C语言的指针与多维数组

指针和多维数组有什么关系?为什么要了解它们的关系?处理多维数组的函数要用到指针,所以在使用这种函数之前,先要更深入地学习指针。至于第1个问题,我们通过几个示例来回答。为简化讨论,我们使用较小的数组。假设有下面的声明:
int zippo[4][2]; /* an array of arrays of ints */
然后数组名zippo是该数组首元素的地址。在本例中,zippo的首元素是一个内含两个int值的数组,所以zippo是这个内含两个int值的数组的地址。下面,我们从指针的属性进一步分析。
- 因为zippo是数组首元素的地址,所以zippo的值和&zippo[0]的值相同。而zippo[0]本身是一个内含两个整数的数组,所以zippo[0]的值和它首元素(一个整数)的地址(即&zippo[0][0]的值)相同。简而言之,zippo[0]是一个占用一个int大小对象的地址,而zippo是一个占用两个int大小对象的地址。由于这个整数和内含两个整数的数组都开始于同一个地址,所以zippo和zippo[0]的值相同。
- 给指针或地址加1,其值会增加对应类型大小的数值。在这方面,zippo和zippo[0]不同,因为zippo指向的对象占用了两个int大小,而zippo[0]指向的对象只占用一个int大小。因此,zippo + 1和zippo[0] + 1的值不同。
- 解引用一个指针(在指针前使用*运算符)或在数组名后使用带下标的[]运算符,得到引用对象代表的值。因为zippo[0]是该数组首元素(zippo[0][0])的地址,所以*(zippo[0])表示存储在zippo[0][0]上的值(即一个int类型的值)。与此类似,*zippo代表该数组首元素(zippo[0])的值,但是zippo[0]本身是一个int类型值的地址。该值的地址是&zippo[0][0],所以*zippo就是&zippo[0][0]。对两个表达式应用解引用运算符表明,**zippo与*&zippo[0][0]等价,这相当于zippo[0][0],即一个int类型的值。简而言之,zippo是地址的地址,必须解引用两次才能获得原始值。地址的地址或指针的指针是就是双重间接(double indirection)的例子。
显然,增加数组维数会增加指针的复杂度。现在,大部分初学者都开始意识到指针为什么是C语言中最难的部分。认真思考上述内容,看看是否能用所学的知识解释程序中的程序。该程序显示了一些地址值和数组的内容zippo1.c。
/* zippo1.c -- zippo info */
#include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
printf("zippo = %p, zippo + 1 = %pn",
zippo, zippo + 1);
printf("zippo[0] = %p, zippo[0] + 1 = %pn",
zippo[0], zippo[0] + 1);
printf("*zippo = %p, *zippo + 1 = %pn",
*zippo, *zippo + 1);
printf("zippo[0][0] = %dn", zippo[0][0]);
printf(" *zippo[0] = %dn", *zippo[0]);
printf(" **zippo = %dn", **zippo);
printf(" zippo[2][1] = %dn", zippo[2][1]);
printf("*(*(zippo+2) + 1) = %dn", *(*(zippo+2) + 1));
return 0;
}
下面是我们的系统运行该程序后的输出:
: zippo = 0x7fff26a9a3a0, zippo + 1 = 0x7fff26a9a3a8
: zippo[0] = 0x7fff26a9a3a0, zippo[0] + 1 = 0x7fff26a9a3a4
: *zippo = 0x7fff26a9a3a0, *zippo + 1 = 0x7fff26a9a3a4
: zippo[0][0] = 2
: *zippo[0] = 2
: **zippo = 2
: zippo[2][1] = 3
: *(*(zippo+2) + 1) = 3
其他系统显示的地址值和地址形式可能不同,但是地址之间的关系与以上输出相同。该输出显示了二维数组zippo的地址和一维数组zippo[0]的地址相同。它们的地址都是各自数组首元素的地址,因而与&zippo[0][0]的值也相同。
尽管如此,它们也有差别。在我们的系统中,int是4字节。前面讨论过,zippo[0]指向一个4字节的数据对象。zippo[0]加1,其值加4(十六进制中,38+4得3c)。数组名zippo是一个内含2个int类型值的数组的地址,所以zippo指向一个8字节的数据对象。因此,zippo加1,它所指向的地址加8字节(十六进制中,38+8得40)。
该程序演示了zippo[0]和*zippo完全相同,实际上确实如此。然后,对二维数组名解引用两次,得到存储在数组中的值。使用两个间接运算符(*)或者使用两对方括号([])都能获得该值(还可以使用一个*和一对[],但是我们暂不讨论这么多情况)。
