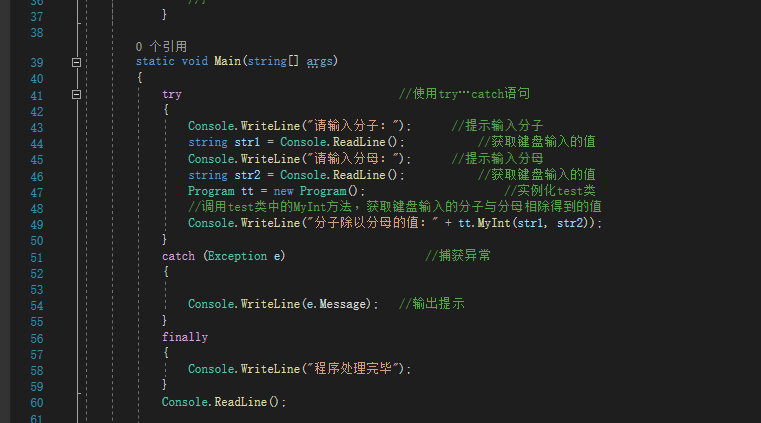
当涉及复杂的高效C代码案例时,这些代码示例展示了C语言中一些复杂且高效的应用案例,涵盖了排序算法、图算法、位操作、文件操作、多线程编程等领域。这些案例体现了C语言在各个领域的广泛应用和高效性,以下是8个经典的例子:
1.快速排序算法:
void quicksort(int arr[], int low, int high) {
if (low < high) {
int pivot = partition(arr, low, high);
quicksort(arr, low, pivot - 1);
quicksort(arr, pivot + 1, high);
}
}
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j <= high - 1; j++) {
if (arr[j] <= pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
这是经典的快速排序算法实现,采用分治思想,通过递归地将数组分成两部分并进行排序,从而实现快速的排序效果。
2.动态规划算法-最长公共子序列(Longest Common Subsequence):
int lcs(char* X, char* Y, int m, int n) {
int L[m + 1][n + 1];
for (int i = 0; i <= m; i++) {
for (int j = 0; j <= n; j++) {
if (i == 0 || j == 0)
L[i][j] = 0;
else if (X[i - 1] == Y[j - 1])
L[i][j] = L[i - 1][j - 1] + 1;
else
L[i][j] = max(L[i - 1][j], L[i][j - 1]);
}
}
return L[m][n];
}
int max(int a, int b) {
return (a > b) ? a : b;
}
这段代码实现了最长公共子序列问题的动态规划解法,通过构建一个二维数组,逐步计算最长公共子序列的长度。
3.哈夫曼编码(Huffman Coding):
struct MinHeapNode {
char data;
unsigned freq;
struct MinHeapNode *left, *right;
};
struct MinHeap {
unsigned size;
unsigned capacity;
struct MinHeapNode** array;
};
struct MinHeapNode* newNode(char data, unsigned freq) {
struct MinHeapNode* temp =
(struct MinHeapNode*)malloc(sizeof(struct MinHeapNode));
temp->left = temp->right = NULL;
temp->data = data;
temp->freq = freq;
return temp;
}
struct MinHeap* createMinHeap(unsigned capacity) {
struct MinHeap* minHeap =
(struct MinHeap*)malloc(sizeof(struct MinHeap));
minHeap->size = 0;
minHeap->capacity = capacity;
minHeap->array =
(struct MinHeapNode**)malloc(minHeap->capacity *
sizeof(struct MinHeapNode*));
return minHeap;
}
void buildMinHeap(struct MinHeap* minHeap, int size)
{
int i;
for (i = (size - 1) / 2; i >= 0; --i)
minHeapify(minHeap, i);
}
void minHeapify(struct MinHeap* minHeap, int idx)
{
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < minHeap->size &&
minHeap->array[left]->freq < minHeap->array[smallest]->freq)
smallest = left;
if (right < minHeap->size &&
minHeap->array[right]->freq < minHeap->array[smallest]->freq)
smallest = right;
if (smallest != idx) {
swapMinHeapNode(&minHeap->array[smallest], &minHeap->array[idx]);
minHeapify(minHeap, smallest);
}
}
void swapMinHeapNode(struct MinHeapNode** a, struct MinHeapNode** b)
{ struct MinHeapNode* t = *a; *a = *b; *b = t; }
int isSizeOne(struct MinHeap* minHeap) { return (minHeap->size == 1); }
struct MinHeapNode* extractMin(struct MinHeap* minHeap) {
struct MinHeapNode* temp = minHeap->array[0];
minHeap->array[0] = minHeap->array[minHeap->size - 1];
--minHeap->size;
minHeapify(minHeap, 0);
return temp; }
void insertMinHeap(struct MinHeap* minHeap, struct MinHeapNode* minHeapNode)
{
++minHeap->size;
int i = minHeap->size - 1;
while (i && minHeapNode->freq < minHeap->array[(i - 1) / 2]->freq)
{
minHeap->array[i] = minHeap->array[(i - 1) / 2];
i = (i - 1) / 2;
}
minHeap->array[i] = minHeapNode;
}
void buildHuffmanTree(char data[], int freq[], int size)
{ struct MinHeapNode* left, * right, * top;
struct MinHeap* minHeap = createMinHeap(size);
for (int i = 0; i < size; ++i)
minHeap->array[i] = newNode(data[i], freq[i]);
minHeap->size = size;
buildMinHeap(minHeap, size);
while (!isSizeOne(minHeap))
{
left = extractMin(minHeap);
right = extractMin(minHeap);
top = newNode('$', left->freq + right->freq);
top->left = left;
top->right = right;
insertMinHeap(minHeap, top);
}
printCodes(minHeap->array[0], "");
}
void printCodes(struct MinHeapNode* root, char* str)
{
if (root == NULL) return;
if (root->data != '$')
printf("%c: %sn", root->data, str);
printCodes(root->left, strcat(str, "0"));
