MySQL对于千万级的大表如何优化
前言
今天发了个沸点,主题是:当年阿里面试,面试官问,sql怎么优化,掘友发起来激烈讨论,我总结了下个人的观点
1. 优化你的sql、索引

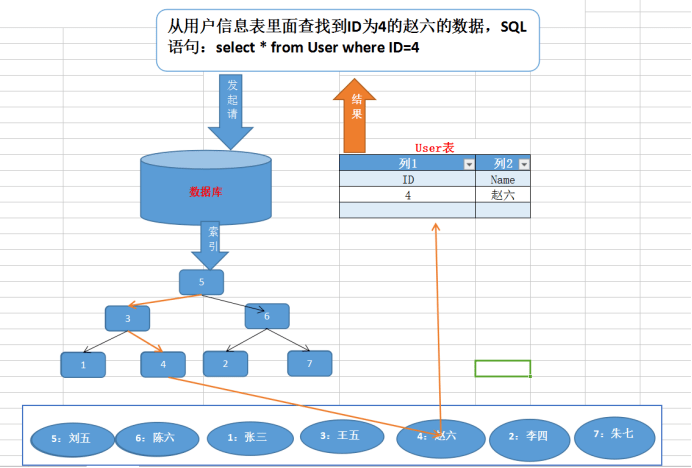
B+树
sql优化
- 避免多表联合查询,优化难度大
- 设置合理的查询字段,避免多次回表
索引
- 建立合适的索引
- 避免索引失效
规范
58到家数据库30条军规解读
2. 引入缓存

- 优点
解决读的性能瓶颈
- 缺点
- 缓存数据库一致性
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 架构复杂(高可用)
3. 读写分离

架构方案
- 客户端直接连接 客户端直连方案,因为少了一层 proxy 转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。 中间件:ShardingSphere
- 带proxy 带 proxy 的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由 proxy 完成的。但这样的话,对后端维护团队的要求会更高。而且,proxy 也需要有高可用架构。因此,带 proxy 架构的整体就相对比较复杂。 中间件:ShardingSphere 、Atlas 、mycat
优点
分担主库的压力
缺点
从延迟,导致往主库写入的数据跟从库读出来的数据不一致
解决方案
- 强制走主库方案;
- sleep 方案; 主库更新后,读从库之前先 sleep 一下。具体的方案就是,类似于执行一条 select sleep(1) 命令。
- 判断主备无延迟方案; seconds_behind_master 参数的值,可以用来衡量主备延迟时间的长短。 seconds_behind_master 是否已经等于 0。如果还不等于 0 ,那就必须等到这个参数变为 0 才能执行查询请求。
- 配合 semi-sync 方案; 事务提交的时候,主库把 binlog 发给从库; 从库收到 binlog 以后,发回给主库一个 ack,表示收到了; 主库收到这个 ack 以后,才能给客户端返回“事务完成”的确认。
- 等主库位点方案;
- Master_Log_File 和 Read_Master_Log_Pos,表示的是读到的主库的最新位点;
- Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是备库执行的最新位点。 如果 Master_Log_File 和 Relay_Master_Log_File、Read_Master_Log_Pos 和 Exec_Master_Log_Pos 这两组值完全相同,就表示接收到的日志已经同步完成。
- 等 GTID 方案。
- Auto_Position=1 ,表示这对主备关系使用了 GTID 协议。
- Retrieved_Gtid_Set,是备库收到的所有日志的 GTID 集合;
- Executed_Gtid_Set,是备库所有已经执行完成的 GTID 集合。 如果这两个集合相同,也表示备库接收到的日志都已经同步完成。
4. 分区表
例子
CREATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);
这个表包含了一个.frm 文件和 4 个.ibd 文件,每个分区对应一个.ibd 文件。 对于引擎层来说,这是 4 个表; 对于 Server 层来说,这是 1 个表。
5. 垂直拆分

优点
- 拆分后业务清晰,拆分规则明确。
- 系统之间整合或扩展容易。
- 数据维护简单。
缺点
- 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
- 事务处理复杂。
6.水平切分

优点
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
缺点
- 主键避免重复(分布式Id)
- 跨节点分页、排序函数
- 数据多次扩展难度跟维护量极大
写作不易,如对你有所帮助,动动你的小手,点赞评论,你们的支持,是对我最大的鼓励!
作者:柯柏技术笔记
链接:
https://juejin.cn/post/7301496780830605375