要特别注意,与zippo[2][1]等价的指针表示法是*(*(zippo+2) + 1)。看上去比较复杂,应最好能理解。下面列出了理解该表达式的思路:

以上分析并不是为了说明用指针表示法(*(*(zippo+2) + 1))代替数组表示法(zippo[2][1]),而是提示读者,如果程序恰巧使用一个指向二维数组的指针,而且要通过该指针获取值时,最好用简单的数组表示法,而不是指针表示法。
下图以另一种视图演示了数组地址、数组内容和指针之间的关系。
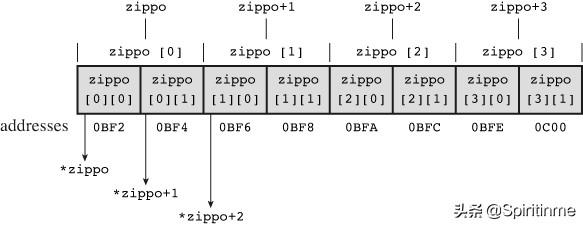
An array of arrays.
指向多维数组的指针
如何声明一个指针变量pz指向一个二维数组(如,zippo)?在编写处理类似zippo这样的二维数组时会用到这样的指针。把指针声明为指向int的类型还不够。因为指向int只能与zippo[0]的类型匹配,说明该指针指向一个int类型的值。但是zippo是它首元素的地址,该元素是一个内含两个int类型值的一维数组。因此,pz必须指向一个内含两个int类型值的数组,而不是指向一个int类型值,其声明如下:
int (* pz)[2]; // pz points to an array of 2 ints
以上代码把pz声明为指向一个数组的指针,该数组内含两个int类型值。为什么要在声明中使用圆括号?因为[]的优先级高于*。考虑下面的声明:
int * pax[2]; // pax is an array of two pointers-to-int
由于[]优先级高,先与pax结合,所以pax成为一个内含两个元素的数组。然后*表示pax数组内含两个指针。最后,int表示pax数组中的指针都指向int类型的值。因此,这行代码声明了两个指向int的指针。而前面有圆括号的版本,*先与pz结合,因此声明的是一个指向数组(内含两个int类型的值)的指针。程序zippo2.c演示了如何使用指向二维数组的指针。
/* zippo2.c -- zippo info via a pointer variable */
#include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
int (*pz)[2];
pz = zippo;
printf(" pz = %p, pz + 1 = %pn",
pz, pz + 1);
printf("pz[0] = %p, pz[0] + 1 = %pn",
pz[0], pz[0] + 1);
printf(" *pz = %p, *pz + 1 = %pn",
*pz, *pz + 1);
printf("pz[0][0] = %dn", pz[0][0]);
printf(" *pz[0] = %dn", *pz[0]);
printf(" **pz = %dn", **pz);
printf(" pz[2][1] = %dn", pz[2][1]);
printf("*(*(pz+2) + 1) = %dn", *(*(pz+2) + 1));
return 0;
}
下面是该程序的输出:
: pz = 0x7ffc3a82bc60, pz + 1 = 0x7ffc3a82bc68
: pz[0] = 0x7ffc3a82bc60, pz[0] + 1 = 0x7ffc3a82bc64
: *pz = 0x7ffc3a82bc60, *pz + 1 = 0x7ffc3a82bc64
: pz[0][0] = 2
: *pz[0] = 2
: **pz = 2
: pz[2][1] = 3
: *(*(pz+2) + 1) = 3
系统不同,输出的地址可能不同,但是地址之间的关系相同。如前所述,虽然pz是一个指针,不是数组名,但是也可以使用pz[2][1]这样的写法。可以用数组表示法或指针表示法来表示一个数组元素,既可以使用数组名,也可以使用指针名:
: zippo[m][n] == *(*(zippo + m) + n)
: pz[m][n] == *(*(pz + m) + n)
指针的兼容性
指针之间的赋值比数值类型之间的赋值要严格。例如,不用类型转换就可以把int类型的值赋给double类型的变量,但是两个类型的指针不能这样做。
int n = 5;
double x;
int * p1 = &n;
double * pd = &x;
x = n; // implicit type conversion
pd = p1; // compile-time error
更复杂的类型也是如此。假设有如下声明:
int * pt;
int (*pa)[3];
int ar1[2][3];
int ar2[3][2];
int **p2; // a pointer to a pointer
有如下的语句:
pt = &ar1[0][0]; // both pointer-to-int
pt = ar1[0]; // both pointer-to-int
pt = ar1; // not valid
pa = ar1; // both pointer-to-int[3]
pa = ar2; // not valid
