如何用 Python 清洗数据?

0. 序言
在做数据分析之前,我们首先要明确数据分析的目标,然后 应用数据分析的思维,对目标进行细分,再采取相应的行动。
我们可以把数据分析细分为以下 8 个步骤:
(1)读取
(2) 清洗
(3) 操作
(4) 转换
(5) 整理
(6) 分析
(7) 展现
(8)报告
在《 如何用 Python 读取数据? 》这篇文章中,我们学习了从 5 种不同的地方读取数据的方法,接下来,我们将利用其中的一种方法, 从 Excel 文件中读取原始数据,然后利 用 Python 对它进行清洗。
下面我们用一副待清洗的扑克牌作为示例,假设它保存在代码文件相同的目录下,在 Jupyter Lab 环境中运行以下代码:
import numpy as np
import pandas as pd
# 设置最多显示 10 行
pd.set_option('max_rows', 10)
# 从 Excel 文件中读取原始数据
df = pd.read_excel(
'待清洗的扑克牌数据集.xlsx'
)
df
返回结果如下:

这幅待清洗的扑克牌数据集,有一些异常情况,包括:大小王的花色是缺失的,有两张重复的黑桃:spades: A,还有一张异常的 黑桃 :spades: 30。
1. 如何查找异常?
在正式开始清洗数据之前,往往需要先把异常数据找出来,观察异常数据的特征,然后再决定清洗的方法。
# 查找「花色」缺失的行
df[df.花色.isnull()]
# 查找完全重复的行
df[df.duplicated()]
# 查找某一列重复的行
df[df.编号.duplicated()]
# 查找牌面的所有唯一值
df.牌面.unique()
返回结果:
array(['大王', '小王', 'A', '30', 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 2, 3], dtype=object)
根据常识可以判断,牌面为 30 的是异常值。
# 查找「牌面」包含 30 的异常值
df[df.牌面.isin(['30'])]
# 查找王牌,模糊匹配
df[df.牌面.str.contains(
'王', na=False
)]
# 查找编号在 1 到 5 之间的行
df[df.编号.between(1, 5)]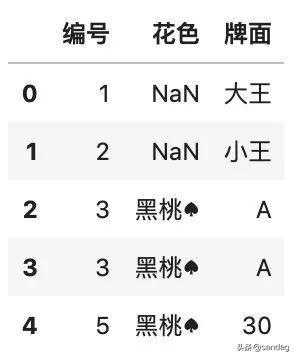
查找某个区间,也可以用逻辑运算的方法来实现:
# 查找编号在 1 到 5 之间的行
df[(df.编号 >= 1)
& (df.编号 <= 5)]
其中「 & 」代表必须同时满足两边的条件,也就是「且」的意思。
还可以用下面等价的方法:
# 查找编号在 1 到 5 之间的行
df[~((df.编号 < 1)
| (df.编号 > 5))]
其中「 | 」代表两边的条件满足一个即可,也就是「或」的意思,「 ~ 」代表取反,也就是「非」的意思。
2. 如何排除重复?
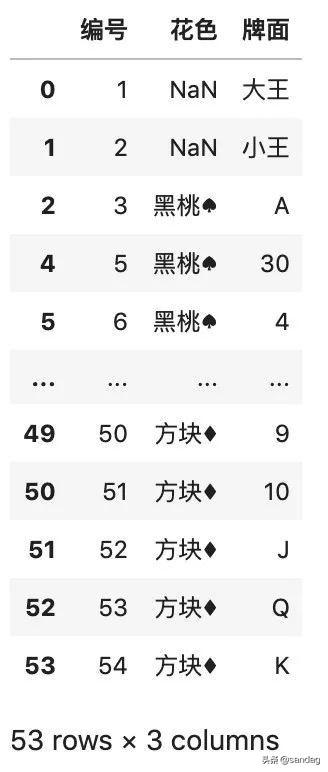
使用 drop_duplicates() 函数,在排除重复之后,会得到一个新的数据框。
# 排除完全重复的行,默认保留第一行
df.drop_duplicates()
返回结果如下:
如果想要改变原来的数据框,有两种方法,一种方法,是增加 inplace 参数:
# 排除重复后直接替换原来的数据框
df.drop_duplicates(
inplace=True
)
另一种方法,是把得到的结果,重新赋值给原来的数据框:
# 排除重复后,重新赋值给原来的数据框
df = df.drop_duplicates()
如果想要按某一列排除重复的数据,那么指定相应的列名即可。
# 按某一列排除重复,默认保留第一行
df.drop_duplicates(['花色'])
如果想要保留重复的最后一行,那么需要指定 keep 参数。
# 按某一列排除重复,并保留最后一行
df.drop_duplicates(
['花色'], keep='last'
)
从上面两个返回结果的编号可以看出,不同方法的差异情况。
3. 如何删除缺失?
使用 dropna() 函数,默认删除包含缺失的行。为了更加简单易懂,我们用扑克牌中不重复的花色作为示例。
# 不重复的花色
color = df.drop_duplicates(
['花色']
)
color