str[strlen(str) - 1] = '�';
printCodes(root->right, strcat(str, "1"));
str[strlen(str) - 1] = '�';
}
这段代码实现了哈夫曼编码的算法,通过构建哈夫曼树并生成每个字符的编码。
4.图的深度优先搜索(Depth-First Search):
#define MAX_VERTICES 100
typedef struct {
int data[MAX_VERTICES];
int top;
} Stack;
void initStack(Stack* stack) {
stack->top = -1;
}
void push(Stack* stack, int value) {
stack->data[++stack->top] = value;
}
int pop(Stack* stack) {
return stack->data[stack->top--];
}
int isEmpty(Stack* stack) {
return stack->top == -1;
}
void dfs(int graph[MAX_VERTICES][MAX_VERTICES], int vertex, int visited[]) {
Stack stack;
initStack(&stack);
push(&stack, vertex);
visited[vertex] = 1;
while (!isEmpty(&stack)) {
int current = pop(&stack);
printf("%d ", current);
for (int i = 0; i < MAX_VERTICES; ++i) {
if (graph[current][i] && !visited[i]) {
push(&stack, i);
visited[i] = 1;
}
}
}
}
这段代码实现了图的深度优先搜索算法,使用栈数据结构来辅助遍历图的顶点,并通过访问数组来记录已访问的顶点。
5.最短路径算法-迪杰斯特拉算法(Dijkstra's Algorithm):
#define MAX_VERTICES 100
#define INF 9999
void dijkstra(int graph[MAX_VERTICES][MAX_VERTICES], int startVertex, int numVertices) {
int dist[MAX_VERTICES];
int visited[MAX_VERTICES];
for (int i = 0; i < numVertices; ++i) {
dist[i] = INF;
visited[i] = 0;
}
dist[startVertex] = 0;
for (int count = 0; count < numVertices - 1; ++count) {
int u = minDistance(dist, visited, numVertices);
visited[u] = 1;
for (int v = 0; v < numVertices; ++v) {
if (!visited[v] && graph[u][v] && dist[u] + graph[u][v] < dist[v]) {
dist[v] = dist[u] + graph[u][v];
}
}
}
printDistances(dist, numVertices);
}
int minDistance(int dist[], int visited[], int numVertices) {
int min = INF, minIndex;
for (int v = 0; v < numVertices; ++v) {
if (!visited[v] && dist[v] <= min) {
min = dist[v];
minIndex = v;
}
}
return minIndex;
}
void printDistances(int dist[], int numVertices) {
printf("VertextDistance from Start Vertexn");
for (int i = 0; i < numVertices; ++i) {
printf("%dt%dn", i, dist[i]);
}
}
这段代码实现了迪杰斯特拉算法,用于求解带权重的图中从起始顶点到其他顶点的最短路径。
6.位操作-计算整数中1的个数:
int countSetBits(int n) {
int count = 0;
while (n)
{
if (n == 0)
return 0;
else
return 1 + countSetBits(n & (n - 1));
}
}
这段代码使用位操作技巧计算一个整数中包含的1的个数,通过不断将整数n与(n-1)进行按位与操作,直到n变为0,统计操作次数即为1的个数。
7.文件操作-统计文件中单词的个数:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_LENGTH 100
int countwords(FILE* file) {
int count = 0;
char word[MAX_LENGTH];
while (fscanf(file, "%s", word) != EOF) {
count++;
}
return count;
}
int mAIn() {
FILE* file = fopen("input.txt", "r");
if (file == NULL) {
printf("File not found.n");
return 1;
}
int wordCount = countWords(file);
printf("Number of words in the file: %dn", wordCount);
fclose(file);
return 0;
}
这段代码读取文件中的内容,按照空格分隔单词,并统计文件中单词的个数。
8.多线程编程-并行计算:
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 4
#define ARRAY_SIZE 10000
int array[ARRAY_SIZE];
int sum = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void* calculateSum(void* arg) {
int threadID = *((int*)arg);
int start = threadID * (ARRAY_SIZE / NUM_THREADS);
int end = start + (ARRAY_SIZE / NUM_THREADS);
int localSum = 0;
for (int i = start; i < end; ++i) {
localSum += array[i];
}
pthread_mutex_lock(&mutex);
sum += localSum;
pthread_mutex_unlock(&mutex);
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int threadIDs[NUM_THREADS];
for (int i = 0; i < ARRAY_SIZE; ++i) {
array[i] = i + 1;
}
for (int i = 0; i < NUM_THREADS; ++i) {
threadIDs[i] = i;
pthread_create(&threads[i], NULL, calculateSum, (void*)&threadIDs[i]);
}
for (int i = 0; i < NUM_THREADS; ++i) {
pthread_join(threads[i], NULL);
}
printf("Sum of array elements: %dn", sum);
return 0;
}
这段代码使用多线程编程实现并行计算一个数组中元素的总和,通过将数组划分为多个部分,并分配给不同的线程进行计算,最后将各线程的计算结果累加得到最终的总和。