Redis性能优化:理解与使用Redis Pipeline
当我们谈论redis数据处理和存储的优化方法时,「Redis Pipeline」无疑是一个不能忽视的重要技术。
在使用Redis的过程中,频繁的网络往返操作可能会引发严重的性能问题,尤其是当大量并发操作需要快速响应的时候。这就是我们需要使用Redis Pipeline的原因。
Redis Pipeline是Redis提供的一种功能,主要用于优化大量命令的执行。通过将多个命令组合到一起,进而一次发送到服务器,Pipeline可以显著减少网络延迟带来的影响。
在本文中,我们将详细介绍Redis Pipeline,阐述它如何解决网络延迟问题,并展示如何在实践中使用它以提升你的Redis性能。
Pipeline介绍
首先,Redis客户端执行一条命令分四个过程:
发送命令——〉命令排队 ——〉命令执行 ——〉返回结果
这整个过程称为 Round Trip Time(简称RTT, 往返时间) 。
当进行批量操作时,Redis提供了一些命令如:MGET,MSET可以有效减少RTT。
但大部分命令(如HGETALL,并没有MHGETALL)不支持批量操作,需要消耗N次RTT ,这个时候就需要Pipeline来解决这个问题了。
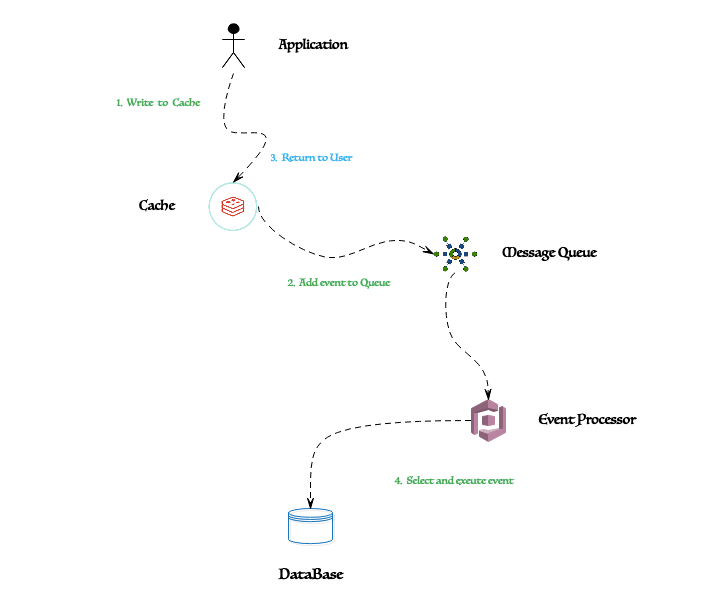
1、未使用Pipeline执行N条命令
2、使用了Pipeline执行N条命令
Pipeline说白了就是通过将多个命令打包到一起然后一次性发送给 Redis 服务器,以减少网络通信次数和延迟,提高操作效率。
在不使用 Pipeline 的情况下,客户端每执行一个 Redis 操作都需要进行一次网络请求并等待服务器响应。但是如果使用了 Pipeline,就会把多个操作合并成一个批次,只需进行一次网络请求即可,服务器在接收到批处理的命令后,会依次执行每个命令,并将结果按命令的执行顺序打包返回给客户端。
这样做的好处是,首先,减少了网络请求数量,从而降低了由于网络延迟带来的总体延迟;其次,因为服务器在同一时间内处理一批命令,所以也能提高服务器的处理效率。
需要注意的是,虽然 Pipeline 能大大提升 Redis 性能,但由于它将多个命令打包成一个请求发送给服务器,所以这些命令无法保证原子性,即这个批次中的某个命令失败不会影响其他命令的执行。
如果Redis服务器在执行一系列命令的过程中发生错误或者崩溃,可能只有部分命令得到执行。要真正实现原子性,还需要使用Redis的事务功能(MULTI, EXEC等命令)。
原生批命令 VS Pipeline
-
原生批命令是原子性的,Pipeline是非原子性的。 -
原生批命令是服务端实现,而Pipeline需要服务端与客户端共同完成。 -
MSET 和 MGET 等批命令是针对特定操作的优化,而 Pipeline 则是一个一般性的解决方案,通常来说性能比Pipeline更好。
Pipeline的优缺点
-
Pipeline 每批打包的命令不能过多,因为 Pipeline 方式打包命令再发送,那么 Redis 必须在处理完所有命令前先缓存起所有命令的处理结果。这样就有一个内存的消耗,可以将大量命令拆分为多个小的Pipeline命令完成。 -
Pipeline 操作是非原子性的,如果要求原子性的,不推荐使用 Pipeline。
一些疑问
Pipeline 每批执行多少条命令合适?
根据官方的解释,推荐是以 10k 每批 (注意:这个是一个参考值,请根据自身实际业务情况调整)。
Pipeline 批量执行的时候,是否对Redis进行了锁定,导致其他应用无法再进行读写?
Redis 采用多路I/O复用模型,非阻塞IO,所以Pipeline批量写入的时候,一定范围内不影响其他的读写操作。
虽然Redis本身支持并发操作,但它还是一个单线程模型,命令依然是顺序执行的。处理Pipeline的时候,从接收到Pipeline开始,到所有命令执行完毕,这期间的所有命令被看作一个整体,其他客户端提交的命令会排在这个整体后面等待执行。
Pipeline代码实现
几乎所有的Redis客户端都支持Pipeline操作,因此实现起来非常容易。以下是一个简单示例代码:
@Test void pipeline() { List<Object> result = redisTemplate.executePipelined((RedisCallback<String>) connection -> { for (int i = 0; i < 100; i++) { redisTemplate.opsForValue().set("pipel:" + i, i); } return null; }); }
在总结今天的内容时,我们了解到Redis Pipeline不仅能够大大提高我们与Redis服务器交互的速度,而且它还可以帮助我们优化网络通信。借助Pipeline,我们能够将多个命令一次性发送给服务器,避免了频繁地进行网络往返,从而减少了延迟并提升了效率。
然而,使用Pipeline也需要谨慎。过多的命令可能会造成阻塞,因此在选择何时以及如何使用Pipeline时,仔细权衡是至关重要的。希望通过这篇文章,你对Redis Pipeline有了更清晰的理解,能够更有效地利用它来优化你的应用程序。