序列是Python中最基本的数据结构。所谓的序列,指的是可以连续存放多个值的内存空间,序列中的每个元素都会有一个数字,即它的位置或索引。通过这个索引就能找到序列中的元素 。
在python的序列中,包括列表,字符串,元组,集合和字典。序列支持几个通用的操作,就是可以索引、切片、相加、相乘、检查成员,需要注意的是,集合和字典不支持索引,切片、相加和相乘操作。
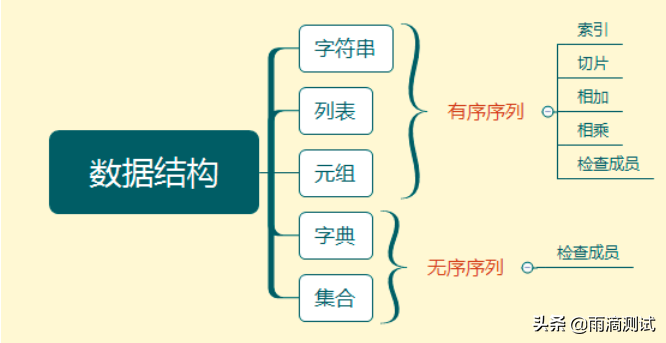
序列中的通用操作
- 通过索引获取元素
就以列表为例,访问列表的元素可以通过下标(也叫索引),默认下标从0开始递增,也就是从左往右递增。当然也可以从右向左计数,这样的话最后一个元素就是从-1开始,依次类推。这也是序列中的一个特性 。
语法:
seq[x] #seq可以是列表,元组,字符串
实例:
lst = ['red', 10, 12.3]
print("第一个元素:",lst[0])
print("第三个元素:",lst[-1])
结果:
#输出:red
#输出12.3
以下是列表中通过下标访问元素的示意图。
- 通过切片获取元素。
切片操作相当于是在列表中访问一定范围的元素,通过切片操作,其实相当于返回了一个新序列 ,这个序列是原来序列的子集。
语法:
seq[start:end:step]
实例:
lst5 = ['red','green','blue','black','gold','orange']
print("获取第2-5个元素:",lst5[1:5]) #有start,end,没有step,默认为1
print("获取第2,4,6个元素:",lst5[1:6:2]) #遵循左闭右开原则,不包括第7个元素
print("获取第1,3,5个元素:",lst5[::2]) #步长为2
print("获取第3个及后面的元素:",lst5[2:])
print("将列表翻转:",lst5[::-1])
结果:
获取第2-5个元素: ['green', 'blue', 'black', 'gold']
