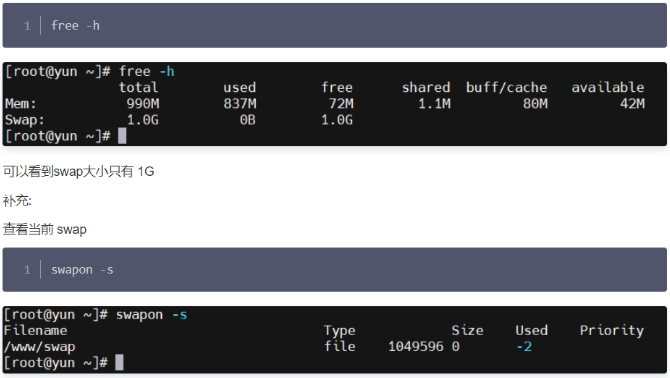
жҹҗдә‘дёҠз”ЁжҲ·еҸҚйҰҲпјҢиҷҡжӢҹжңәcpuиҙҹиҪҪ иҪҜдёӯж–ӯSI жҢҮж Үй«ҳ пјҢиҜ·жұӮдә‘еҺӮе•ҶеҚҸеҠ©жҺ’жҹҘ

д»ҺеӣҫзӨәжқҘзңӢпјҢcpu3 иҪҜдёӯж–ӯд»»еҠЎжҳҺжҳҫ пјҢеӨ§йҮҸзҡ„иҙҹиҪҪдёӯж–ӯйғҪеҸ‘з”ҹеңЁcpu3дёҠ
linux дёӯзҡ„дёӯж–ӯеӨ„зҗҶзЁӢеәҸеҲҶдёәдёҠеҚҠйғЁе’ҢдёӢеҚҠйғЁпјҡ
дёҠеҚҠйғЁеҜ№еә”硬件дёӯж–ӯпјҢз”ЁжқҘеҝ«йҖҹеӨ„зҗҶдёӯж–ӯгҖӮ
дёӢеҚҠйғЁеҜ№еә”иҪҜдёӯж–ӯпјҢз”ЁжқҘејӮжӯҘеӨ„зҗҶдёҠеҚҠйғЁжңӘе®ҢжҲҗзҡ„е·ҘдҪңгҖӮ
Linux дёӯзҡ„иҪҜдёӯж–ӯеҢ…жӢ¬зҪ‘з»ң收еҸ‘гҖҒе®ҡж—¶гҖҒи°ғеәҰгҖҒзӯүеҗ„з§Қзұ»еһӢпјҢеҸҜд»ҘйҖҡиҝҮжҹҘзңӢ /proc/softirqs жқҘи§ӮеҜҹиҪҜдёӯж–ӯзҡ„иҝҗиЎҢжғ…еҶө
жҺ’жҹҘиҝҮзЁӢ
1. vmstat 1 : еҸҜд»ҘзңӢеҲ°cpu жҜҸз§’дёҠдёӢж–ҮеҲҮжҚўе’Ңдёӯж–ӯж¬Ўж•°иҫғеӨҡпјҢcpu жңүиҫғеӨҡйҳҹеҲ—зӯүеҫ…

csпјҲcontext switchпјүжҳҜжҜҸз§’дёҠдёӢж–ҮеҲҮжҚўзҡ„ж¬Ўж•°гҖӮ
inпјҲinterruptпјүеҲҷжҳҜжҜҸз§’дёӯж–ӯзҡ„ж¬Ўж•°гҖӮ
rпјҲRunning or RunnableпјүжҳҜе°ұз»ӘйҳҹеҲ—зҡ„й•ҝеәҰпјҢд№ҹе°ұжҳҜжӯЈеңЁиҝҗиЎҢе’Ңзӯүеҫ…CPUзҡ„иҝӣзЁӢж•°гҖӮ
bпјҲBlockedпјүеҲҷжҳҜеӨ„дәҺдёҚеҸҜдёӯж–ӯзқЎзң зҠ¶жҖҒзҡ„иҝӣзЁӢж•°гҖӮ
2.pidstat -w жҹҘзңӢиҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўжғ…еҶө
# жҜҸйҡ”5з§’иҫ“еҮә1з»„ж•°жҚ®
$ pidsat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 sysemd
08:18:31 0 8 5.40 0.00 rcu_sched
cswch пјҢиЎЁзӨәжҜҸз§’иҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўпјҲvoluntary context switchesпјүзҡ„ж¬Ўж•°пјҢ
nvcswch пјҢиЎЁзӨәжҜҸз§’йқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўпјҲnon voluntary context switchesпјүзҡ„ж¬Ўж•°
3. cat /proc/softirqs : жҹҘзңӢиҪҜдёӯж–ӯз»ҹи®Ў пјҡ еҸҜд»ҘеҲҶжһҗеҸ‘зҺ° пјҢcpu3 дёҠзҡ„дёӯж–ӯжқЎзӣ®жңҖеӨҡпј.NET_RX зҪ‘з»ңж•°жҚ®еҢ…жҺҘ收иҪҜдёӯж–ӯзҡ„еҸҳеҢ–жҜ”иҫғеҝ« пјҢзҪ‘еҚЎж”¶еҸ‘еҢ…еӨ§йғЁеҲҶеӨ„зҗҶйғҪеңЁcpu3 пјҢ еҚ•cpu жңүеӨ„зҗҶйҳ»еЎһзҺ°иұЎ

