一文带您了解向量数据库
向量数据库在构建基于大语言模型的行业智能应用中扮演着重要角色。大模型虽然能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。为了解决这一问题,企业可以利用向量数据库结合大模型和自有知识资产,构建垂直领域的智能服务。向量数据库存储和处理向量数据,提供高效的相似度搜索和检索功能。通过向量嵌入,将企业知识库文档和数据转化为向量表示,并与大模型进行交互,实现专有、私域的垂直的行业智能化应用。
基于大语言模型构建行业智能应用为什么需要向量数据库?
在2023年这个春天,最受瞩目的科技产品无疑是ChatGPT。ChatGPT的问世重新点燃了曾经静寂已久的人工智能领域,为AI注入了新的活力。大语言模型(LLM)展示了生成式AI能够达到与人类语言高度相似的表达能力,使得AI不再遥不可及,而是已经进入了人们的工作和生活中。众多从业者都急切地投身于这个改变时代的机遇,生成式AI已经成为资本和企业不可忽视的下一代技术关键,同时也对底层基础设施的提出了更高的要求。
大模型能够回答较为普世的问题,但是若要服务于垂直专业领域,会存在知识深度、知识准确度和时效性不足的问题,比如:医疗或法律行业智能服务要求知识深度和准确度比较高,那么企业构建垂直领域智能服务?目前有两种模式:
- 基于大模型的Fine Tune方式构建垂直领域的智能服务,需要较大的综合投入成本和较低的更新频率,适用性不是很高,并适用于所有行业或企业。
- 通过构建企业自有的知识资产,结合大模型和向量数据库来搭建垂直领域的深度服务,本质是使用知识库进行提示工程(Prompt Engineering)。以法律行业为例,基于垂直类目的法律条文和判例,企业可以构建垂直领域的法律科技服务。如法律科技公司https://www.harvey.ai/,正在构建“律师的副驾驶”(Copilot for lawyers)以提高法律文件的起草、修改和研究服务。
将企业知识库文档和数据通过向量特征提取(embedding)然后存储到向量数据库(vector database),应用LLM大语言模型与向量化的知识库检索和比对知识,构建智能服务。比如:应用大语言模型和向量数据库(知识库)可以让企业应用级Chatbot(聊天机器人)的回答更具专业性和时效性,构建企业专属Chatbot。
为啥是向量(vector)?
向量(vector)是在大语言模型、知识库交互、计算过程中的重要指标。它可以将文本和知识表示为数学向量,实现文本相似度计算、知识库检索和推理等功能。向量(vector)为语义理解和应用提供了一种方便有效的表示方法。
