OpenAI 创始人最新演讲:ChatGPT 炸裂新功能,分享怎样教 AI 使用工具
以下文章来源于Founder Park ,作者Founder Park
AI target=_blank class=infotextkey>OpenAI 的联合创始人,三位核心成员之一的 Greg Brockman 日前在 TED2023 上发表演讲,过程中演示了足以取代上周爆火的 AutoGPT 的新功能,还有 OpenAI 在人机协作方面的思考和进展。
以下是演讲内容,经 Founder Park 编辑整理。
七年前,我们创办了 OpenAI。因为人工智能领域正在发生一些非常有趣的事,我们想引导它向积极的方向发展。
从那天到现在,整个领域取得了难以置信的进展,令人惊叹。
人们为之兴奋,也为之担忧。这也是我们所感受到的。
最重要的是,我们似乎正在进入一个历史性时期,全世界都在定义一个对人类社会的未来至关重要的技术。
我相信我们可以善加引用这项技术。
今天我想向你们展示的,就是这项技术最新的进展,以及一些我们一直秉承的基本设计原则。
01
教会 AI 使用工具
首先,我想展示,如何为 AI 开发工具,而不是为人类开发工具。
Greg 展示了如何用 ChatGPT 策划一顿晚饭,用 Dall-E 绘制出来,用第三方插件列出制作这顿晚饭的菜单,并发布到推特上。
所有这些动作,都由 ChatGPT 自动完成,但用户又可以在每一个关键动作中介入操作。
我们继续。前面展示的这个案例,关键不仅仅在于如何创建工具,更重要的是如何教会 AI 使用它们。
(它需要理解)当我们在问这些相对复杂的问题时,我们究竟想让它做些什么?
为此,我们使用了一种古老的想法。
如果你回看阿兰·图灵 1950 年关于图灵测试的论文,他说,你永远不会为这个问题编写答案。,相反,你可以学习。你可以设计一个机器,就像一个人类孩子一样,然后通过反馈来教它。
让一个人类老师在它尝试和做出好或坏的事情时提供奖励和惩罚。这正是我们如何训练 ChatGPT 的方法。
这是一个两步流程。
第一步,我们通过无监督学习过程生成了图灵所谓的儿童机器。
我们只是向它展示整个世界、整个互联网,并说:「预测你从未见过的文本中的下一个内容。」
这个过程赋予了它各种厉害的技能。
比如这个数学问题,问它下一个词是什么?那个绿色的「9」,就是数学问题的答案。

但是我们还需要做第二步,也就是教 AI 如何使用这些技能。
为此,我们提供反馈。
我们让 AI 尝试多种方法,给我们多个建议,然后人类对它们进行评分,说「这个比那个好」。这不仅强化了 AI 所说的具体内容,而且非常重要的是,强化了 AI 用于产生答案的整个过程。这使它能够概括。它可以推断你的意图并将其应用于它以前没有看到过的情景,那些没有收到反馈的情况。
现在,有时我们需要教 AI 的东西并不是你所期望的。
例如,当我们首次向可汗学院展示 GPT-4 时,他们说:「哇,这太棒了,我们将能够教授学生很棒的东西。只有一个问题,它不会检查学生的数学。如果有错误的数学,它会快乐地假装 1+1 等于 3 并运行它。」

因此,我们需要收集一些反馈数据。
萨尔·汗本人非常友善,他自己花了 20 小时时间与我们的团队一起为机器提供反馈。
在几个月的时间里,我们能够教会 AI,「嘿,你真的应该在这种特定的情况下反击人类。」
通过这种方式,我们实际上对模型进行了很多改进。当你在 ChatGPT 中按下那个不喜欢的大拇指时,实际上就像发送了一个蝙蝠信号给我们的团队,说「这是一个需要收集反馈的薄弱环节」。
因此,当你这样做时,这是我们真正倾听用户,并确保我们正在构建对每个人都更有用的东西的一种方式。
02
事实核查和人类反馈
提供高质量的反馈是一件困难的事情。如果你让一个孩子打扫房间,如果你只检查地板,你不知道你是否只是教他们把所有的玩具都塞进衣柜里。
同样的推理也适用于人工智能。随着我们前往更困难的任务,我们必须扩大我们提供高质量反馈的能力。但为此,AI 本身乐意提供帮助。它很乐意帮助我们提供更好的反馈,并随着时间的推移扩大我们监督机器的能力。
让我给你展示一下我的意思。
例如,你可以向 GPT-4 提出这样的问题,即这两篇关于无监督学习和从人类反馈中学习的基础博客之间经过了多长时间?