获取第2,4,6个元素: ['green', 'black', 'orange']
获取第1,3,5个元素: ['red', 'blue', 'gold']
获取第3个及后面的元素: ['blue', 'black', 'gold', 'orange']
将列表翻转: ['orange', 'gold', 'black', 'blue', 'green', 'red']
说明:
start:表示切片的开始索引位置(包括该位置),也可以不指定,默认为0,也就是从序列的开头进行切片;
end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为列表的长度,注意end不能超过列表的长度,否则会报错;
step:表示切片的步长,如果 step 的值大于 1,则在进行切片操作时,会“跳跃式”的取元素。如果省略设置 step 的值,step的值就为1,则最后一个冒号就可以省略。
- 序列进行相加,相乘
序列还支持序列的相加,相乘操作,以下就以两个两个列表的相加操作为例。
语法:
seq = seq1 + seq2
实例:
a_list = ['abc']
b_list = ['xyz']
c_list = a_list + b_list
print("两个列表相加后产生的新列表:",c_list)
print("列表a_list乘3后产生的新列表:",a_list*3)
结果:
两个列表相加后产生的新列表: ['abc', 'xyz']
两个列表相乘后产生的新列表: ['abc', 'abc', 'abc']
- 检查序列中的元素
检查序列是否存在某个元素可以in关键字 ,同理也可以not in检查元素不在序列中,他们返回的结果是boolean值。
同样以列表为例
语法:
元素 (not)in seq
实例
lst8 = ['red', 'yellow', 'cream', 'blue', 'gunmetal']
