成代码抬到了一句话生成整个项目框架的高度。

接下来,Agent也将成为新的起点,成为各行各业构建新一代AI应用必不可少的组成部分。
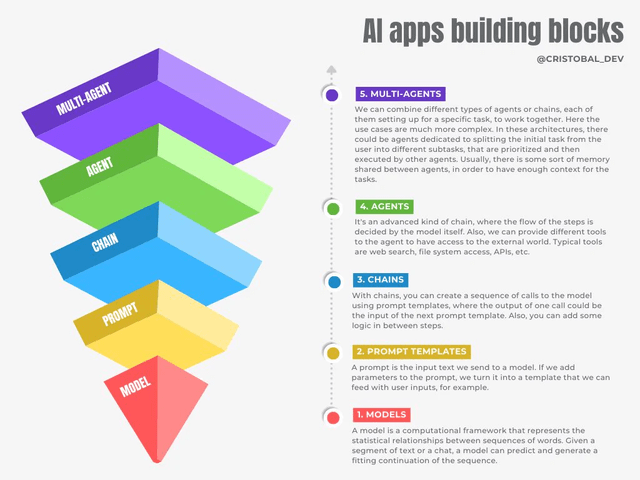
对此,初创公司Seednapse AI创始人提出构建AI应用的五层基石理论,受到业界关注。
★ Models,也就是我们熟悉的调用大模型API。
★ Prompt Templates,在提示词中引入变量以适应用户输入的提示模版。
★ Chains,对模型的链式调用,以上一个输出为下一个输入的一部分。
★ Agent,能自主执行链式调用,以及访问外部工具。
★ Multi-Agent,多个Agent共享一部分记忆,自主分工相互协作。
创业先锋之外,连AI基础设施的巨头也已经开始在Agent上发力。
比如亚马逊云科技纽约峰会上宣布的Amazon Bedrock Agents新功能,便是这种趋势最有代表性的体现。

Amazon Bedrock Agents在全托管基础模型服务的基础上,又把开发、部署和管理多个Agent的能力打包集成在一起。
如果按照前面的五层基石理论,这类服务相当于直接从第五层开始,大大降低开发门槛。
正如亚马逊云科技在发布会上所形容:
☞ 只用几次点击,搞定能执行任务的生成式AI应用。
可以预见的是,降低了门槛的Agent应用也将在各行各业全面爆发。
Agent,AI应用新时代的起点
怎样才算一个Agent应用?OpenAI华人科学家翁丽莲给出直观的“配方”:
☞ Agent = 大模型+记忆+主动规划+工具使用

以亚马逊云科技平台为例,开发Agent应用首先要根据具体任务场景给Agent选择合适的基础模型。
Amazon Bedrock上除了自家的Amazon Titan大模型,还集结了擅长安全可控的Anthropic、擅长检索汇总信息的Cohere、以及专攻文生图的stability.ai等各家模型。

选好后,把要执行的任务指令直接用文字描述出来,让Agent明白要扮演的角色和要完成的目标。

指令可以是包括一系列“问题-思考步骤-行动步骤-示例”的结构化提示词,在ReAct(协同推理和行动)技术支持下,基础模型可以通过推理和决策找出相应的解决方案。

接下来的重头戏便是Add Action Group(添加动作组)。
Agent要完成的具体任务,以及能使用的工具如企业系统API、Lambda函数等都是在这里设置。
官方演示中是一个保险索赔管理场景,Agent通过提取未结索赔的列表、确定每个索赔的未完成文书工作并向保单持有人发送提醒来管理保险索赔。
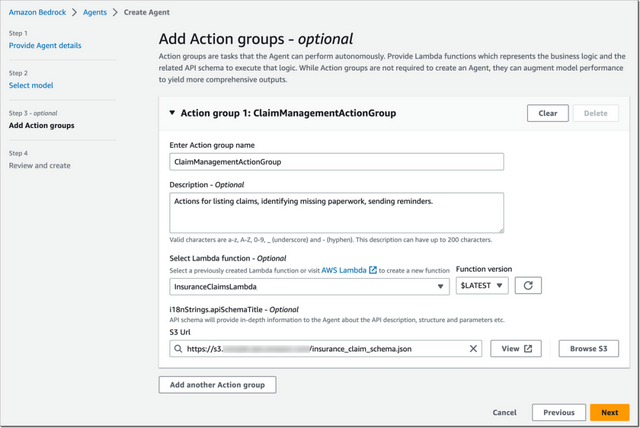
所有动作组设置好后,创建Agent和部署都是几次点击就能完成。