模型说过去了两个月。但这是真的吗?就像这些模型并不是 100%可靠一样,尽管它们每次提供一些反馈就会变得更好。但我们实际上可以使用 AI 进行事实检查。它可以检查自己的工作。你可以说,为我核实这一点。
在这种情况下,我实际上给了 AI 一个新工具。这是一个浏览工具,模型可以发出搜索查询并点击网页。它实际上会在执行操作时写出整个思维链。它说,我要搜索这个,然后它会进行搜索。然后它找到了出版日期和搜索结果。然后它发出另一个搜索查询。它将单击博客文章。你可以做所有这些,但这是一项非常繁琐的任务。这不是人类真正想做的事情。坐在驾驶座上,处于这个管理者的位置,可以更有趣,如果你愿意,可以再次检查工作。
引文出现,因此你可以轻松验证整个推理链的任何部分。
结果实际上,两个月是错误的。
(ChatGPT 核查后的答案)两个月零一周,正确的。
03
重新思考人机交互
对我来说,整个过程最有趣的是它是人类和人工智能之间的多步协作。
因为人类使用这个事实检查工具是为了为另一个人工智能生产数据,使其对人类更加有用。
我认为这真正展示了一种我们期望在未来更为普遍的形式,即我们将人类和机器非常谨慎地设计成问题的一部分,以及我们希望解决该问题的方式。
我们确保人类提供管理、监督、反馈,机器以可检查和值得信赖的方式运行。而通过合作,我们能够创造出更值得信赖的机器。随着时间的推移,如果我们正确地进行这个过程,我们将能够解决不可能解决的问题。
多么不可能呢?
我们将重新思考我们与机器交互的几乎每一个方面。
例如,电子表格。
自 40 年前的 VisiCalc 以来,它们以某种形式存在。我认为它们在那个时候并没有发生太多变化。
Greg 在 ChatGPT 中上传了一个表格,记录了过去 30 年来 167000 篇 AI 领域论文的数据。ChatGPT 使用 Python/ target=_blank class=infotextkey>Python 自动分析数据,理解表格的每一纵列意味着什么,并在 Greg 的指令下绘出了多个可视化图表。Greg 用非常口语化的文字表达对产出效果的不满,ChatGPT 理解了他的意思,并自动修改了图表。
04
人与机器的共同协作
我们未来会怎样使用这项技术呢?