4.. ethtool -l eth0 жҹҘзңӢзҪ‘еҚЎйҳҹеҲ—жғ…еҶө пјҡ зҪ‘еҚЎйҳҹеҲ—еҸӘжңүдёҖдёӘ пјҢ NET_RX дёӯж–ӯиҙҹиҪҪеңЁcpu3 пјҢеҲқжӯҘе®ҡдҪҚеҚ•йҳҹеҲ—еҺҹеӣ еҜјиҮҙзҪ‘з»ңдёӯж–ӯзҪ‘з»ңдёӯж–ӯдёҚиғҪиҙҹиҪҪеқҮиЎЎпјҢеӨ§йғЁйғҪйӣҶдёӯеңЁcpu3 еӨ„зҗҶ

5.дҪҝиғҪзҪ‘з»ңдёӯж–ӯиҙҹиҪҪеқҮиЎЎ пјҢ жү“з®—и°ғж•ҙиҷҡжӢҹжңәзҪ‘еҚЎйҳҹеҲ—ж•°,virsh edit domain , ж·»еҠ еҰӮдёӢ пјҡ йҳҹеҲ—ж”№жҲҗдёә8

6.еңЁжҺ§еҲ¶еҸ°йҮҚеҗҜиҷҡжӢҹжңә пјҢйҖҡиҝҮVNC зҷ»еҪ•иҷҡжӢҹжңәзңӢжҳҜеҗҰз”ҹж•Ҳ пјҢжЈҖжҹҘе·Із»Ҹз”ҹж•Ҳ

7.еҶҚж¬ЎжҹҘзңӢcpuдёӯж–ӯиҙҹиҪҪжғ…еҶө пјҡ top е‘Ҫд»ӨжҹҘзңӢ пјҡ еҸ‘зҺ°siдёӯж–ӯжҜ”иҫғеҲҶж•ЈеңЁеҗ„дёӘж ёдёҠ пјҢй—®йўҳи§ЈеҶі