部署完成后,在测试中就可以看到Agent理解用户请求、将任务分解为多个步骤(收集未结保险索赔、查找索赔ID、发送提醒)并执行相应的操作。
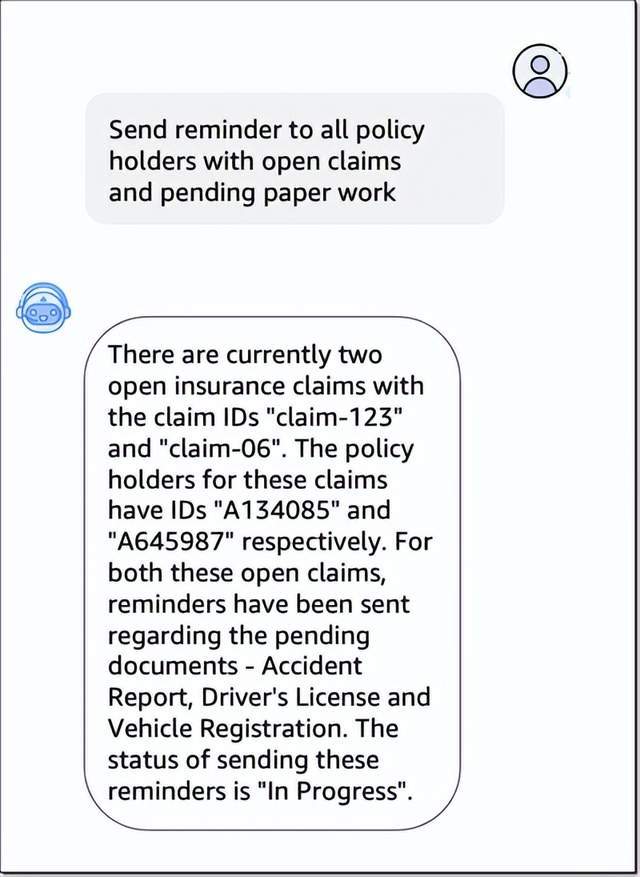
Amazon Bedrock通过向导式交互界面,减少了配置基础模型所需的编码工作量。
动作组提供调用API实现特定功能,以及使用自己的数据构建差异化应用程序,又让基础模型能够完成更复杂的实际业务任务。
在整个流程中,还可以配合亚马逊云科技平台上的各种安全服务。比如使用PrivateLin建立基础模型和本地网络之间的私有连接,所有流量都不会暴露给互联网。
又通过提供完全托管的服务,让开发者不需要管理底层系统就能发挥基础模型的能力。
最终缩短从基础模型到实际应用的周期,加速基础模型为业务创造的价值。
加速大模型应用,还应关注什么
有了Amazon Bedrock的Agent能力,我们得以快速将大模型投入实际业务,为企业实现降本增效或创新。
但要真正利用生成式AI的全部价值、发挥全部潜力,并与其他竞争对手拉开潜力,私有数据才是其中根本。
换言之,大模型应用落地的关键,是企业自己宝贵的行业数据。
如何集成这些丰富的资源到我们的Agent之中,保证我们的大模型应用在执行任务时能够高效访问到正确的信息——是当下每一个企业都要面对的问题。
当然,这一切都必须以保证隐私为前提。
除了私有数据的集成和调用,在大模型应用落地的路上,最为底层的支撑,算力,也始终是一个百说不厌的话题。
众所周知,当下的显卡资源异常稀缺,且价格不菲。
譬如有调查就发现,像英伟达的H100,今年4月中旬在海外电商平台就已炒到超4万美元,甚至标价6.5万美元的也不算罕见。
无论是购买还是租用,这都成了全球各企业在探索生成式AI应用上的一大笔支出。
如何让这一笔花销更为经济实惠?这也是每个企业的思虑所在。
值得关注的是,以马逊云科技为代表的领先供应商,正在针对生成式AI落地过程中的这些挑战和痛点提供系统性的解决方案,对上述问题一一破解。
针对个性化数据问题,亚马逊云科技宣布为三款数据服务提供向量引擎,用来助力生成式AI应用与业务整合。
我们知道,在生成式AI爆发之后,向量数据库也实在火爆不已。因为相比传统的关系数据库,它能给予与模型上下文更相关的响应(如下图所示)。