“ vector 是模型之根,是大模型与知识库交互之桥。 向量嵌入(vector embeddings)是一种AI原生的数据表示方式,适用于各种基于AI的工具和算法。它可以表示非结构化的数据或知识,如文本、图像、音频和视频等。
”
图:LLM进化之树
什么是vector embeddings
罗伊·凯恩斯(Roy Keynes)的定义是:“嵌入(vector embeddings)是学习的转换,使数据更有用”。神经网络深度学习将文本转化为一个包含其实际含义的向量空间。这更有用,因为它可以找到同义词,以及单词之间的句法和语义关系。最为经典的例子:Queen=King-Man+Woman
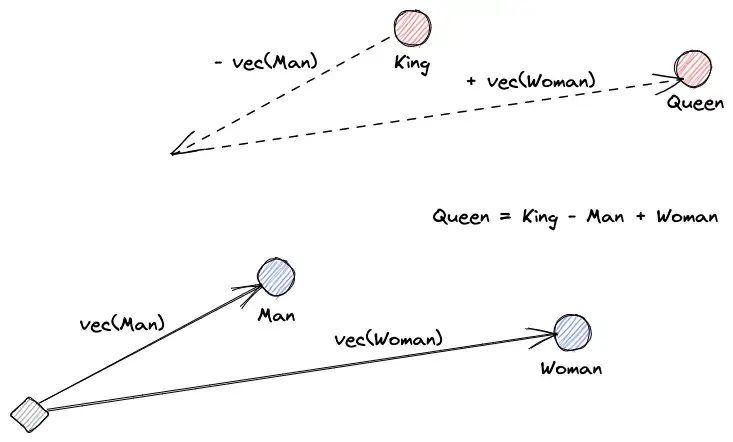
图:词向量示意图
向量数据库作用是什么
向量数据库的主要作用是存储和处理向量数据,并提供高效的向量检索功能。最核心是相似度搜索,通过计算一个向量与其他所有向量之间的距离来找到最相似的向量(最相似的知识或内容)。这是基本索引(flat indexes)的朴素原理,在大型向量数据库中,这可能需要很长时间。
为了提高搜索性能,可以尝试仅计算一部分向量的距离。这种方法称为近似最近邻(Approximate nearest neighbors:ANN),它提高了速度,但牺牲了结果的质量。一些常用的ANN索引包括局部敏感哈希(Locally Sensitive Hashing:LSH)、分层可导航小世界(Hierarchical Navigable Small Worlds:HNSW)或倒排文件索引(Inverted File Index:IVF)等。
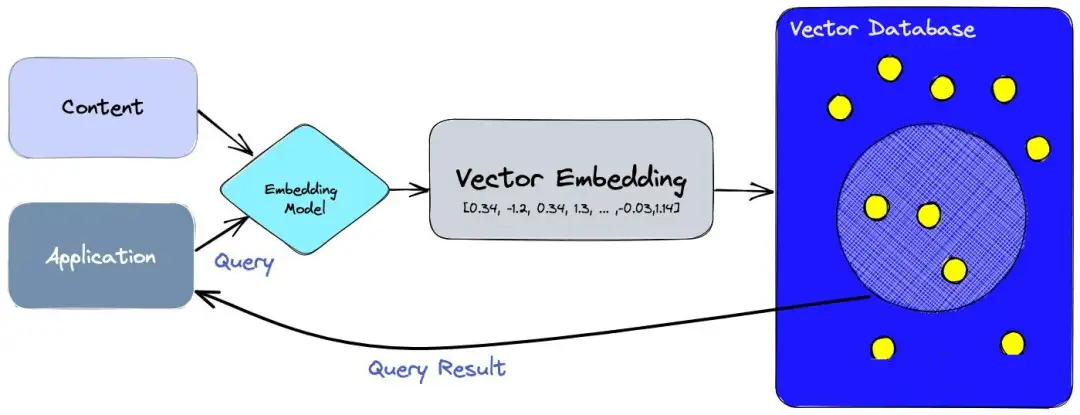
图:向量数据库结构
以上结构图,核心包括两个关键部分:Embedding 和 vector database ,Embedding过程是将非结构化的数据编码为向量,这些非结构化的数据包括:文本、图片等等,Embedding 的核心Embedding Model。过程包括:
- 使用嵌入模型(Embedding Model)来为想要索引的内容创建向量。这些内容包括文本、图片、视频等等。
- 向量被插入到向量数据库中,包括原始内容。
- 当应用程序发出查询时,使用相同的嵌入模型为查询创建向量,并使用这些向量在数据库中查询相似的向量。如前所述,这些相似的向量与用来创建它们的原始内容相关联。
在chatGPT火爆的春天里,各种向量数据库如雨后春笋般冒出来,参见:https://github.com/topics/vector-database ;为更好理解向量数据库,笔者试用了两个开源的向量数据库:Chroma 和 milvus。
Chroma :the open-source embedding database.
