MySQL:InnoDB的页合并与页分裂到底是什么
本文为摘录文章,如有错误,请指正。文章是以MySQL5.7版本进行说明,和现有版本可能会有一定差距,但是数据页的设计基本没有发生过变化,因此,可以作为学习参考。原文为2017年发表的一篇文章:《InnoDB Page Merging and Page Splitting - Percona Database Performance Blog》。
1 文件表(File-Table)结构
在MySQL5.7创建windmills库(schema)和wmills表,在文件目录(/var/lib/mysql)有如下内容:
data/
windmills/
wmills.ibd
wmills.frm
原因是从MySQL5.6开始innodb_file_per_table参数默认设置为1,即:每个表都会单独作为一个文件存储(如果有分区,可能有多个文件)。如果配置为0,则所有的表都是写入公共表空间。
- vmills.ibd文件由多个段(segments)组成,每个段和一个索引有关;
- 段由多个区构成,区仅存于段内,每个区的默认固定大小为1MB(页体积默认情况下);
- 区是由很多数据页构成,默认大小为16KB,即一个分区最多由64个数据页构成。
- 数据页可以容纳2-N行数据行,行的数量取决于数据行的大小;InnoDB要求页至少要有两行,因此行的大小最多为8000bytes。
- 文件的结构不会随着数据行的删除而变化,但是段会跟着区的变化而变化;
 图片
图片
2 根、分支和叶子(Roots,Branches and Leaves)
每个页(逻辑上指的是主键索引的叶子节点)包含2-N行数据行,根据主键排列,树有着特殊的页区管理不同的分支,即内部节点(INodes)。示例如下:
 图片
图片
ROOT NODE #3: 4 records, 68 bytes
NODE POINTER RECORD ≥ (id=2) → #197
INTERNAL NODE #197: 464 records, 7888 bytes
NODE POINTER RECORD ≥ (id=2) → #5
LEAF NODE #5: 57 records, 7524 bytes
RECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", locatinotallow="For beauty's pattern to succeeding men.Yet do thy", active=1, time="2017-03-21 22:05:45", strrecordtype="Wit")
表结构为:
CREATE TABLE `wmills` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`uuid` char(36) COLLATE utf8_bin NOT NULL,
`millid` smallint(6) NOT NULL,
`kwatts_s` int(11) NOT NULL,
`date` date NOT NULL,
`location` varchar(50) COLLATE utf8_bin DEFAULT NULL,
`active` tinyint(2) NOT NULL DEFAULT '1',
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`strrecordtype` char(3) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`),
KEY `IDX_millid` (`millid`)
) ENGINE=InnoDB;
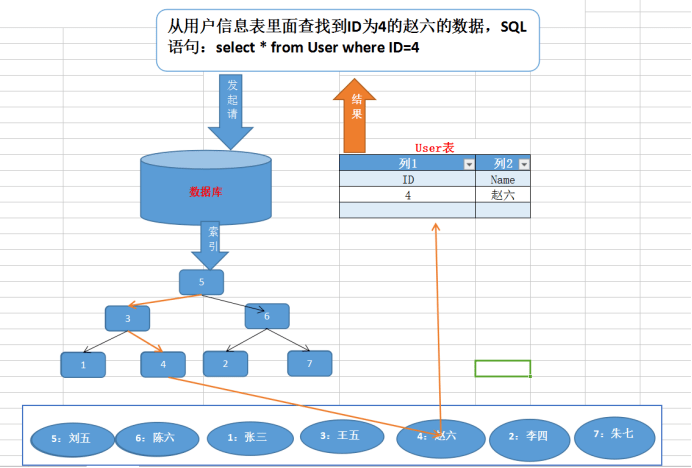
B+树的根节点就是查询的根节点,如图的#3就是根节点。根节点(页)包含了索引ID、INodes数量等信息。INodes页包含了关于页本身的信息、值的范围等。最后还有叶子节点,存储着具体的数据行的全部数据。在示例中,叶子节点#5有57行记录,共7524bytes。这行信息是具体的记录,可以看到数据行内容。
因此, 使用InnoDB管理表和行,InnoDB会将数据以分支、页和记录形式进行组织。InnoDB可操的最小粒度是页,页加载进内存后才会通过扫描页获取行数据(即示例中的record)。
