聊聊HBase分布式数据库设计那些事
数据模型
传统的关系型数据库,一张表(table)由行(row)和列(column)组成。相对Hbase分布式数据库却有所差别,可以把Hbase中的表理解成不同维度Map的集合。包含以下主要概念。
- table
hbase数据库中的表。 - row
hbase数据库表中的行。一张表包含多行。每一行由row key和一个或多个column的值组成。row key按字母表顺序排序存储。在设计表的row key时,推荐按业务含义把相近的内容放到一起,这样可以有效地提高查询效率。比如:一张表的row key为domain(域名)时,对应row key值最好设计成域名的倒叙值(如:org.Apache.www, org.apache.mail, org.apache.jira),hbase存储时就可以把相同根域名的值放到同一块存储区域中,查询起来更快。row key不宜设计过大,hbase中每个值都会保存相关keys (row key, family qualifier, and timestamp)。
- column
hbase数据库表中的列。列由列族(column family)和列修饰符(column qualifier)构成。两者通过':'符号分隔。
- column family
框架性能方面的考虑,列族在物理上是多个列以及列中的相应值的集合。列族中还会存储一些基础的元数据,比如当前列族内容是否需要缓存在内存中,row key编码规则,数据压缩方式等。一张hbase表中的列族不宜过多,一般建议不超过3个,过多时在数据块压缩调整时会导致相互影响,从而影响性能。
- column qualifier
列修饰符被加入到某个列族中,并在列族中提供索引关联列修饰符中的值。如:列族content中的html修饰符,表示content:html;另一个修饰符pdf,则表示content:pdf。
- cell
一个单元对应表中一行(row)中列族(column family)下某个列修饰符(column qualifier)的值,包含具体值和时间戳(timestamp),其中时间戳用来标识当前值所属的版本(version)。
- timestamp
cell值被写入时,附带会写入相应的timestamp时间,作为该值的一个版本信息。timestamp默认取当前RegionServer服务机器上的时间,当然你也可以自行指定时间值。
概念视图
上面数据模型介绍的概念通过以下表格可以帮助理解。

将以上表格转换成json格式

通过以上图示,可以了解:
一个row key具有多个版本的数据,不同版本通过不同的timestamp定义。
一个column family可以有多个column qualifier。
row key下的column family可以为空。
一个row key多版本数据按版本号时间倒序排列。当查询条件不带版本号时,以倒叙顺序依次从上往下查找。如:rowkey="com.cnn.www",列族=contents:html,返回值t6版本的值。
NOSQL特性
hbase是一个nosql数据库,相较于RDBMS,它不支持传统关系型数据库的typed columns(列类型), secondary indexes(二级索引), triggers(触发器), and advanced query languages(高级查询语言)等特性。它的长处在数据存储,是真正意义上的分布式数据库。通过添加RegionServer机器,即可实现hbase的线性和模块化扩展。
Hbase具有以下特性:
- Strongly consistent reads/writes: HBase is not an "eventually consistent" DataStore. This makes it very suitable for tasks such as high-speed counter aggregation.(强一致读写,非最终一致性数据存储,这使得特别适合高速的count聚合运算场景)。
- Automatic sharding: HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows.(自动分片:HBase表通过regions分布到集群的不同机器上,随着数据增长,regions会自动分裂和重新分配集群机器资源)
- Automatic RegionServer failover(自动RegionServer故障切换)
- Hadoop/HDFS Integration: HBase supports HDFS out of the box as its distributed file system.(支持Hadoop和HDFS集成)
- MapReduce: HBase supports massively parallelized processing via MapReduce for using HBase as both source and sink.(支持MapReduce计算框架)
- JAVA Client API: HBase supports an easy to use Java API for programmatic access.(友好的java API集成)
- Thrift/REST API: HBase also supports Thrift and REST for non-Java front-ends.(友好的Thrift/REST API集成)
- Block Cache and Bloom Filters: HBase supports a Block Cache and Bloom Filters for high volume query optimization.(大容量查询优化,设计了块缓存和布隆过滤)
- Operational Management: HBase provides build-in web-pages for operational insight as well as JMX metrics.(内置可视化界面操作工具)
表物理存储模型