在这页 PPT 上,一个人带着他生病的狗去看兽医,兽医却作出了错误的判断:「我们等等再看看吧。」
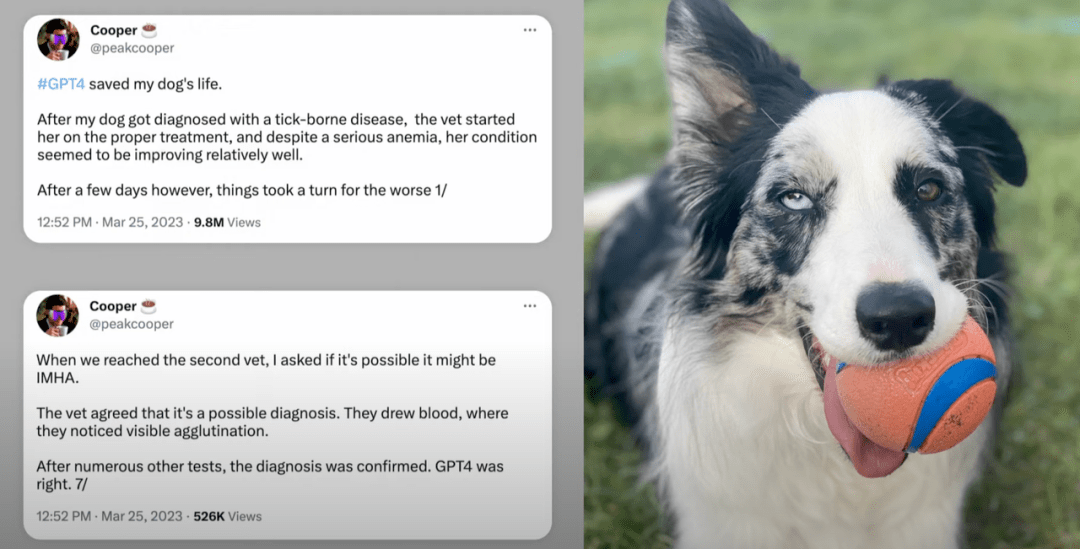
如果狗主人听了这句话,那只狗就不会活到今天。与此同时,他向 GPT-4 提供了血液检测和完整的病历记录,GPT-4 说:「我不是兽医,你需要找专业人士,这里有一些假设。」
他把这些信息带给了第二位兽医,后者利用这些信息挽救了狗的生命。
这些系统并不完美。你不能过分依赖它们。但这个故事显示出,一个与医疗专业人员和 ChatGPT 一起进行头脑风暴的人,能够取得一个否则不可能实现的结果。
我认为这是我们考虑如何将这些系统整合到我们的世界中时应该反思和思考的事情。
我深信,让人工智能发挥作用需要大家的参与。这是为了决定我们希望它如何融入,为了制定规则,决定什么是人工智能会做和不会做的事情。
如果听完演讲你只需要记住一句话,那就是:这项技术看起来与人们预期的完全不同。所以我们都必须变得精通。而这也是我们发布 ChatGPT 的原因之一。我相信,我们可以共同实现 OpenAI 的使命,确保人工智能的普及造福全人类。
05
问答环节
演讲结束后,TED 主席 Chris Anderson(简称 CA) 上台,与 Greg Brockman (简称 GB)做了一个简短的访谈,下面为访谈内容。
CA:OpenAI 只有小几百名员工。google 有数千名员工致力于人工智能。为什么是你们开发了这项震惊世界的技术?
GB:事实上,我们都在巨人的肩膀上。毫无疑问,如果你看看算力的进步、算法的进步、数据的进步,所有这些都是整个行业共同努力的结果。
但是在 OpenAI 内部,我们从早期开始就做出了许多非常明智的选择。
第一个选择是要直面现实。
我们认真思考了:要取得进展需要什么?我们尝试了许多行不通的方法,因此你只会看到那些有效的方法。我认为最重要的是让来自不同背景的人们和谐地协作。
CA:什么时候意识到智能开始出现了?
GB:深度学习,我们一直都觉得自己是一个深度学习实验室。
如何做到(智能)?我认为在早期,我们不知道。
我们尝试了很多事情,其中一个人正在训练一个模型来预测亚马逊评论中的下一个字符,他得到了一个结果——这是一个句法过程,你会期望模型会预测逗号放在哪里,名词和动词在哪里。
但他实际上做出了一个最先进的情感分析分类器。这个模型可以告诉你一个评论是积极的还是消极的。
今天我们听到这个,就觉得,得了吧,任何人都可以做到这一点。
但这是你第一次看到这种语义从潜在的句法过程中出现的情况。从那时起,我们知道,你必须扩大这个东西,看看它会走到哪里。
CA:我们很多人都有一个困扰。这东西(ChatGPT)被叫做预测(下一个词的)机器,但是从它展现的能力来看,它不可能只是一台预测机器。
涌现思想的关键在于,当数量达到一定程度时,会出现意外的情况。像蚂蚁,一支蚂蚁到处跑和一群蚂蚁的行动是完全不同的。城市也是,房屋数量增加,会出现郊区、文化中心、交通拥堵。
你能告诉我让你都大吃一惊的意外涌现是什么情况吗?