print("检查列表lst8中是否包含blue元素:",'blue' in lst8)
print("检查列表lst8中是否不包含black元素:",'blac' not in lst8)
结果:
检查列表lst8中是否包含blue元素: True
检查列表lst8中是否不包含black元素: True
- 序列的方法列表
序列除了以上的操作外,还支持如下的方法:
同样以list为例:
lst=['orange', 'gold', 'black']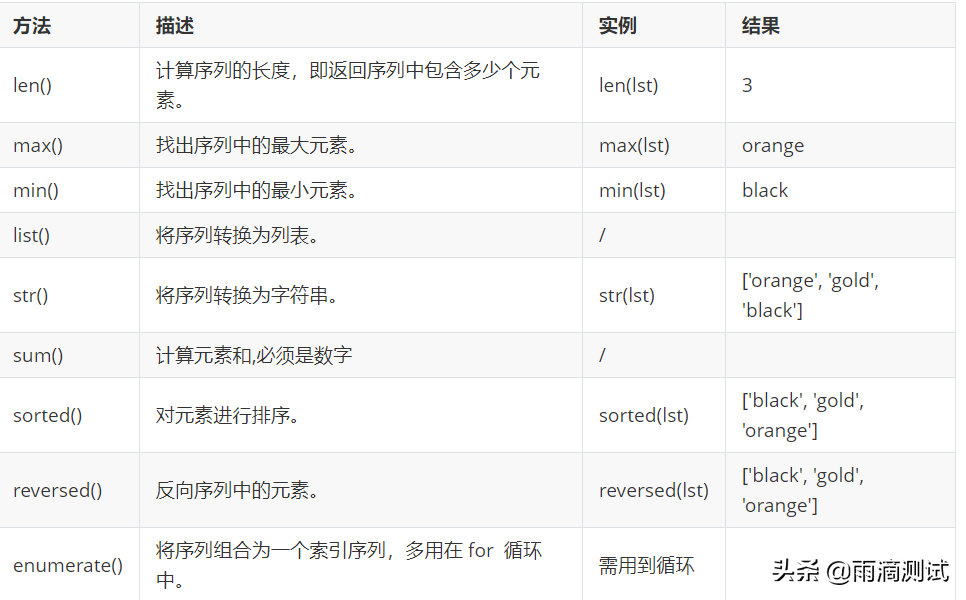
字符串
字符串是python中最常见的一种数据类型,几乎只要开发程序,就离不开对字符串的处理 。字符串的定义非常简单,就是使用单引号或双引号引起来就可以了 。
- 字符串格式化
使用%进行字符串格式化
前面学习的字符串,一旦声明,内容就不会变了。虽然也可以对字符串进行操作来改变字符串的值,但其实变为一个新的字符串了。那么有这样一种场景,声明的字符串中只有一部分会随着场景会发生变化 。比如说,我要定义个“you name is xxx”,那么这个xxx是根据询问的人的不同,给出的答案肯定也不会。那么这样的场景几乎就会用到字符串格式化。
print("your name is %s" % ('zhangan'))
可以看出,%后面的元组数据就是要传入的值,你可以传入张三,也可以是李四。字符串的%其实就是一个占位符,就是说我并不知道这里的字符是啥 ? 但是肯定的是这里有一个字符串 。故使用一个符号站住位置 。注意:%s就是代表后面的字符是字符串 。
除了%s的符号外,python字符串格式化符号还有很多,其中最常用的有格式化整数、格式化浮点数。

格式化操作辅助指令
格式化操作辅助指令主要是针对数字多样化的显示。先来看看主要的辅助指令有:
- m.n : m是显示的最小总宽度,n是小数点后的保留位数
- - : 用作左对齐
- + :在正数前面显示加号(+)
- <sp>: 在正数前显示空格