Github:https://github.com/chroma-core/chroma
Chroma是一个开源的嵌入向量数据库,专门用于存储和检索向量嵌入。它提供高效的存储和检索功能,支持相似度搜索和大规模向量数据处理。Chroma的架构设计灵活,具备可扩展性和高性能,能够处理不断增长的数据量和查询负载。开发人员可以根据自己的需求自定义和扩展Chroma的功能,利用向量嵌入实现先进的语义搜索和分析能力。
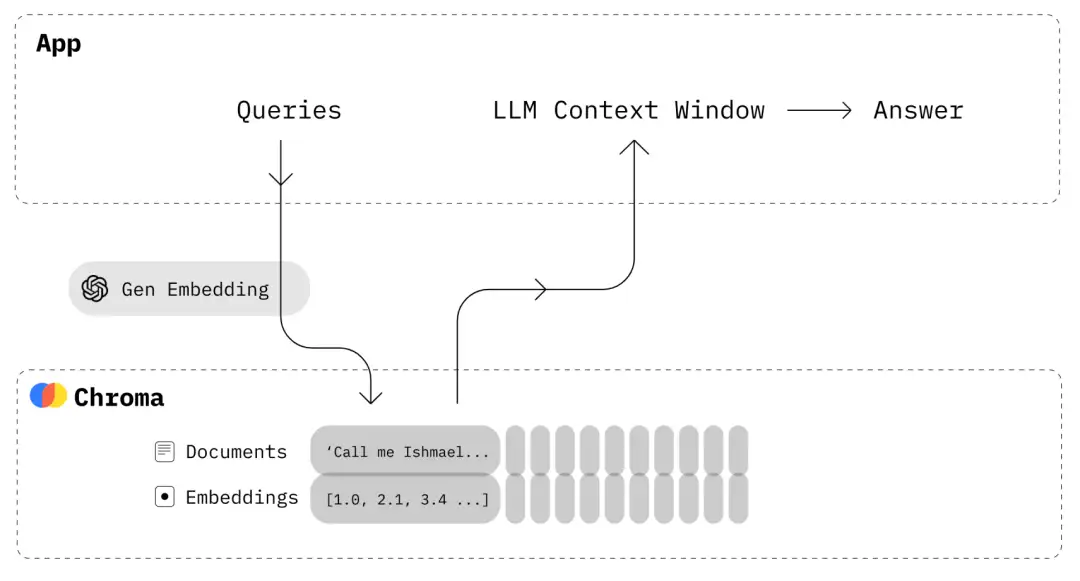
图:Chroma应用交互流程
import chromadb
# setup Chroma in-memory, for easy prototyping. Can add persistence easily!
client = chromadb.Client()
# Create collection. get_collection, get_or_create_collection, delete_collection also available!
collection = client.create_collection("all-my-documents")
# Add docs to the collection. Can also update and delete. Row-based API coming soon!
collection.add(
documents=["This is document1", "This is document2"], # we handle tokenization, embedding, and indexing automatically. You can skip that and add your own embeddings as well
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # filter on these!