p2 = &pt; // both pointer-to-int *
*p2 = ar2[0]; // both pointer-to-int
p2 = ar2; // not valid
注意,以上无效的赋值表达式语句中涉及的两个指针都是指向不同的类型。例如,pt指向一个int类型值,而ar1指向一个内含3个int类型元素的数组。类似地,pa指向一个内含3个int类型元素的数组,所以它与ar1的类型兼容,但是ar2指向一个内含2个int类型元素的数组,所以pa与ar2不兼容。
上面的最后两个例子有些棘手。变量p2是指向指针的指针,它指向的指针指向int,而ar2是指向数组的指针,该数组内含2个int类型的元素。所以,p2和ar2的类型不同,不能把ar2赋给p2。但是,*p2是指向int的指针,与ar2[0]兼容。因为ar2[0]是指向该数组首元素(ar2[0][0])的指针,所以ar2[0]也是指向int的指针。
一般而言,多重解引用让人费解。例如,考虑下面的代码:
int x = 20;
const int y = 23;
int * p1 = &x;
const int * p2 = &y;
const int ** pp2;
p1 = p2; // not safe -- assigning const to non-const
p2 = p1; // valid -- assigning non-const to const
pp2 = &p1; // not safe -- assigning nested pointer types
前面提到过,把const指针赋给非const指针不安全,因为这样可以使用新的指针改变const指针指向的数据。编译器在编译代码时,可能会给出警告,执行这样的代码是未定义的。但是把非const指针赋给const指针没问题,前提是只进行一级解引用:
p2 = p1; // valid -- assigning non-const to const
但是进行两级解引用时,这样的赋值也不安全,例如,考虑下面的代码:
const int **pp2;
int *p1;
const int n = 13;
pp2 = &p1; // allowed, but const qualifier disregarded
*pp2 = &n; // valid, both const, but sets p1 to point at n
*p1 = 10; // valid, but tries to change const n
发生了什么?如前所示,标准规定了通过非const指针更改const数据是未定义的。例如,在Terminal中(OS X对底层UNIX系统的访问)使用gcc编译包含以上代码的小程序,导致n最终的值是13,但是在相同系统下使用clang来编译,n最终的值是10。两个编译器都给出指针类型不兼容的警告。当然,可以忽略这些警告,但是最好不要相信该程序运行的结果,这些结果都是未定义的。
C const和C++ const
C和C++中const的用法很相似,但是并不完全相同。区别之一是,C++允许在声明数组大小时使用const整数,而C却不允许。区别之二是,C++的指针赋值检查更严格:
const int y;
const int * p2 = &y;
int * p1;
p1 = p2; // error in C++, possible warning in C
C++不允许把const指针赋给非const指针。而C则允许这样做,但是如果通过p1更改y,其行为是未定义的。
函数和多维数组
如果要编写处理二维数组的函数,首先要能正确地理解指针才能写出声明函数的形参。在函数体中,通常使用数组表示法进行相关操作。下面,我们编写一个处理二维数组的函数。一种方法是,利用for循环把处理一维数组的函数应用到二维数组的每一行。如下所示:
int junk[3][4] = { {2,4,5,8}, {3,5,6,9}, {12,10,8,6} };
int i, j;
int total = 0;
for (i = 0; i < 3 ; i++)
total += sum(junk[i], 4); // junk[i] -- one-dimensional array
记住,如果junk是二维数组,junk[i]就是一维数组,可将其视为二维数组的一行。这里,sum()函数计算二维数组的每行的总和,然后for循环再把每行的总和加起来。
然而,这种方法无法记录行和列的信息。用这种方法计算总和,行和列的信息并不重要。但如果每行代表一年,每列代表一个月,就还需要一个函数计算某列的总和。该函数要知道行和列的信息,可以通过声明正确类型的形参变量来完成,以便函数能正确地传递数组。在这种情况下,数组junk是一个内含3个数组元素的数组,每个元素是内含4个int类型值的数组(即junk是一个3行4列的二维数组)。通过前面的讨论可知,这表明junk是一个指向数组(内含4个int类型值)的指针。可以这样声明函数的形参:
void somefunction( int (* pt)[4] );
另外,如果当且仅当pt是一个函数的形式参数时,可以这样声明:
void somefunction( int pt[][4] );