- 0 : 显示的数字前面填充0而不是默认的空格
print("保留3位数字->'%.3f'" % 659)
print("返回的数字宽度是8位,小数后两位,默认右对齐->'%8.2f'" % 659) #数字宽度8位,数字占了6位,剩余的两位被空格占用
print("返回的数字宽度是8位,小数后两位,设置左对齐->'%-8.2f'" % 659)
print("数字前显示+号->'%+8.2f'" % 659)
print("数字前显示-号->'%+8.2f'" % -659)
print("总宽度是8位,小数后两位,剩余空位用0补齐->'%08.2f'" % 659)
运行结果:
返回的数字宽度是8位,小数后两位,默认右对齐->' 659.00'
返回的数字宽度是8位,小数后两位,设置左对齐->'659.00 '
数字前显示+号->' +659.00'
数字前显示-号->' -659.00'
总宽度是8位,小数后两位,剩余空位用0补齐->'00659.00'
- 使用format()方法进行字符串格式化
除了以上可以字符串格式化外,我们也可以通过format()方法进行字符串格式化,而且它增强了字符串格式化的功能 。
使用format进行格式化的格式: “{}”.format("传入的字符串") ,在前面的字符串中需用{}来进行占位,format()方法中是输入的实际字符串 。同一字符串中可以有多个占位符 。
format也提供了两种参数,分别是位置参数和关键字参数。
print("今天星期{},张三买了{}斤苹果".format('二',3))
print("我是位置参数:{0} {1}".format('hello','python'))
print("我是关键字参数:{x}".format(x='hello'))
运行结果:
今天星期二,张三买了3斤苹果
我是位置参数:hello python
我是关键字参数:hello
需要注意的是,位置参数和关键字参数可以结合起来使用,当它们结合起来使用时,位置参数必须放在关键字前面。