3 页的内部原理(page internals)
数据页的数据会按照主键的顺序来排序,这也是我们在设计表主键时设置为AUTO_INCREMENT的原因,这样在频繁插入时,写入的数据尽可能的写入相同的页,写满后刷盘也可以是顺序写。
 图片
图片
但是如果页的数据比较小,就会导致磁盘和内存空间的浪费,因此,如果 页的数据大小/页大小 小于一定比例,就会做页合并,这个值我们称之为MERGE_THRESHOLD,默认值为50%。
 图片
图片
当本页数据写满后,就会从内存中申请新页(next)进行写入。
 图片
图片
每个叶子节点都有着一个指向包含下一条(顺序)记录的页的指针,这也是InnoDB可以实现自顶向下的遍历和叶子节点顺序范围扫描的能力基础。
4 页合并(page merging)
当执行数据行删除时,并没有物理删除,而是将改行数据标记(flaged)为删除,允许被其他记录声明使用。
 图片
图片
当页中删除的记录达到MERGE_THRESHOLD(默认页体积的50%),InnoDB确认最靠近的前后页是否页达到MERGE_THRESHOLD,如果也已经在限定值之下, 可以将两个页进行合并优化空间使用。如上图,当page#5数据小于50%时,由于page#6数据量也是小于50%,因此会进行页合并,合并后,page#6就会变为空页,可以接纳新数据。
 图片
图片
 图片
图片
在delete/update语句操作中都可能会诱发页合并的发生,关联到当前页的相邻页。如果页合并成功,在INFOMATION_SCHEMA.INNODB_METRICS中的index_page_merge_successful将会增加。
5 页分裂(Page Splits)
假设有如下场景,page#10已经被填满时,继续插入数据,#10没有足够空间去容纳新的记录,根据“下一页”逻辑,记录应该由page#11负责,但是页#11也已经满了。
 图片
图片
 图片
图片
这时候的简化逻辑为:
- 创建新页#12;
- 判断当前页(page#10)可以从哪里进行分裂(记录行里面);
- 移动记录行;
- 重新定义页与页之间的关系;
 图片
图片
新的页#12被创建。
 图片
图片
此时的页与页之间的关系为:
- Page #10 will have Prev=9 and Next=12
- Page #12 Prev=10 and Next=11
- Page #11 Prev=12 and Next=13(page#13是后续顺序插入新增的页);
这样,B+树水平方向的逻辑一致性仍然满足,但是在物理存储上页可能是乱序的,大概率会落到不同的区。
不太清楚这里是否会有疑问,page#10和page#11虽然都已经写满,但是可能已经存在page#12,并且还有大量剩余空间,为什么不做数据迁移呢?这样不就可以不插入新页而导致大量的空间浪费了吗?
虽然从理论上是可行的,但是在实操中,这时候InnoDB就需要先遍历确认next page是否有空余位置,甚至是继续遍历直至找到有空余位置的页,然后进行数据迁移,这个操作可能带来大量遍历的时间复杂度以及数据复制的IO操作,因此,方案不可行。
因此,我们可以总结:页分裂可能发生在执行插入或者更新时,但是可能也会造成页的错位(dislocation),即落入不同的区。
InnoDB用INFORMATION_SCHEMA.INNODB_METRICS表来跟踪页的分裂数。可以查看其中的index_page_splits和index_page_reorg_attempts/successful统计。
当page#12和page#10的数据都低于MERGE_THRESHOLD时,这时候可以通过页合并将数据合并回来。
另一种方式是使用OPTIMIZE重新整理表,可以将大量分布在不同区的页理顺,因此,也是一个很重量级和耗时的过程。
同时,不管是页分裂还是页合并,InnoDB都会在索引树上加写锁(x-latch)。在操作频繁的系统中这会是在隐患,可能会导致索引的锁竞争(index latch contention)。如果表中没有合并和分裂操作(也就是写操作),称之为“乐观(optimistic)”更新,只需要使用读锁(S)。带有合并或者分裂的操作称之为“悲观(pessimistic)”更新,使用写锁(X)。