如何优化 SQL 数据库以处理数百万条记录?

SQL 数据库是许多需要存储和检索大量数据的应用程序的骨干。但是,随着数据大小的增长,数据库可能会变得缓慢且无响应。这可能会对应用程序的整体性能产生重大影响,并可能导致负面的用户体验。在本文中,我们将介绍优化 SQL 数据库以处理数百万条记录的一些最佳实践。
正常化
规范化是在数据库中组织数据以减少冗余并提高数据完整性的过程。规范化的主要目标是将数据拆分为更小、更易于管理的表。这样可以更轻松地更新和维护数据,还可以减少可能导致不一致的重复数据量。
例如,让我们考虑一个存储有关客户和订单信息的数据库。在非规范化数据库中,有关客户及其订单的信息将存储在单个表中。但是,这将导致大量冗余数据,并使更新客户信息变得困难。相反,数据可以拆分为两个表:一个用于客户,一个用于订单。客户表将存储客户姓名、地址和电子邮件等信息,而订单表将存储有关每个单独订单的信息,例如订单日期和购买的产品。
索引
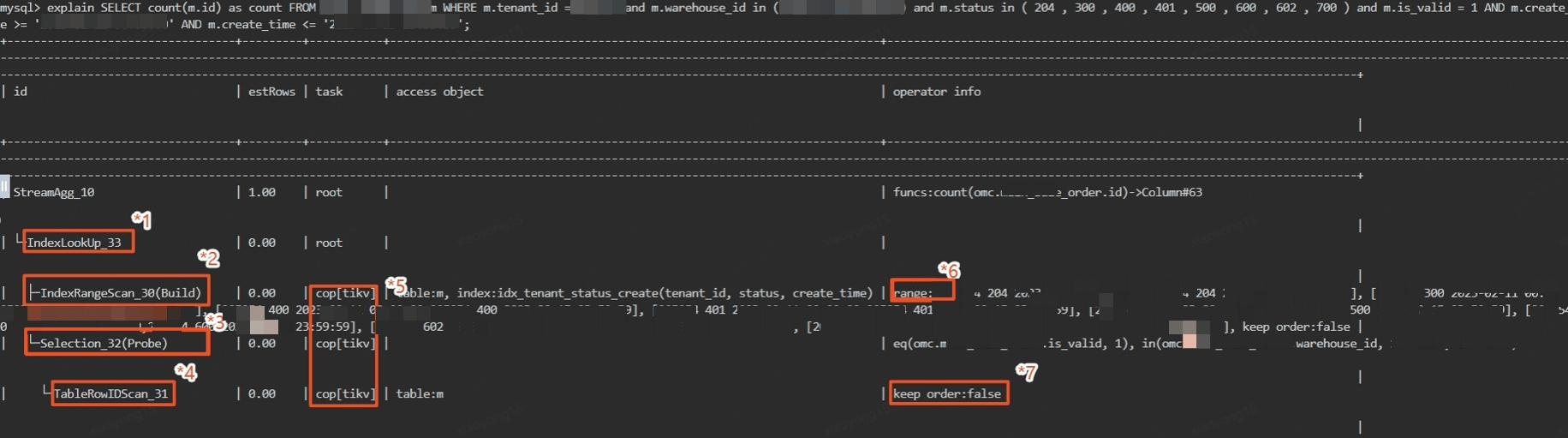
索引是优化 SQL 数据库的最重要技术之一。索引是一种数据结构,它根据一列或多列中的值提供对表中行的快速访问。如果没有索引,数据库将不得不扫描整个表才能找到您要查找的数据,这在处理数百万条记录时可能会非常慢。
例如,让我们考虑一个存储客户订单信息的数据库。如果您经常需要检索有关特定客户所下订单的信息,则可以在客户 ID 列上创建索引。这将允许数据库快速查找具有特定客户 ID 的所有行,而无需扫描整个表。
分区
分区是一种将大表分解为更小、更易于管理的部分的技术。这可以通过减少需要扫描和处理的数据量来帮助提高性能。
例如,让我们考虑一个存储客户订单信息的数据库。如果您经常需要检索有关特定月份所下订单的信息,则可以根据订单日期对表进行分区。这将允许数据库快速检索有关特定月份下达的订单的信息,而无需扫描整个表。
缓存
缓存是一种将频繁访问的数据存储在内存中的技术,以便无需查询数据库即可快速检索数据。这可以显著提高性能,尤其是在处理数百万条记录时。
例如,让我们考虑一个存储客户订单信息的数据库。如果您经常需要检索有关最新订单的信息,则可以将此信息缓存在内存中。这将允许您检索信息而无需查询数据库,这将更快。
使用适当的数据类型
使用适当的数据类型对于优化 SQL 数据库非常重要。例如,对仅存储小正数的列使用整数数据类型比使用浮点数据类型更有效。同样,使用固定长度字符串数据类型比使用可变长度字符串数据类型更有效。
例如,让我们考虑一个存储客户订单信息的数据库。如果有一个存储订购物料数量的列,则应使用整数数据类型,因为它比浮点数据类型更有效。同样,如果您有一个存储客户名称的列,则应使用固定长度的字符串数据类型,因为它比可变长度的字符串数据类型更有效。
存储过程的使用
存储过程是可以重复执行的预编译的 SQL 语句集。它们可以通过减少需要通过网络发送并由数据库服务器解析的 SQL 代码量来帮助优化 SQL 数据库。
例如,让我们考虑一个存储客户订单信息的数据库。如果经常需要检索有关特定客户所下订单的信息,则可以创建一个存储过程,该过程将客户 ID 作为参数并返回相关信息。此存储过程将存储在数据库服务器上,并在您需要检索信息时执行。这将减少需要通过网络发送并由数据库服务器解析的 SQL 代码量,这将有助于提高性能。
视图的使用
视图是从一个或多个表中的数据派生的虚拟表。它们可以帮助简化访问数据所需的 SQL 代码,并提供基础数据的抽象级别。
例如,让我们考虑一个存储客户订单信息的数据库。如果您经常需要检索有关特定客户所下订单的信息,则可以创建一个视图,该视图提供简化的数据视图,仅包含相关列和仅包含相关行。然后可以使用此视图代替原始表,这将简化访问数据所需的 SQL 代码,并提供基础数据的抽象级别。
实例化视图的使用
实例化视图是预先计算的视图,用于将查询结果存储在物理表中。它们可以通过减少数据库服务器需要处理的数据量来帮助提高性能。
例如,让我们考虑一个存储客户订单信息的数据库。如果您经常需要检索有关最新订单的信息,则可以创建一个实例化视图,该视图提供最新订单的预先计算视图。此实例化视图将存储在数据库服务器上的物理表中,并在下新订单时进行更新。这将减少数据库服务器需要处理的数据量,这将有助于提高性能。
总之,优化 SQL 数据库以处理数百万条记录需要将良好的数据库设计、索引、缓存以及使用适当的数据类型、存储过程、视图和实例化视图结合起来。通过遵循这些最佳实践,您可以帮助确保数据库快速、响应迅速且能够处理高流量应用程序的需求。