# 删除包含缺失值的行
color.dropna()
如果想要删除整行全部为空的行,那么需要指定 how 参数。
# 删除全部为空的行
color.dropna(how='all')
如果想要删除包含缺失值的列,那么需要指定 axis 参数。
# 删除包含缺失值的列
color.dropna(axis=1)
可以看到,包含缺失值的「花色」这一列被删除了。
4. 如何补全缺失?
使用 fillna() 函数,可以将缺失值填充为我们指定的值。
# 补全缺失值
color.fillna('Joker')
可以看到,原来的 NaN 被填充为 Joker,在实际工作的应用中,通常填充为 0,也就是说, fillna(0) 是比较常见的用法。
如果想要使用临近的值来填充,那么需要指定 method 参数,例如:
# 用后面的值填充
color.fillna(method='bfill')
可以看到,原来第一行的 NaN 替换成了第二行的「黑桃:spades:」。
其中 method 还有一些其他的可选参数,详情可以查看相关的帮助文档。
还有一种按字典填充的方法。为了让下面的演示更加直观易懂,我们先把索引为 2 的牌面设置为缺失值:
# 为了演示,先指定一个缺失值
color.loc[2, '牌面'] = np.nan
color
# 按列自定义补全缺失值
color.fillna(
{'花色': 0, '牌面': 1}
)
可以看出,不同列的缺失值,可以填充为不同的值,花色这一列填充为 0,牌面这一列填充为 1,我在图中分别用红色的方框标记出来了。
5. 应用案例
下面 我们用 Python 代码,把这幅待清洗的扑克牌数据集,变成一副正常的扑克牌数据。
import numpy as np
import pandas as pd
# 设置最多显示 10 行
pd.set_option('max_rows', 10)
# 从 Excel 文件中读取原始数据
df = pd.read_excel(
'待清洗的扑克牌数据集.xlsx'
)
# 补全缺失值
df = df.fillna('Joker')
# 排除重复值
df = df.drop_duplicates()
# 修改异常值
df.loc[4, '牌面'] = 3
# 增加一张缺少的牌
df = df.Append(
{'编号': 4,
'花色': '黑桃♠',
'牌面': 2},
ignore_index=True
)
# 按编号排序
df = df.sort_values('编号')
# 重置索引
df = df.reset_index()
# 删除多余的列
df = df.drop(
['index'], axis=1
)
# 把清洗好的数据保存到 Excel 文件
df.to_excel(
'完成清洗的扑克牌数据.xlsx',
index=False
)
df
返回结果如下:
可以看到,我们已经成功地把它变成了一副正常的扑克牌数据。
6. 小结
我们简单回顾一下本文的主要内容,首先,我们从宏观层面介绍了数据分析的 8 个步骤,然后用一副待清洗的扑克牌数据集作为示例,从读取数据,到查找异常,再到排除重复、删除缺失和补全缺失,最后,我们用一个案例, 完整 演示了清洗数据的过程。
文章作者: 林骥


























