C#的并发机制优秀在哪?
作者 | 马超 责编 | 张红月
出品 | CSDN博客
上次用C#写.NET代码差不多还是10多年以前,由于当时JAVA已经颇具王者风范,.Net几乎被打得溃不成军。因此当时笔者对于这个.Net的项目态度比较敷衍了事,没有对其中一些优秀机制有很深的了解,在去年写《C和Java没那么香了,高并发时代谁能称王》时都没给.Net以一席之地,不过最近恰好机缘巧合,我又接手了一个windows方面的项目,这也让我有机会重新审视一下自己关于.Net框架的相关知识。
项目原型要实现的功能并不复杂,主要就是记录移动存储设备中文件拷出的记录,而且需要尽可能少的占用系统资源,而在开发过程中我无意中加了一行看似没有任何效果的代码,使用Invoke方法记录文件拷出情况,这样的操作却让程序执行效率明显会更高,这背后的原因特别值得总结。
一行没用的代码却提高了效率?
由于笔者需要记录的文件拷出信息并没有回显在UI的需要,因此也就没考虑并发冲突的问题,在最初版本的实现中,我对于filesystemwatcher的回调事件,都是直接处理的,如下:
privatevoidDeleteFileHandler( objectsender, FileSystemEventArgs e ) { if(files.Contains(e.FullPath)) { files.Remove(e.FullPath); //一些其它操作 } }这个程序的处理效率在普通的办公PC上如果同时拷出20个文件,那么在拷贝过程中,U盘监测程序的CPU使用率大约是0.7%。
但是一个非常偶然的机会,我使用了Event/Delegate的Invoke机制,结果发现这样一个看似的废操作,却让程序的CPU占用率下降到0.2%左右
privatevoidUdiskWather_Deleted( objectsender, FileSystemEventArgs e ) { if( this.InvokeRequired) { this.Invoke( newDeleteDelegate(DeleteFileHandler), newobject[] { sender,e }); } else { DeleteFileHandler(sender, e); } }在我最初的认识中.net中的Delegate机制在调用过程中是要进行拆、装箱操作的,因此这不拖慢操作就不错了,但实际的验证结果却相反。
看似没用的Invoke到底有什么用
这里先给出结论,Invoke能提升程序执行效率,其关键还是在于线程在多核之间切换的消耗要远远高于拆、装箱的资源消耗,我们知道我们程序的核心就是操作files这个共享变量,每次在被检测的U盘目录中如果发生文件变动,其回调通知函数可能都运行在不同的线程,如下:
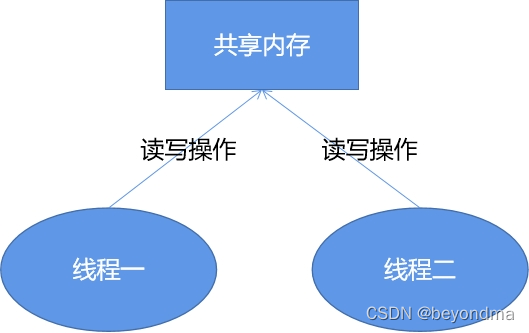
Invoke机制的背后其实就是保证所有对于files这个共享变量的操作,全部都是由一个线程执行完成的。
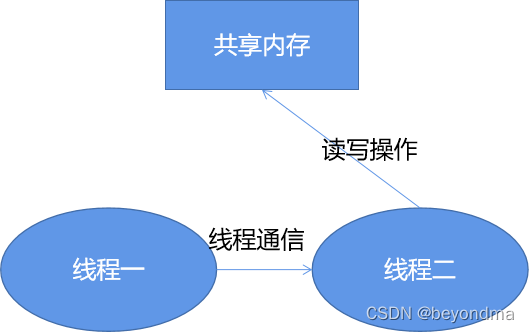
目前.Net的代码都开源的,下面我们大致讲解一下Invoke的调用过程,不管是BeginInvoke还是Invoke背后其实都是调用的MarshaledInvoke方法来完成的,如下:
publicIAsyncResult BeginInvoke( Delegate method, paramsObject[] args ) { using( newMultithreadSafeCallScope) { Control marshaler = FindMarshalingControl; return(IAsyncResult)marshaler.MarshaledInvoke( this, method, args, false); } }MarshaledInvoke的主要工作是创建ThreadMethodEntry对象,并把它放在一个链表里进行管理,然后调用PostMessage将相关信息发给要通信的线程,如下:
privateObject MarshaledInvoke( Control caller, Delegate method, Object[] args, boolsynchronous ) { if(!IsHandleCreated) { thrownewInvalidOperationException(SR.GetString(SR.ErrorNoMarshalingThread)); } ActiveXImpl activeXImpl = (ActiveXImpl)Properties.GetObject(PropActiveXImpl); if(activeXImpl != null) { IntSecurity.UnmanagedCode.Demand; } // We don't want to wait if we're on the same thread, or else we'll deadlock. // It is important that syncSameThread always be false for asynchronous calls. // boolsyncSameThread = false; intpid; // ignored if(SafeNativeMethods.GetWindowThreadProcessId( newHandleRef( this, Handle), outpid) == SafeNativeMethods.GetCurrentThreadId) { if(synchronous) syncSameThread = true; } // Store the compressed stack information from the thread that is calling the Invoke // so we can assign the same security context to the thread that will actually execute // the delegate being passed. // ExecutionContext executionContext = null; if(!syncSameThread) { executionContext = ExecutionContext.Capture; } ThreadMethodEntry tme = newThreadMethodEntry(caller, this, method, args, synchronous, executionContext); lock( this) { if(threadCallbackList == null) { threadCallbackList = newQueue; } } lock(threadCallbackList) { if(threadCallbackMessage == 0) { threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage"); } threadCallbackList.Enqueue(tme); } if(syncSameThread) { InvokeMarshaledCallbacks; } else{ // UnsafeNativeMethods.PostMessage( newHandleRef( this, Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero); } if(synchronous) { if(!tme.IsCompleted) { WaitForWaitHandle(tme.AsyncWaitHandle); } if(tme.exception != null) { throwtme.exception; } returntme.retVal; } else{ return(IAsyncResult)tme; } }Invoke的机制就保证了一个共享变量只能由一个线程维护,这和Go语言使用通信来替代共享内存的设计是暗合的,他们的理念都是 "让同一块内存在同一时间内只被一个线程操作" 。这和现代计算体系结构的多核CPU(SMP)有着密不可分的联系,
这里我们先来科普一下CPU之间的通信MESI协议的内容。我们知道现代的CPU都配备了高速缓存,按照多核高速缓存同步的MESI协议约定,每个缓存行都有四个状态,分别是E(exclusive)、M(modified)、S(shared)、I(invalid),其中:
M:代表该缓存行中的内容被修改,并且该缓存行只被缓存在该CPU中。这个状态代表缓存行的数据和内存中的数据不同。
E:代表该缓存行对应内存中的内容只被该CPU缓存,其他CPU没有缓存该缓存对应内存行中的内容。这个状态的缓存行中的数据与内存的数据一致。
I:代表该缓存行中的内容无效。
S:该状态意味着数据不止存在本地CPU缓存中,还存在其它CPU的缓存中。这个状态的数据和内存中的数据也是一致的。不过只要有CPU修改该缓存行都会使该行状态变成 I 。
四种状态的状态转移图如下:
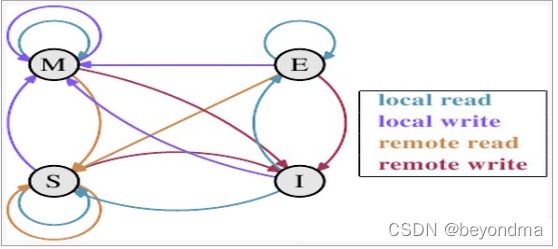
我们上文也提到了,不同的线程是有大概率是运行在不同CPU核上的,在不同CPU操作同一块内存时,站在CPU0的角度上看,就是CPU1会不断发起remote write的操作,这会使该高速缓存的状态总是会在S和I之间进行状态迁移,而一旦状态变为I将耗费比较多的时间进行状态同步。