ids=["doc1", "doc2"], # unique for each doc
)
# Query/search 2 most similar results. You can also .get by id
results = collection.query(
query_texts=["This is a query document"],
n_results=2,
# where={"metadata_field": "is_equal_to_this"}, # optional filter
# where_document={"$contains":"search_string"} # optional filter
)
Chroma支持的嵌入模型:
- all-MiniLM-L6-v2
from chromadb.utils import embedding_functions
default_ef = embedding_functions.DefaultEmbeddingFunction()
- Sentence Transformers
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="text-embedding-ada-002"
)
- Instructor models
cohere_ef = embedding_functions.CohereEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="multilingual-22-12")
multilingual_texts = [ 'Hello from Cohere!','您好,来自 Cohere!',]
cohere_ef(texts=multilingual_texts)
ef = embedding_functions.InstructorEmbeddingFunction(
model_name="hkunlp/instructor-xl", device="cuda")
- Google PaLM API models
palm_embedding = embedding_functions.GooglePalmEmbeddingFunction(
api_key=api_key, model=model_name)
milvus:github 星星最多的开源向量数据库
Milvus是github 星星最多的开源向量数据库,专门用于快速存储、检索和分析大规模向量数据。它提供高性能和可扩展的架构,支持多种向量索引算法和查询模式。Milvus可广泛应用于推荐系统、图像搜索、自然语言处理和机器学习等领域,帮助用户快速发现和分析相似的向量数据。
github:https://github.com/milvus-io/milvus