print("位置参数和关键字参数综合应用:{0} {x}".format('hello',x='python'))
#输出:位置参数和关键字参数综合应用:hellop ython
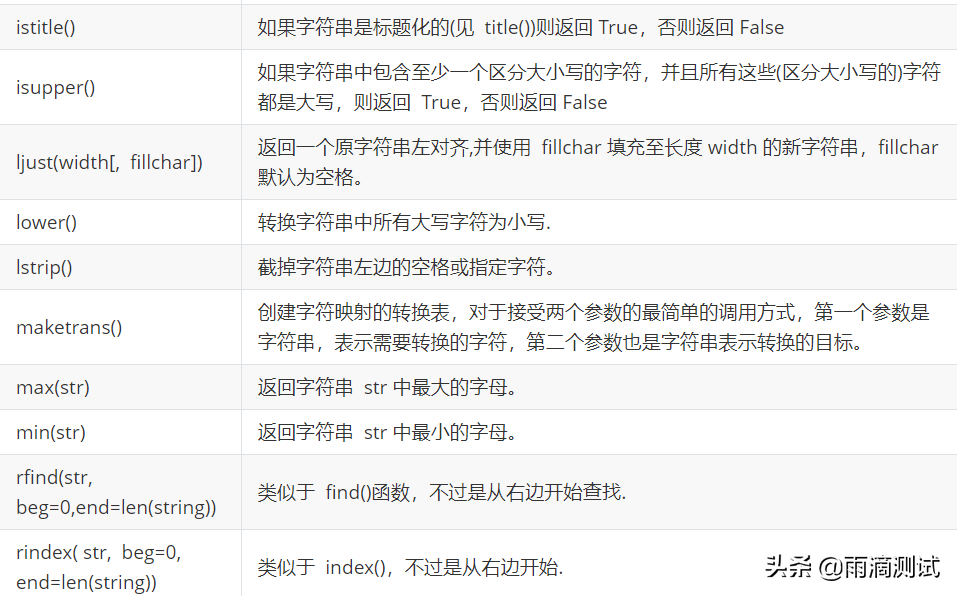
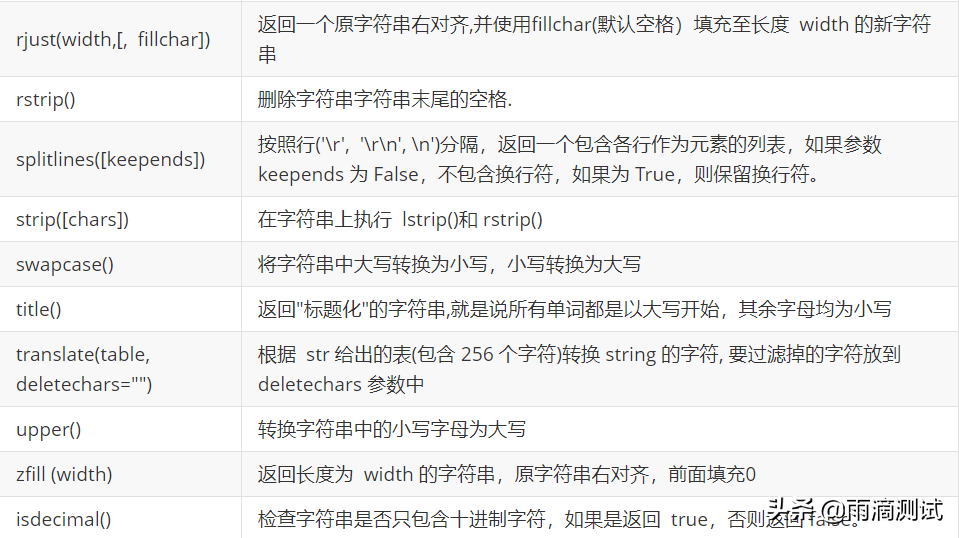
- 字符串方法
以下为字符串的全部方法,可参考 。

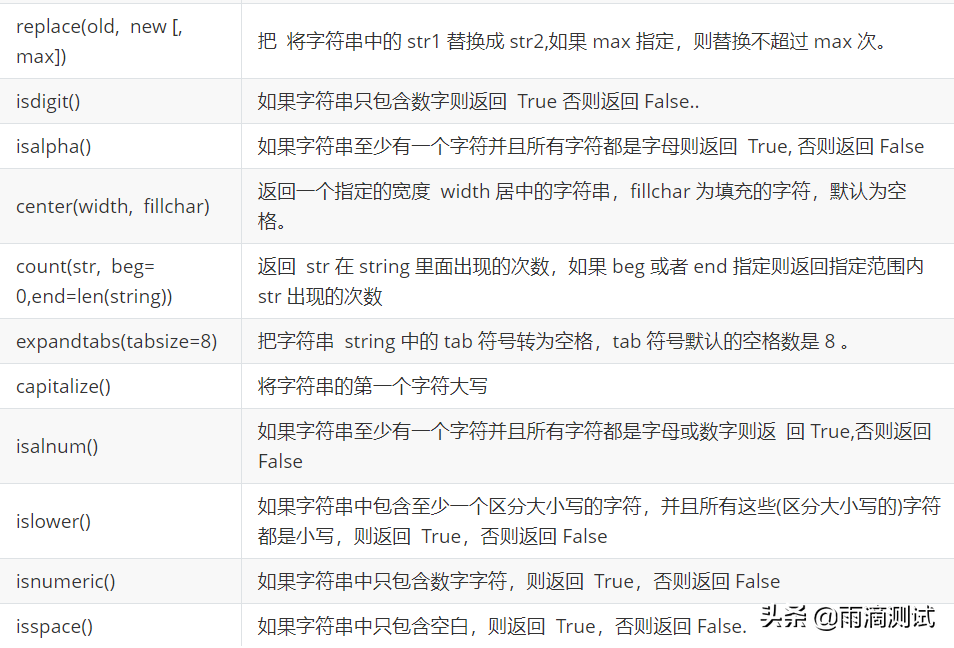
列表
列表属于有序序列的一种,在列表中可以对元素进行增删改查等操作 。
创建列表有两种方式:分别是通过[]中添加元素和list()创建 。
通过[]创建时,列表中的每个元素需要通过逗号隔开。列表中的每个元素可以是整数、字符串、布尔值,空值、列表、元组等任意一种数据类型。
lst1 = ['red',10,12.3]
lst2 = ['blue', None,True,['a','b'],('abc',123)]
print(lst1)
print(lst2)
运行结果
['red', 10, 12.3]
['blue', None, True, ['a', 'b'], ('abc', 123)]
我们还可以通过list()方法创建列表,如下
lst3 = list() #创建了一个空列表
lst4 = list(['green',10,12.3])
print(lst3)
print(lst4)
运行结果
[]
['green', 10, 12.3]
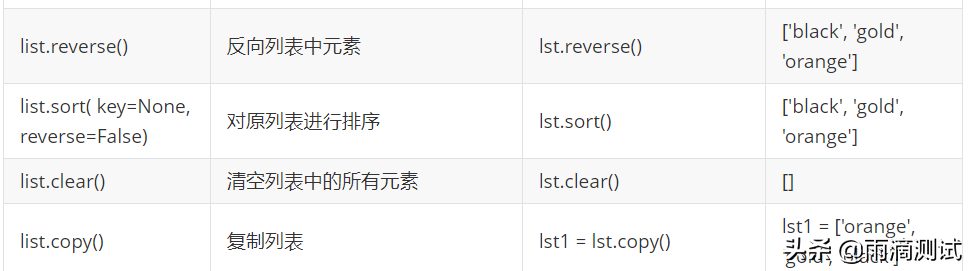
- 列表支持的方法
列表中同样支持很多方法,也是我们最常用到的,具体如下:
lst=['orange', 'gold', 'black']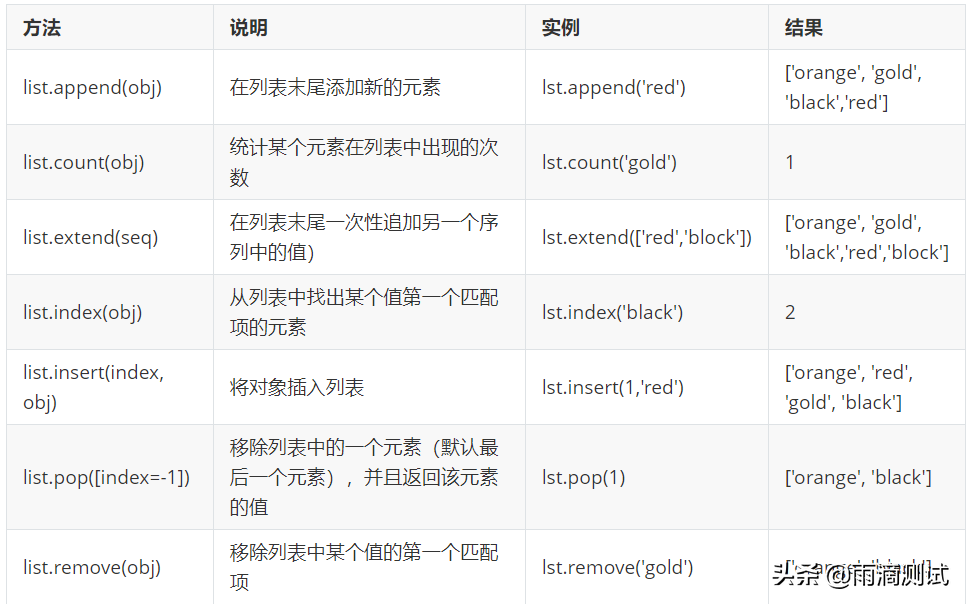
元组