注意,第1个方括号是空的。空的方括号表明pt是一个指针。这样的变量稍后能以同样的方式用作junk。下面的程序示例中就是这样做的,如程序array2d.c所示。注意该程序清单演示了3种等价的原型语法。
// array2d.c -- functions for 2d arrays
#include <stdio.h>
#define ROWS 3
#define COLS 4
void sum_rows(int ar[][COLS], int rows);
void sum_cols(int [][COLS], int ); // ok to omit names
int sum2d(int (*ar)[COLS], int rows); // another syntax
int main(void)
{
int junk[ROWS][COLS] = {
{2,4,6,8},
{3,5,7,9},
{12,10,8,6}
};
sum_rows(junk, ROWS);
sum_cols(junk, ROWS);
printf("Sum of all elements = %dn", sum2d(junk, ROWS));
return 0;
}
void sum_rows(int ar[][COLS], int rows)
{
int r;
int c;
int tot;
for (r = 0; r < rows; r++)
{
tot = 0;
for (c = 0; c < COLS; c++)
tot += ar[r][c];
printf("row %d: sum = %dn", r, tot);
}
}
void sum_cols(int ar[][COLS], int rows)
{
int r;
int c;
int tot;
for (c = 0; c < COLS; c++)
{
tot = 0;
for (r = 0; r < rows; r++)
tot += ar[r][c];
printf("col %d: sum = %dn", c, tot);
}
}
int sum2d(int ar[][COLS], int rows)
{
int r;
int c;
int tot = 0;
for (r = 0; r < rows; r++)
for (c = 0; c < COLS; c++)
tot += ar[r][c];
return tot;
}
程序array2d.c中的程序把数组名junk(即,指向数组首元素的指针,首元素是子数组)和符号常量ROWS(代表行数3)作为参数传递给函数。每个函数都把ar视为内含数组元素(每个元素是内含4个int类型值的数组)的数组。列数内置在函数体中,但是行数靠函数传递得到。如果传入函数的行数是12,那么函数要处理的是12×4的数组。因为rows是元素的个数,然而,因为每个元素都是数组,或者视为一行,rows也可以看成是行数。
注意,ar和main()中的junk都使用数组表示法。因为ar和junk的类型相同,它们都是指向内含4个int类型值的数组的指针。
注意,下面的声明不正确:
int sum2(int ar[][], int rows); // faulty declaration
前面介绍过,编译器会把数组表示法转换成指针表示法。例如,编译器会把ar[1]转换成ar+1。编译器对ar+1求值,要知道ar所指向的对象大小。下面的声明:
int sum2(int ar[][4], int rows); // valid declaration
表示ar指向一个内含4个int类型值的数组(在我们的系统中,ar指向的对象占16字节),所以ar+1的意思是“该地址加上16字节”。如果第2对方括号是空的,编译器就不知道该怎样处理。也可以在第1对方括号中写上大小,如下所示,但是编译器会忽略该值:
int sum2(int ar[3][4], int rows); // valid declaration, 3 ignored
与使用typedef相比,这种形式方便得多:
typedef int arr4[4]; // arr4 array of 4 int
typedef arr4 arr3x4[3]; // arr3x4 array of 3 arr4
int sum2(arr3x4 ar, int rows); // same as next declaration
int sum2(int ar[3][4], int rows); // same as next declaration
int sum2(int ar[][4], int rows); // standard form
一般而言,声明一个指向N维数组的指针时,只能省略最左边方括号中的值
int sum4d(int ar[][12][20][30], int rows);
因为第1对方括号只用于表明这是一个指针,而其他的方括号则用于描述指针所指向数据对象的类型。下面的声明与该声明等价:
int sum4d(int (*ar)[12][20][30], int rows); // ar a pointer
这里,ar指向一个12×20×30的int数组。