同时提供一个云化的服务(Zilliz CLoud),为了更简洁说明和体验向量数据,笔者直接开通的服务尝试向量数据库,免费100刀的试用额度,https://cloud.zilliz.com/ 。
milvus(Zilliz CLoud)
注册忽略,直接创建数据库和collection,可以自己上传数据(需要自己Embedding 向量 )也可以使用它样例数据创建collection,然后data preview 和搜索查询;后面部分Python/ target=_blank class=infotextkey>Python API 调用服务执行搜索等任务示例。
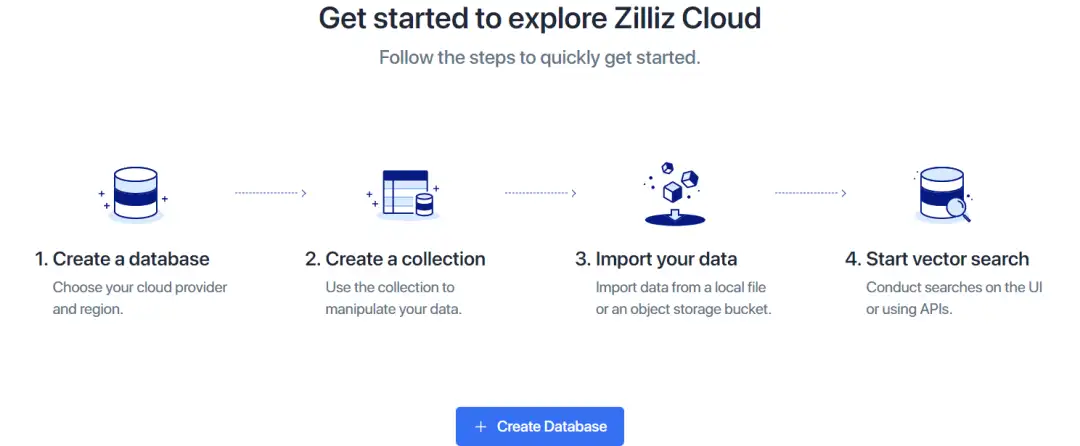
图:开始探索Zilliz CLoud
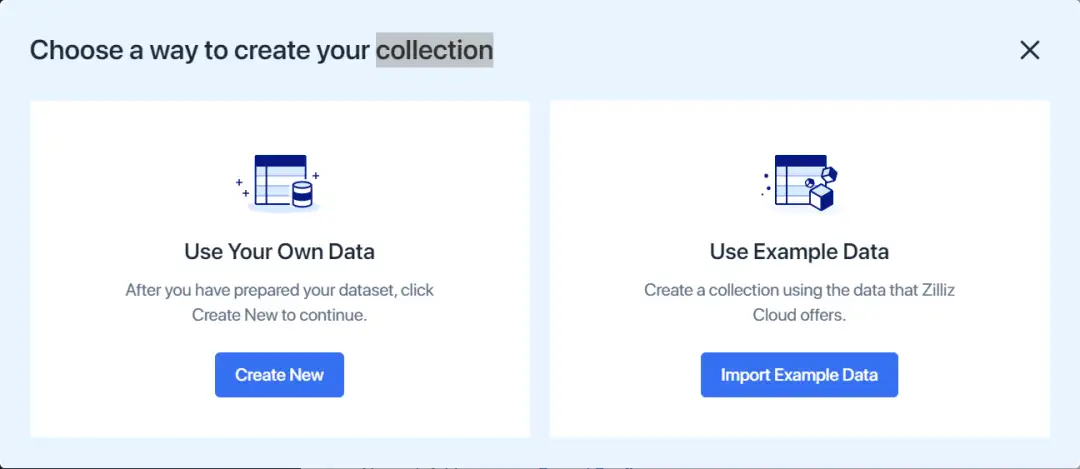
图:选择创建collection的方式
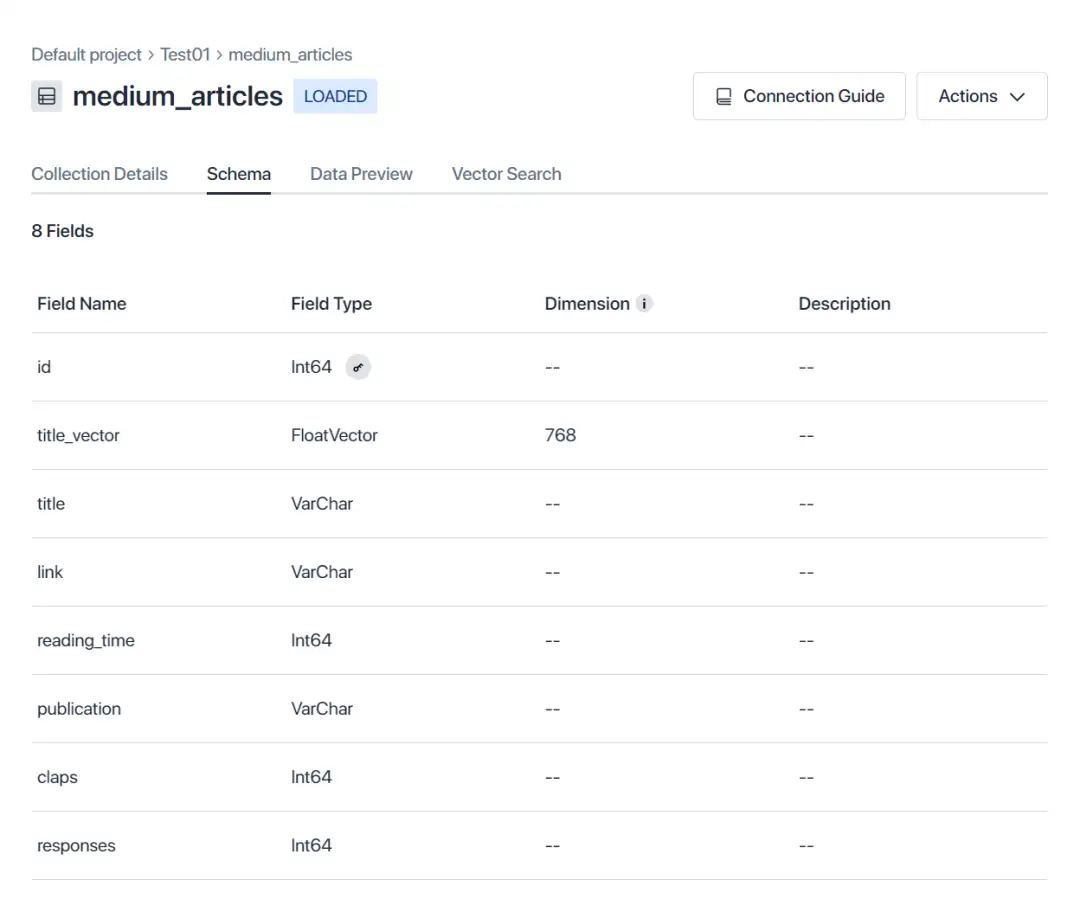
图:查看Schema
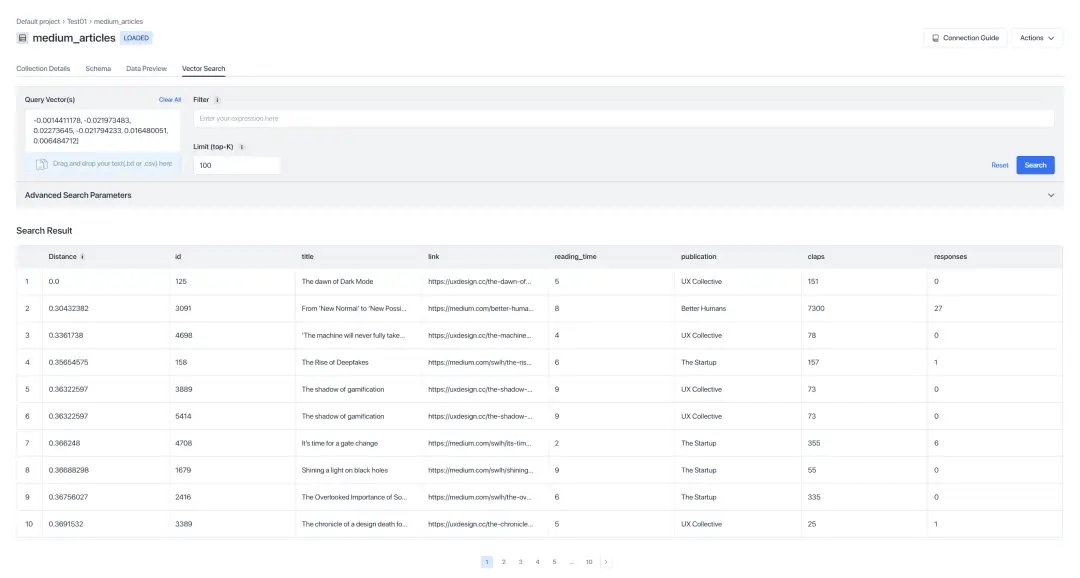
图:向量搜索
Python pymilvus
- 连接远程的Milvus向量数据
import pandas as pd
from pymilvus import connections,utility,FieldSchema,CollectionSchema,DataType,Collection