GB:在 ChatGPT 中,如果您尝试添加 40 位数字,该模型将能够执行它,表明它已经学习了一个「内部电路」(internal circuit)来进行加法。然而,如果您让它做 40 位数字和一个 35 位数字的加法,它经常会出错。
这表明虽然它正在学习这个过程,但它还没有完全泛化。
它不可能记住 40 位数字的加法表,这比宇宙中所有原子的数量还要多。所以它必须学会一些基本规律,(这个案例表明)它还没完全学会,不能理解任意数字是如何相加的。
CA:所以在这里发生的事情是,你让它扩大规模并分析了大量的文本。结果,它正在学习你没有预料到它能学到的东西。
GB:嗯,是的,这也更加微妙。我们开始擅长的一门科学是预测新兴能力。
要做到这一点,工程质量至关重要,而且这个领域经常被忽视。我们不得不重建整个堆栈,就像建造火箭一样,每个公差都必须非常小。
在机器学习中也是如此,在进行预测之前,必须正确地设计每个堆栈的每个组件。有许多平滑的扩展曲线告诉我们智能的一些基本特征。你们可以在我们的 GPT-4 博客文章中看到这些曲线。
现在,我们能够通过查看比例小 10000 或 1000 倍的模型来预测编码问题的性能。虽然现在还处于早期阶段,但这其中的一些特点是平稳的。
CA: 一个大的担忧是随着规模的扩大,可能会出现一些你能够预测但仍然有可能让你惊讶的事情。这是正在发生的事情的基础。但为什么没有出现真正可怕的巨大风险呢?
GB:我认为这些都是程度,规模和时间的问题。
人们似乎忽视了与世界的整合作为一个非常强大和新兴的因素。这就是我们认为逐步部署非常重要的原因之一。
目前,我的重点是提供高质量的反馈。对于我们今天所做的任务,检查它们很容易。例如,对于数学问题的答案为七,这很简单。然而,监督总结一本书等任务则很困难。你怎么知道书的总结是否好呢?你必须阅读整本书,但是没有人想这样做(笑)。
因此,逐步进行是很重要的。当我们转向书的概要时,我们需要适当监督这项任务,并与机器建立一个记录,以确保它们能够执行我们的意图。我们必须生产出更好、更有效、更可靠的扩展方法,使机器与我们相一致。
CA:在这个会话的后面,我们将听到批评者声称系统内部没有真正的理解。他们认为我们永远不会知道系统是否会产生错误或者缺乏常识。格雷格,你是否相信这是真的,但是随着规模的扩大,再加上人类的反馈,系统最终将以高度的自信实现真相和智慧?你能确定这一点吗?