HBase表中的数据被拆分成不同的区域块(Region),每个区域块按一定规则分发到集群中不同的RegionServer上。通过这种把大表中数据打散到集群节点存储的方式来实现大数据宽表的线性扩展能力。
架构
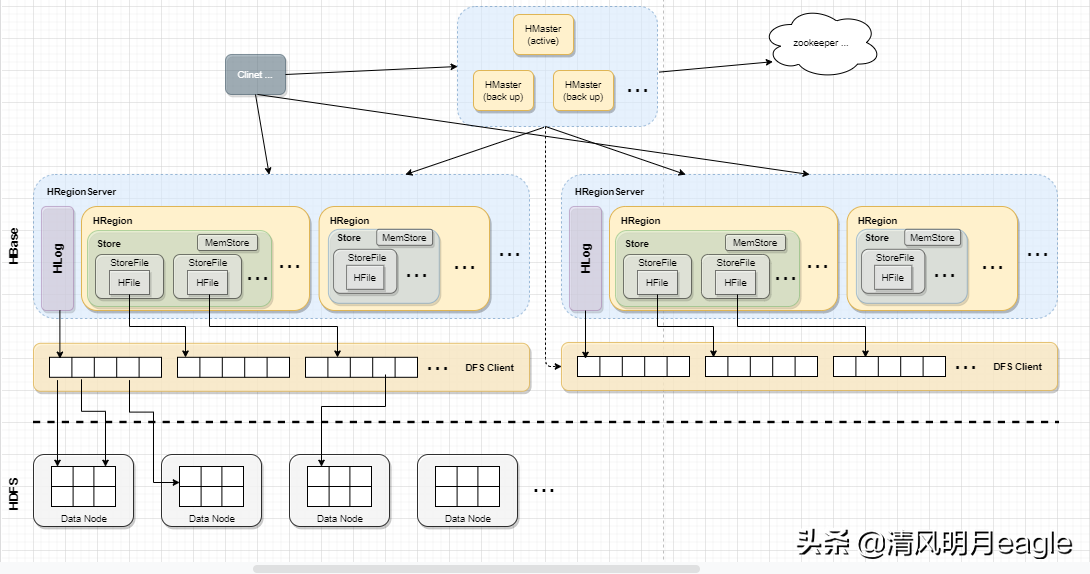
上图Hbase总体架构图,包含了HMaster、HRegionServer、HRegion、Hlog、Store、MEMStore等逻辑结构划分。HBase以HDFS作为底层存储框架,通过DFS Client进行文件操作。HMaster负责把HRegion分配给HRegionServer。一个HRegionServer包含多个HRegion。HRegionServer中的多个Region共享一个HLog,HLog用来做灾备恢复。一个Region由一个或多个store组成,一个store对应表中的一个列族,每个store包含memStore和其对应的一个或多个StoreFile。StoreFile是HFile的轻量封装,HFile是HDFS中的文件存储格式,MemStore放在内存中。
- Client
Client访问在新版本中将不直接操作zookeeper,通过HMaster的RPC远程端口间接获取meta数据。Client获得RegionServer Location后将直接对接RegionServer服务,无需经过HMaster转接。
- HMaster
HMaster主要功能:把HRegion分配到某一个RegionServer;有RegionServer宕机了,HMaster可以把这台机器上的Region迁移到active的RegionServer上;对HRegionServer进行负载均衡;通过HDFS的dfs client接口回收垃圾文件(无效日志等)。 - HRegionServer
维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求,也就是说客户端直接和HRegionServer打交道;负责切分正在运行过程中变得过大的HRegion。
- HRegion
每个HRegion由多个Store构成,每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store,每个Store由一个MemStore和多个StoreFile组成,MemStore是放在内存中的,写到文件后就是StoreFile。StoreFile底层是以HFile的格式保存。
- HLog
HLog(WAL log):WAL意为write ahead log(预写日志),用来做灾难恢复使用,HLog记录数据的变更,包括序列号和实际数据,所以一旦region server 宕机,就可以从log中回滚还没有持久化的数据。
- HFile
HBase的数据最终是以HFile的形式存储在HDFS中的,HBase中HFile有着自己的格式。
小结
本文简单介绍了Hbase分布式数据的数据模型、概念视图、NOSQL特性、整体架构内容。对Hbase的一些关键概念有了初步认识,从整体上对框架有了全局的了解。
希望本文对初学HBase的读者有所帮助,若有遗漏之处欢迎留言讨论。

