conn=connections.connect("default", host="in01-70ff1fe5d9bc5a0.aws-us-west-2.vectordb.zillizcloud.com", port="19537",secure = True,
user='db_admin', password=snbGetValue("milvus_pw"))
has = utility.has_collection("medium_articles")
print(f"Does collection medium_articles exist in Milvus: {has}")
- 获得collection
collection = Collection("medium_articles") # Get an existing collection.
collection.load()
- collection 的元数据
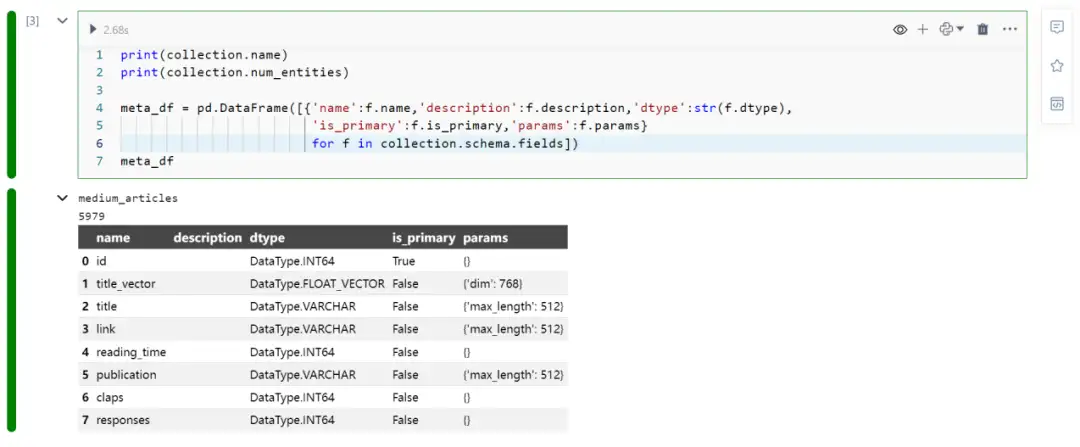
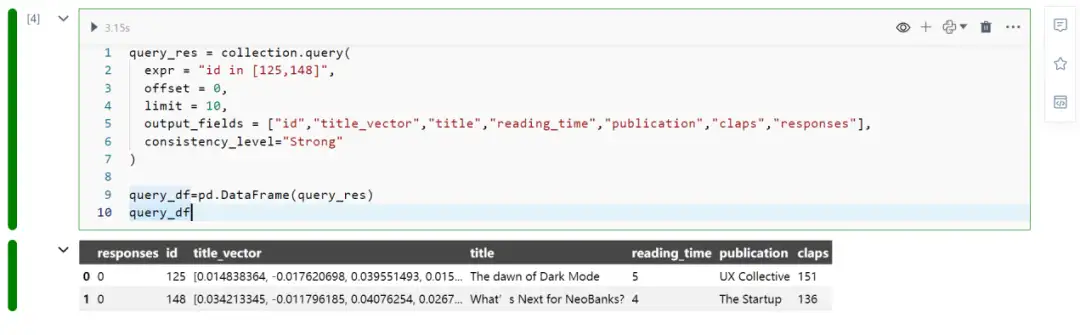
- Milvus查询query
- Milvus 向量(vector)搜索
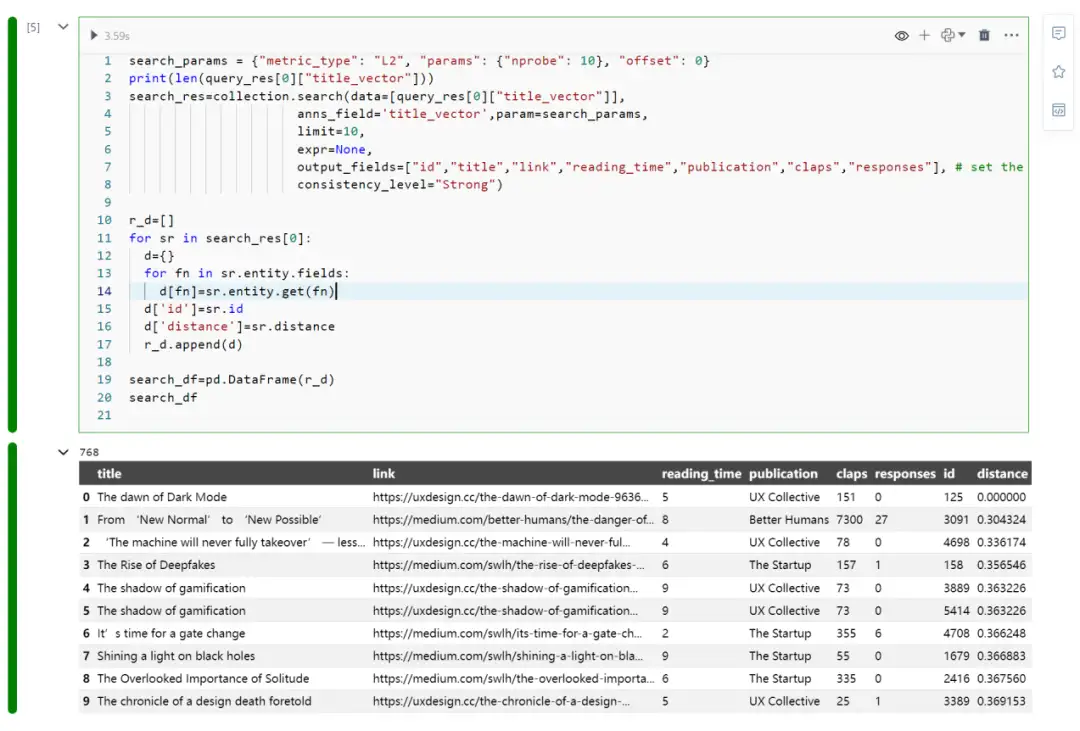
图:以上代码的Graph视图