数组内存模型
一维数组
当定义一个数组后
int[] data = new int[5];
1
内存模型如图所示
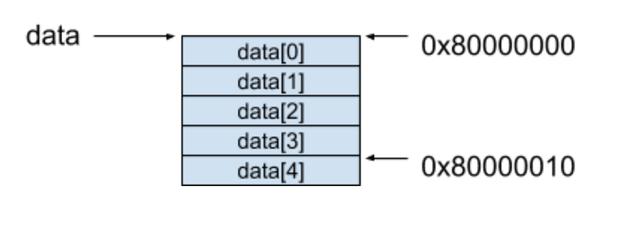
这种连续空间的内存模型揭示了一个重要特性:随机访问(random access)random access:可以用同等的时间访问到一组数据中的任意一个元素。
我们可以用如下代码获取数组中的值:
data[0]
1
这种从 0 开始进行索引的编码方式被称为是“Zero-based Indexing”我们可以通过以下公式获取数组特定元素:
base_address + index * date_size = target_address
1
此公式保证了,不同的数组元素达到的时间是相同的。
二维数组
一般称为一维数组为 向量(Vector) 或 表(Table),数学上称二维数组为 矩阵(Matrix)
按照以下代码声明一个矩阵:
int[][] data = new int[2][3]
1
基于这个二维数组,我们是无法确定 data[0][1]的内存地址,因为这个问题涉及到二维数组在内存中的寻址方式。其本质是 行优先(Row-Major Order) 还是 列优先(Column-Major Order)
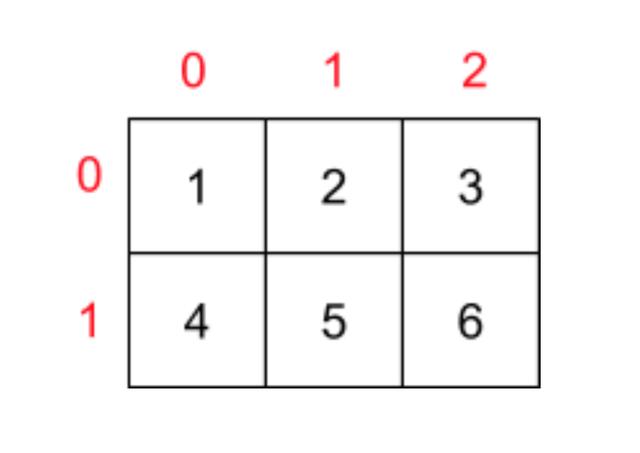
在行优先内存模型中,每一行的相邻元素保存在相邻的连续内存空间中,这个二维数组内存模型如下所示:
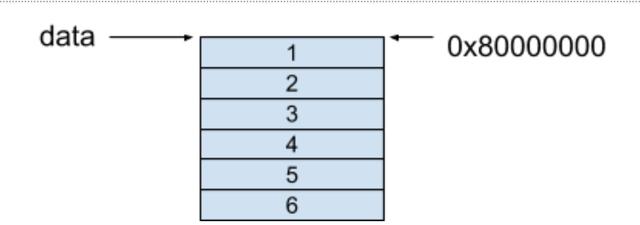
我们可以按照以下公式获取data[i][j]里的元素:
base_address + data_size * (i * number_of_column + j)
1
在列优先内存模型中,每一列的相邻元素保存在相邻的连续内存空间中,这个二维数组内存模型如下所示:
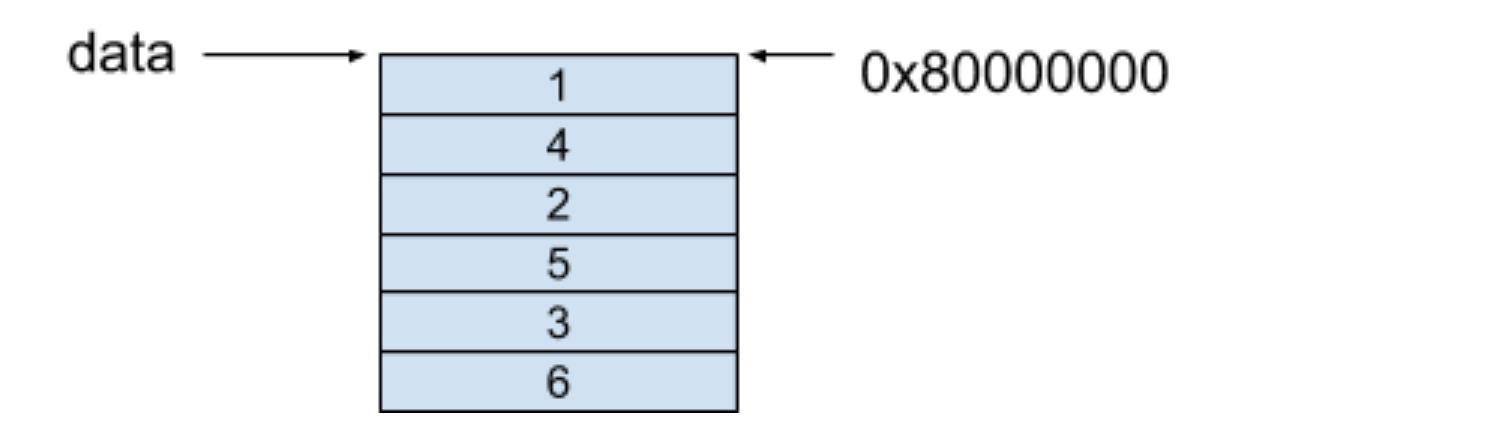
我们可以按照以下公式获取data[i][j]里的元素:
base_address + data_size * (i * number_of_row + j)
1
CPU 在读取内存数据的时候,通常会有一个 CPU 缓存策略。也就是说,在 CPU 读取程序指定地址的数值时,CPU 会把和它地址相邻的一些数据也一并读取并放到更高一级的缓存中,比如 L1 或者 L2 缓存。当数据存放在这种缓存上的时候,读取的速度有可能会比直接从内存上读取的速度快 10 倍以上。
数组特点
高效的访问和低效的插入删除
数组的访问时间复杂度是 O(1)
对于保存基本类型(Primitive Type)的数组来说,它们的内存大小在一开始就已经确定好了,我们称它为静态数组(Static Array)。静态数组的大小是无法改变的,所以我们无法对这种数组进行插入或者删除操作。但是在使用高级语言的时候,比如 JAVA,我们知道 Java 中的 ArrayList 这种 Collection 是提供了像 add 和 remove 这样的 API 来进行插入和删除操作,这样的数组可以称之为动态数组(Dynamic Array)。
为了维持数组内存中的连续性,当插入一个数据时,需要把待插入节点及之后所有的数据都拷贝,然后给数组扩容,把拷贝的数据放入待插入节点之后,最后再在待插入节点插入目标值。删除元素同理,所以插入删除时间复杂度是 O(n)















