AI爬虫在破坏流量主的收益

大多数人可能并不知道,我们浏览和创建的网站上充斥着各种数字蜘蛛。其中最活跃的蜘蛛可能就是谷歌爬虫,它自动收集网页信息,以便谷歌可以在搜索结果中对其进行排名和展示。
就在此刻,这些蜘蛛正在爬行并收集我所写的每一个字,这种想法确实有些令人毛骨悚然。
然而,这些数字蜘蛛也是非常有用的。举个例子,假设我在2003年写了一本旅行书。当谷歌的爬虫爬过我的书籍网页时,我会感到非常高兴,因为这意味着当人们搜索旅行书籍时,他们可能会被引导到我的书籍页面。这样,他们就有可能购买并阅读我的书籍。
这是互联网经济蓬勃发展的伟大交易:谷歌爬取您的内容并为您带来流量,从而激励您继续在网络上发布信息。
然而,如今,新兴的生成式人工智能(AI)和大型语言模型正在破坏这种交易。最近,OpenAI承认他们有一只名为GPTbot的这种爬虫在网上活动,用于收集在线内容以进行AI模型训练。未来的大型模型GPT-5很可能会基于这个机器人收集的数据进行训练。
GPT-4、ChatGPT和其他强大的模型可以即时智能地回答问题,这降低了用户查看原始信息来源的需求。这对用户体验来说可能是非常好的,但同时也削弱了共享高质量免费在线内容的激励。
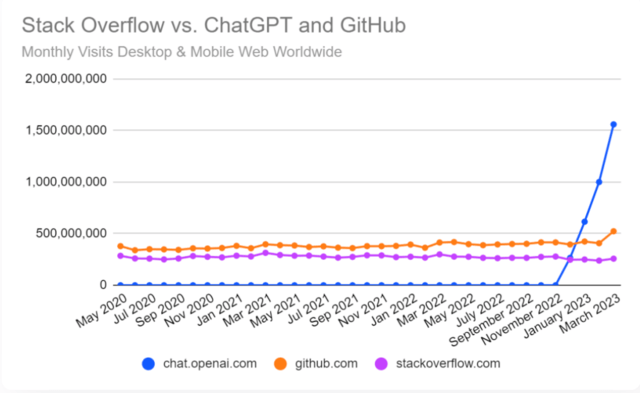
那么,作为免费在线内容的生产者,为什么要允许OpenAI爬取我们的材料,并将这些数据用于训练未来的语言模型呢?您可能已经注意到这种行为,因为越来越少的人访问Stack Overflow来获取软件编码的帮助。
OpenAI的爬虫程序潜伏在网络上已经有一段时间了,我们还不清楚具体有多久。该公司最近宣布了使用常见协议robots.txt来阻止GPTbot的方法。一些创作者已经采取了这个方法,尽管有些人怀疑OpenAI是否已经在秘密地搜集了所有人几个月甚至几年的在线数据。
对于那些依赖广告和流量的网站来说,OpenAI的行为可能会对他们的收入产生负面影响。如果人们通过OpenAI的模型获得他们网站的回答,那么这些网站的广告收入可能会减少。
总的来说,OpenAI的爬虫行为引发了对数字蜘蛛的讨论。一方面,这些爬虫为用户提供了更好的体验,使他们能够快速获得所需的信息。但另一方面,它们可能削弱了创作者的激励,使他们难以获得流量和收入。
如今,创作者们面临着一个重要的决策:是否允许OpenAI爬取他们的内容,并为他们的语言模型提供数据。这是一个复杂的问题,需要综合考虑创作者自身的利益以及整个互联网生态系统的健康。
无论您对数字蜘蛛持何种态度,它们已经成为互联网世界中不可或缺的一部分。我们需要找到一种平衡,既能够满足用户的需求,又能够保护创作者的权益。这是一个需要全球社区共同努力的挑战。