元组是python的另外一种数据类型,和列表相比,它也是一个有序的集合。
元组和列表的差异
- 相同点:列表和元组都是有序列表列表和元组的元素都是通过逗号隔开都支持存放不同数据类型的数据
- 不同点定义不同,列表使用[],元组使用()列表是可变序列,元组是不可变列表 ;即列表中的元素可以进行增、删、改、查,而元组的元素一旦定义就不能进行修改,只能查询元素 。也正是由于这个特性,元组比列表更加更全,假如你定义的数据不希望被别人修改时,那么就可以定义为元组 。
定义元组后,就无法修改其中的元素,所以元组也没有提供对应的方法 。
字典
字典是一种无序的,可变的序列,它的每组元素都有键值对组成,中间用冒号分隔,如果有多组元素的话,元素与元素用逗号隔开 。
字典的语法格式如下:
d = {key1:value1,key2:value2}
字典类型的数据实际使用场景很广,其中最典型的json数据,里面的内容就是由键值对组成 ;或者通过抓包的HTTP请求,你会发现请求报文数据也是有键值对组成 。
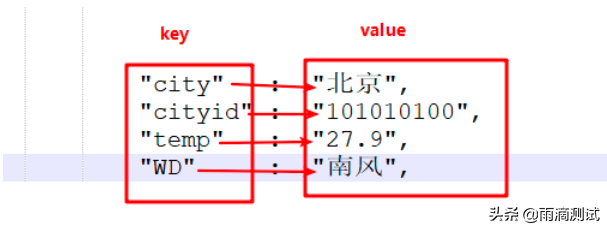
字典里的键必须是唯一的,可以是字符串、数字等不可变数据组成 ,值可以是任何数据类型。
- 字典支持的方法
字典中支持的常用方法如下:
d = {'zhangsan': 23, 'lisi': 35}
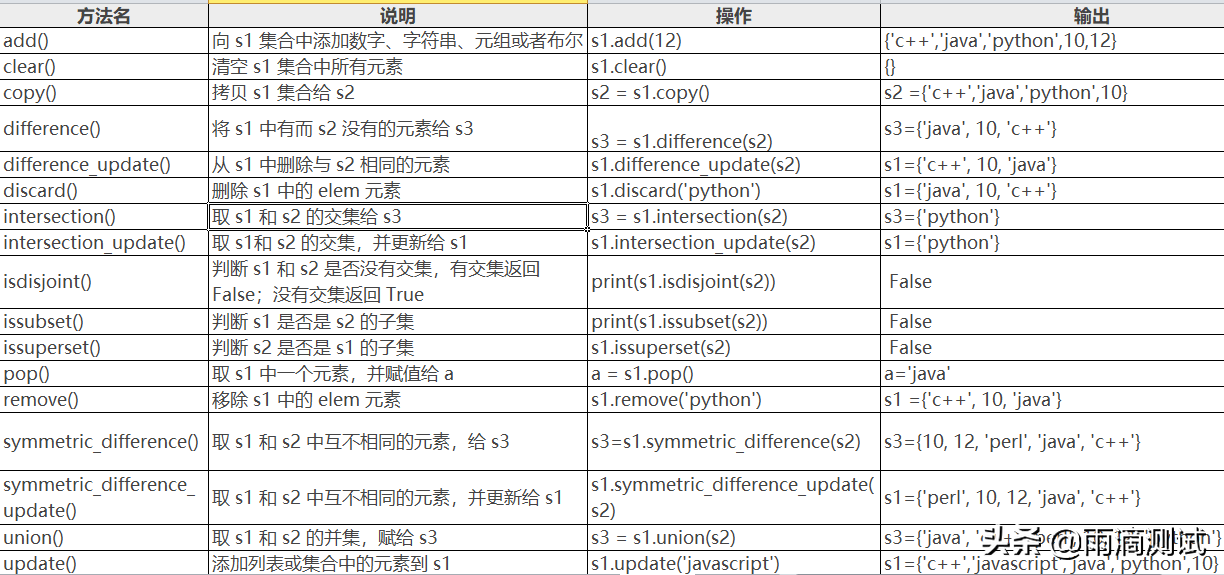
Set集合
集合(set)是一个无序的不重复元素的序列,集合中的元素都是一个唯一的,各不相同。
从语法格式上来看,set的创建和字典一样,都是将元素放在一对大括号{}内,相邻元素之间用逗号(,)分隔 。主要注意的是:创建一个空集合必须使用set()而不是{},因为{}是用来创建一个空字典。
- 集合支持的方法
set集合中也支持很多方法,多数的功能和上面介绍的都差不多,以下为set方法列表 。
s1={'c++','JAVA','python',10}
s2={'perl',12,'python'}