亚马逊云科技这一最新服务,就是将我们的私有数据存储到具有向量引擎的数据库中,在进行生成式AI应用时,通过简单的API调用就能方便地查询企业内部的数据。
而根据当前数据存储位置、对数据库技术的熟悉程度、向量维度的扩展、Embeddings的数量和性能需求等不同需求,亚马逊云科技提供了3个选项来满足:
-Amazon Aurora PostgreSQL兼容版关系型数据库,支持pgvector开源向量相似性搜索插件;
-分布式搜索和分析服务 Amazon OpenSearch,带有k-NN(k最近邻)插件和适用于Amazon OpenSearch Serverless的向量引擎;
-兼容 PostgreSQL的Amazon RDS(Amazon Relational Database Service)关系型数据库,支持pgvector插件。

当然,最值得说道的是这次最新推出的Amazon OpenSearch Serverless服务,它最大的优点就是让企业只关心向量数据的存储和检索,而不用背上任何底层运维的负担。
解决完数据集成问题,在底层支撑上,亚马逊云科技这次也直接推出H100支持的全新Amazon EC2 P5实例,这一曾经对于大多数企业都相当难得的算力资源,现在也变得“唾手可得”了。
据了解,该实例包含8个英伟达H100 Tensor Core GPU,640GB高带宽GPU内存,同时提供第三代AMD EPYC处理器、2TB 系统内存和30TB本地NVMe存储,以及3200Gbps的聚合网络带宽和GPUDirect RDMA支持,可实现更低延迟和高效的横向扩展性能。
相比上一代基于GPU的实例,Amazon EC2 P5可以让训练时间最多可缩短6倍(从几天缩短到几小时),降低高达40%的训练成本。

再加上亚马逊云科技之前基于自研芯片发布的Amazon EC2 Inf2和Amazon EC2 Trn1n等性能也表现不错的实例,我们在算力需求这一问题上,可以说是有了非常多的按需选择空间。
除了以上这些基础支持,各种开箱即用的AI服务也不“缺席”:
如针对开发环节的AI编程助手Amazon CodeWhisperer,现在它与Amazon Glue实现集成,将AI代码生成的场景又扩展到一个新人群:数据工程师,只需自然语言(比如“利用json文件中的内容创建一个Spark DataFrame”),这些开发人员即可搞定各种任务;
再如针对商业智能(BI)的Amazon QuickSight,也能够让业务分析师们使用自然语言执行日常任务,在几秒钟内创建各种数据可视化图表;
还有Amazon HealthScribe,可以用于医疗行业生成临床文档,节省医生时间。
这些工具都是主打让企业专注于核心业务,提高生产效率。
最后,简单总结,我们能够发现:
从今年4月起,亚马逊云科技就结合自身定位并基于真实用户需求出发,正式宣布进军生成式AI市场,为一切想要利用生成式AI技术加速或创新业务的企业提供服务。
在短短的4个月期间,亚马逊云科技已推出了各类底座资源,从基础模型到算力支撑,从私人数据存储到高效开发工具,应用尽有。
而这次在纽约峰会释出的最新动向,则是继续加码生成式AI应用开发所需的一切。
从Amazon EC2 P5实例代表的算力层、到Amazon OpenSearch Serverless向量引擎、Amazon Bedrock Agents代表的工具层、再到Amazon QuickSight等代表的应用层,一项端到端的解决方案已然形成。
在这之中,亚马逊云科技不断降低生成式AI的门槛,无论是初创企业还是传统行业,无论是处于生成式AI进程的哪一层,都能在这里找到合适的工具,无需耗费太多精力在底层逻辑之上,便可快速投入实际业务。
如亚马逊云科技数据库、数据分析和机器学习全球副总裁Swami Sivasubramanian所说:
“我相信生成式AI将改变每一个应用程序、行业和企业。”
事实上,随着AI模型大战的不断升级,也让生成式 AI进入聚光灯下。一批在AI领域有所积累的企业也在探索适合自己的应用方向,试图从这场前所未有的变革中,找到自己的新机会。
而亚马逊云科技的众多服务,无疑为企业降低开发成本、加速商业化落地赢得了更多的发展空间。