йҖҡиҝҮеўһеҠ зҪ‘з»ңеӨҡйҳҹеҲ—пјҢи®©cpu иҪҜдёӯж–ӯиҙҹиҪҪеқҮиЎЎ пјҢй—®йўҳеҫ—еҲ°и§ЈеҶі
дёҫдҫӢиҜҙжҳҺиҪҜдёӯж–ӯжңәеҲ¶ пјҡ
дёҫдёӘз”ҹжҙ»дёӯзҡ„дҫӢеӯҗ"
жҜ”еҰӮиҜҙдҪ и®ўдәҶдёҖд»ҪеӨ–еҚ–пјҢдҪҶжҳҜдёҚзЎ®е®ҡеӨ–еҚ–д»Җд№Ҳж—¶еҖҷйҖҒеҲ°пјҢд№ҹжІЎжңүеҲ«зҡ„ж–№жі•дәҶи§ЈеӨ–еҚ–зҡ„иҝӣеәҰпјҢдҪҶжҳҜпјҢй…ҚйҖҒе‘ҳйҖҒеӨ–еҚ–жҳҜдёҚзӯүдәәзҡ„пјҢеҲ°дәҶдҪ иҝҷе„ҝжІЎдәәеҸ–зҡ„иҜқпјҢе°ұзӣҙжҺҘиө°дәәдәҶгҖӮжүҖд»ҘдҪ еҸӘиғҪиӢҰиӢҰзӯүзқҖпјҢж—¶дёҚж—¶еҺ»й—ЁеҸЈзңӢзңӢеӨ–еҚ–йҖҒеҲ°жІЎпјҢиҖҢдёҚиғҪе№Іе…¶д»–дәӢжғ…гҖӮ
дёҚиҝҮе‘ўпјҢеҰӮжһңеңЁи®ўеӨ–еҚ–зҡ„ж—¶еҖҷпјҢдҪ е°ұи·ҹй…ҚйҖҒе‘ҳзәҰе®ҡеҘҪпјҢи®©д»–йҖҒеҲ°еҗҺз»ҷдҪ жү“дёӘз”өиҜқпјҢйӮЈдҪ е°ұдёҚз”ЁиӢҰиӢҰзӯүеҫ…дәҶпјҢе°ұеҸҜд»ҘеҺ»еҝҷеҲ«зҡ„дәӢжғ…пјҢзӣҙеҲ°з”өиҜқдёҖе“ҚпјҢжҺҘз”өиҜқгҖҒеҸ–еӨ–еҚ–е°ұеҸҜд»ҘдәҶгҖӮ иҝҷйҮҢзҡ„“жү“з”өиҜқ”пјҢе…¶е®һе°ұжҳҜдёҖдёӘдёӯж–ӯгҖӮ
жІЎжҺҘеҲ°з”өиҜқзҡ„ж—¶еҖҷпјҢдҪ еҸҜд»ҘеҒҡе…¶д»–зҡ„дәӢжғ…пјӣеҸӘжңүжҺҘеҲ°дәҶз”өиҜқпјҲд№ҹе°ұжҳҜеҸ‘з”ҹдёӯж–ӯпјүпјҢдҪ жүҚиҰҒиҝӣиЎҢеҸҰдёҖдёӘеҠЁдҪңпјҡеҸ–еӨ–еҚ–гҖӮ
иҝҷдёӘдҫӢеӯҗдҪ е°ұеҸҜд»ҘеҸ‘зҺ°пјҢдёӯж–ӯе…¶е®һжҳҜдёҖз§ҚејӮжӯҘзҡ„дәӢ件еӨ„зҗҶжңәеҲ¶пјҢеҸҜд»ҘжҸҗй«ҳзі»з»ҹзҡ„并еҸ‘еӨ„зҗҶиғҪеҠӣгҖӮ
дәӢе®һдёҠпјҢдёәдәҶи§ЈеҶідёӯж–ӯеӨ„зҗҶзЁӢеәҸжү§иЎҢиҝҮй•ҝе’Ңдёӯж–ӯдёўеӨұзҡ„й—®йўҳпјҢLinux е°Ҷдёӯж–ӯеӨ„зҗҶиҝҮзЁӢеҲҶжҲҗдәҶдёӨдёӘйҳ¶ж®өпјҢд№ҹе°ұжҳҜдёҠеҚҠйғЁе’ҢдёӢеҚҠйғЁпјҡ
дёҠеҚҠйғЁз”ЁжқҘеҝ«йҖҹеӨ„зҗҶдёӯж–ӯпјҢе®ғеңЁдёӯж–ӯзҰҒжӯўжЁЎејҸдёӢиҝҗиЎҢпјҢдё»иҰҒеӨ„зҗҶи·ҹ硬件зҙ§еҜҶзӣёе…іе·ҘдҪңгҖӮ
дёӢеҚҠйғЁз”ЁжқҘ延иҝҹеӨ„зҗҶдёҠеҚҠйғЁжңӘе®ҢжҲҗзҡ„е·ҘдҪңпјҢйҖҡеёёд»ҘеҶ…ж ёзәҝзЁӢзҡ„ж–№ејҸиҝҗиЎҢгҖӮ