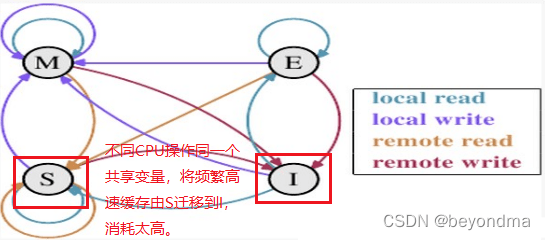
因此我们可以基本得出 this.Invoke(new DeleteDelegate(DeleteFileHandler), new object[] { sender,e }); ;这行看似无关紧要的代码之后,无意中使files共享变量的维护操作,由多核多线程共同操作,变成了众多子线程向主线程通信,所有维护操作均由主线程进行,这也使最终的执行效率有所提高。
深度解读,为何要加两把锁
在当前使用通信替代共享内存的大潮之下,锁其实是最重要的设计。
我们看到在.Net的Invoke实现中,使用了两把锁lock (this) 与lock (threadCallbackList)。
lock( this) { if(threadCallbackList == null) { threadCallbackList = newQueue; } } lock(threadCallbackList) { if(threadCallbackMessage == 0) { threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage"); } threadCallbackList.Enqueue(tme); }在.NET当中lock关键字的基本可以理解为提供了一个近似于CAS的锁(Compare And Swap)。CAS的原理不断地把"期望值"和"实际值"进行比较,当它们相等时,说明持有锁的CPU已经释放了该锁,那么试图获取这把锁的CPU就会尝试将"new"的值(0)写入"p"(交换),以表明自己成为spinlock新的owner。伪代码演示如下:
voidCAS( intp, intold, intnew) { if*p != old donothing else *p ← new }基于CAS的锁效率没问题,尤其是在没有多核竞争的情况CAS表现得尤其优秀,但CAS最大的问题就是不公平,因为如果有多个CPU同时在申请一把锁,那么刚刚释放锁的CPU极可能在下一轮的竞争中获取优势,再次获得这把锁,这样的结果就是一个CPU忙死,而其它CPU却很闲,我们很多时候诟病多核SOC“一核有难,八核围观”其实很多时候都是由这种不公平造成的。
为了解决CAS的不公平问题,业界大神们又引入了TAS(Test And Set Lock)机制,个人感觉还是把TAS中的T理解为Ticket更好记一些,TAS方案中维护了一个请求该锁的头尾索引值,由"head"和"tail"两个索引组成。
structlockStruct{ int32head; int32tail; };"head"代表请求队列的头部,"tail"代表请求队列的尾部,其初始值都为0。
最一开始时,第一个申请的CPU发现该队列的tail值是0,那么这个CPU会直接获取这把锁,并会把tail值更新为1,并在释放该锁时将head值更新为1。
在一般情况下当锁被持有的CPU释放时,该队列的head值会被加1,当其他CPU在试图获取这个锁时,锁的tail值获取到,然后把这个tail值加1,并存储在自己专属的寄存器当中,然后再把更新后的tail值更新到队列的tail当中。接下来就是不断地循环比较,判断该锁当前的"head"值,是否和自己存储在寄存器中的"tail"值相等,相等时则代表成功获得该锁。
TAS这类似于用户到政务大厅去办事时,首先要在叫号机取号,当工作人员广播叫到的号码与你手中的号码一致时,你就获取了办事柜台的所有权。
但是TAS却存在一定的效率问题,根据我们上文介绍的MESI协议,这个lock的头尾索引其实是在各个CPU之间共享的,因此tail和head频繁更新,还是会引发调整缓存不停的invalidate,这会极大的影响效率。
因此我们看到在.Net的实现中干脆就直接引入了threadCallbackList的队列,并不断将tme(ThreadMethodEntry)加入队尾,而接收消息的进程,则不断从队首获取消息。
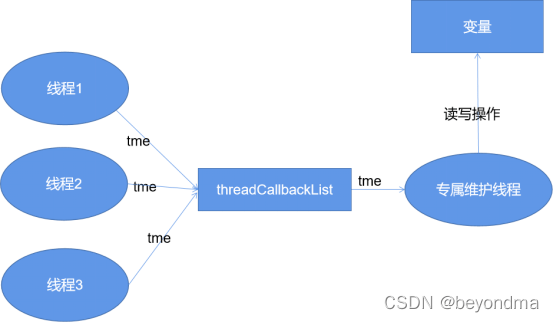
当队首指向这个tme时,消息才被发送,其实是一种类似于MAS的实现,当然MAS实际是为每个CPU都建立了一个专属的队列,和Invoke的设计略有不同,不过基本的思想是一致的。
很多时候年少时不是品不出很多东西背后味道的,这也让我错过了很多非常值得总结的技术要点,因此在春节假期总结一下最近使用C#的心得,以飨读者,顺祝大家新春愉快!
作者简介:马超,金融科技专家,人民大学高礼金融研究院校外双聘导师,阿里云MVP,华为2020年十大开发者之星,CSDN约稿专栏作者,著名的金融科技的布道者。众多国产开源项目的推动者及贡献人。