GB:是的,我认为 OpenAI 正在朝着这个方向发展。OpenAI 的方法是让现实打在脸上,因为这个领域充满了空洞的承诺。专家们已经说了 70 年,神经网络不会起作用,但他们仍然没有被证明是正确的。也许还需要 70 年或更长时间才能证明他们是正确的。我们的方法始终是推动这项技术的极限,以看到它的实际效果,以便我们可以转向新的范式。我们尚未发掘出这项技术的全部潜力。
CA:我的意思是,你们所持的立场非常具有争议性。正确的做法是将其公之于众,然后利用所有这些反馈,而不仅仅是你的团队提供反馈。现在世界正在提供反馈。但是,如果坏事要出现,它们将会出现。
我最初听说的 OpenAI 的故事是,你们成立为非营利组织,成为对使用 AI 进行未知、可能是邪恶的事情的大公司的重要检查。如果有必要,你们将建立模型来追究他们的责任,并减缓该领域的发展速度。或者至少,那是我听到的。
然而,发生的事情恰恰相反。你们发布了 GPT,特别是 ChatGPT,震惊了科技界,现在谷歌、Meta 和其他公司正在赶紧跟进。他们的一些批评是,你们强迫他们在没有适当防护措施的情况下发布这个东西,否则他们就会死亡。
你如何辩称你们所做的是负责任而不是鲁莽的呢?
GB:是的,我们一直在思考这些问题——认真地思考。我不认为我们总能做到完美。但我相信,自从我们开始考虑如何构建造福全人类的人工智能时,有一件事情非常重要:我们应该如何做到这一点?在秘密建造、获取超强大工具、然后在启动前评估其安全性的默认计划似乎令人恐惧和错误。我不知道如何执行这个计划,也许有人知道,但对我来说,另一个方法是我看到的唯一的其他路径。这种方法是让现实打在你脸上,给人们时间提出意见,在机器变得完美和超强大之前允许观察机器的操作。我们已经看到了 GPT-3 的情况,对吧?我们担心人们会生成错误信息或试图干扰选举,但实际上,生成的第一件事情是「伟哥」垃圾邮件。(观众笑)
CA:伟哥的垃圾邮件却是很糟糕,但还有比它更糟糕的事情。这里有一个思想实验供你思考。假设你坐在一个房间里,桌子上有一个盒子。你相信盒子里有一些绝对美好的东西,可以给你的家人和其他人带来美好的礼物。然而,小字里也有一百分之一的可能性,盒子里装的是「潘多拉」,它可能会释放出难以想象的恶魔。你会打开这个盒子吗?
GB:绝对不。我认为你不应该那样做。
让我告诉你一个我之前没有分享过的故事。我们刚开始开放人工智能时,我在波多黎各参加了一个人工智能会议。我坐在酒店房间里,看着美丽的海水和人们玩乐。有一瞬间,我想知道我更喜欢哪个:五年内或五百年内打开人工智能的潘多拉之盒。一方面,有些人可能更喜欢它五年后开启。但是如果它在五百年后,人们会有更多时间来做正确的事情。你会选择哪一个?在那一刻,我意识到我会选择五百年。
当时,我哥哥在军队中,比我们任何一位技术开发者更真实地冒着生命危险。因此,我非常相信谨慎地开发人工智能。但是,我认为我们没有准确评估情况。在计算机历史上,这种转变是整个行业,甚至是技术发展的人类范畴。如果我们不能把已有的技术整合起来,我们就会面临一个过剩的局面。我们仍在制造更快的计算机和改进算法,如果我们不整合它们,其他人就会。当他们这样做时,我们将拥有一种非常强大的技术,没有任何安全措施。
当你考虑其他技术的发展,例如核武器,人们谈论它是人类能做的从零到一的变化。但我认为能力一直在平稳地增长。我们开发的每一项技术的历史都是渐进的,我们不得不在每个发展阶段进行管理。
CA:所以,如果我理解正确,你想让我们遵循的模型是,我们生下了一个非凡的孩子,可能具有能够将人类带到一个全新层次的超能力。我们有集体责任为这个孩子提供指导,并教导它做出明智的决定,以免它毁灭我们所有人。这是基本的想法吗?
GB:我相信这是真的。同时也要认识到这可能会改变。我们需要针对每一个步骤来处理。今天,至关重要的是我们变得熟悉这项技术,确定如何提供反馈,并决定我们想从中得到什么。我希望这仍然是最佳的行动方案,但很积极我们正在进行这个讨论,否则这个讨论就不会发生。