жҜ”еҰӮиҜҙеүҚйқўеҸ–еӨ–еҚ–зҡ„дҫӢеӯҗпјҢдёҠеҚҠйғЁе°ұжҳҜдҪ жҺҘеҗ¬з”өиҜқпјҢе‘ҠиҜүй…ҚйҖҒе‘ҳдҪ е·Із»ҸзҹҘйҒ“дәҶпјҢе…¶д»–дәӢе„ҝи§ҒйқўеҶҚиҜҙпјҢ然еҗҺз”өиҜқе°ұеҸҜд»ҘжҢӮж–ӯдәҶпјӣдёӢеҚҠйғЁжүҚжҳҜеҸ–еӨ–еҚ–зҡ„еҠЁдҪңпјҢд»ҘеҸҠи§ҒйқўеҗҺе•ҶйҮҸеҸ‘зҘЁеӨ„зҗҶзҡ„еҠЁдҪңгҖӮ
йҷӨдәҶеҸ–еӨ–еҚ–пјҢжҲ‘еҶҚдёҫдёӘжңҖеёёи§Ғзҡ„зҪ‘еҚЎжҺҘ收数жҚ®еҢ…зҡ„дҫӢеӯҗпјҢи®©дҪ жӣҙеҘҪең°зҗҶи§ЈгҖӮ
зҪ‘еҚЎжҺҘ收еҲ°ж•°жҚ®еҢ…еҗҺпјҢдјҡйҖҡиҝҮ硬件дёӯж–ӯзҡ„ж–№ејҸпјҢйҖҡзҹҘеҶ…ж ёжңүж–°зҡ„ж•°жҚ®еҲ°дәҶгҖӮиҝҷж—¶пјҢеҶ…ж ёе°ұеә”иҜҘи°ғз”Ёдёӯж–ӯеӨ„зҗҶзЁӢеәҸжқҘе“Қеә”е®ғгҖӮ
еҜ№дёҠеҚҠйғЁжқҘиҜҙпјҢ既然жҳҜеҝ«йҖҹеӨ„зҗҶпјҢе…¶е®һе°ұжҳҜиҰҒжҠҠзҪ‘еҚЎзҡ„ж•°жҚ®иҜ»еҲ°еҶ…еӯҳдёӯпјҢ然еҗҺжӣҙж–°дёҖдёӢ硬件еҜ„еӯҳеҷЁзҡ„зҠ¶жҖҒпјҲиЎЁзӨәж•°жҚ®е·Із»ҸиҜ»еҘҪдәҶпјүпјҢжңҖеҗҺеҶҚеҸ‘йҖҒдёҖдёӘиҪҜдёӯж–ӯдҝЎеҸ·пјҢйҖҡзҹҘдёӢеҚҠйғЁеҒҡиҝӣдёҖжӯҘзҡ„еӨ„зҗҶгҖӮ
иҖҢдёӢеҚҠйғЁиў«иҪҜдёӯж–ӯдҝЎеҸ·е”ӨйҶ’еҗҺпјҢйңҖиҰҒд»ҺеҶ…еӯҳдёӯжүҫеҲ°зҪ‘з»ңж•°жҚ®пјҢеҶҚжҢүз…§зҪ‘з»ңеҚҸи®®ж ҲпјҢеҜ№ж•°жҚ®иҝӣиЎҢйҖҗеұӮи§Јжһҗе’ҢеӨ„зҗҶпјҢзӣҙеҲ°жҠҠе®ғйҖҒз»ҷеә”з”ЁзЁӢеәҸгҖӮ
жүҖд»ҘпјҢиҝҷдёӨдёӘйҳ¶ж®өдҪ д№ҹеҸҜд»Ҙиҝҷж ·зҗҶи§Јпјҡ
дёҠеҚҠйғЁзӣҙжҺҘеӨ„зҗҶ硬件иҜ·жұӮпјҢд№ҹе°ұжҳҜжҲ‘们常иҜҙзҡ„зЎ¬дёӯж–ӯпјҢзү№зӮ№жҳҜеҝ«йҖҹжү§иЎҢпјӣ
иҖҢдёӢеҚҠйғЁеҲҷжҳҜз”ұеҶ…ж ёи§ҰеҸ‘пјҢд№ҹе°ұжҳҜжҲ‘们常иҜҙзҡ„иҪҜдёӯж–ӯпјҢзү№зӮ№жҳҜ延иҝҹжү§иЎҢпјӣ
е…¶д»–еңәжҷҜдёҫдҫӢ пјҡ
жҸҗй—® пјҡ з»Ҹеёёеҗ¬еҗҢдәӢиҜҙеӨ§йҮҸзҡ„зҪ‘з»ңе°ҸеҢ…дјҡеҜјиҮҙжҖ§иғҪй—®йўҳпјҢдёәд»Җд№Ҳе‘ў?
еӣһзӯ” пјҡ еӣ дёәеӨ§йҮҸзҡ„зҪ‘з»ңе°ҸеҢ…дјҡеҜјиҮҙйў‘з№Ғзҡ„зЎ¬дёӯж–ӯе’ҢиҪҜдёӯж–ӯпјҢжүҖд»ҘеӨ§йҮҸзҪ‘з»ңе°ҸеҢ…дј иҫ“еҫҲж…ўпјҢдҪҶеҰӮжһңе°ҶзҪ‘з»ңеҢ…дёҖж¬Ўдј йҖ’пјҢжҳҜдёҚжҳҜдјҡеҝ«еҫҲеӨҡе‘ў пјҢе°ұжҳҜиҝҷдёӘйҒ“зҗҶ