大数据SQL查询引擎 Presto 简介
一、Presto简介
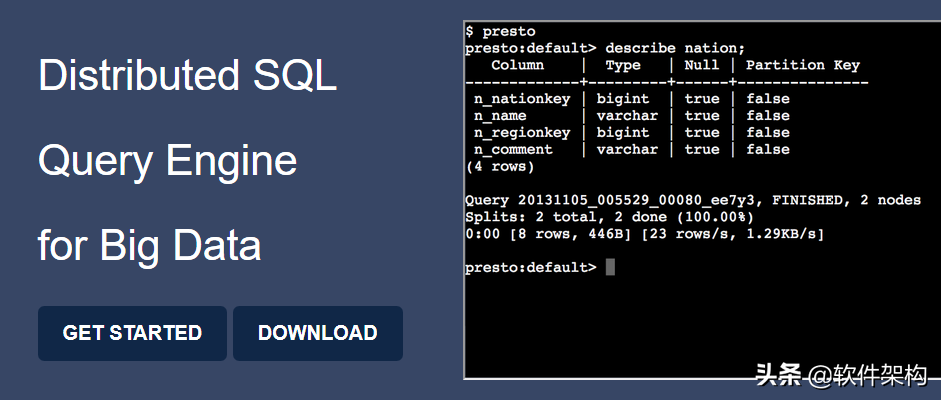
Presto是Facebook开发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。
该项目始于 2012 年秋季开始开发,该项目已经在超过 1000 名 Facebook 雇员中使用,运行超过 30000 个查询,每日数据在 1PB 级别。Facebook 称 Presto 的性能比Hive要好上 10 倍有多。2013年Facebook正式宣布开源 Presto。
二、Presto 执行查询过程
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。

1. Client 发送请求给 Coordinator。
2. SQL 语句通过 ANTLR 进行解析生成 AST。
3. AST 通过元数据进行语义解析。
4. 语义解析后的数据生成逻辑执行计划,并且通过规则进行优化。
5. 切分逻辑执行计划为不同 Stage,并调度 Worker 节点去生成 Task。
6. Task 生成相应物理执行计划。
7. 调度完后根据调度结果 Coordinator 将 Stage 串联起来。
8. Worker 执行相应的物理执行计划。
9. Client 不断地向 Coordinator 拉取查询结果,Coordinator 从最终汇聚输出的 Worker 节点拉取查询结果。

专栏
HBase快速入门和项目开发实践
作者:软件架构
9.9币
5人已购
查看
三、Presto 为何高性能?
* Pipeline, 全内存计算。
* SQL 查询计划规则优化。
* 动态代码生成技术。
* 数据调度本地化,注重内存开销效率,优化数据结构,Cache,非精确查询等其它技术。

























