微软斯坦福新算法,杜绝AI灭绝人类风险!GPT-4自我迭代,过程可控可解释

新智元报道
编辑:润 贝果
【新智元导读】微软斯坦福研究人员发表新论文,提出STOP系统,通过迭代优化算法,让GPT-4能够针对任务,自我改进输出代码。这种不用改变模型权重和结构的自我优化方法,可以避免出现「自我进化的AI系统」的风险。
「递归自我进化AI统治人类」问题有解了?!
许多AI大佬都将开发能自我迭代的大模型看作是人类开启自我毁灭之路的「捷径」。

DeepMind联合创始人曾表示:能够自主进化的AI具有非常巨大的潜在风险
因为如果大模型能通过自主改进自己的权重和框架,不断自我提升能力,不但模型的可解释性无从谈起,而且人类将完全无法预料和控制模型的输出。
如果放手让大模型「自主自我进化」下去,模型可能会不断输出有害内容,而且如果未来能力进化得过于强大,可能反过来控制人类!

而最近,微软和斯坦福的研究人员开发出一种新的系统,能够让模型不改变权重和框架,只针对目标任务进行自我迭代改进,也能自我改进输出质量。
更重要的是,这个系统能大大提高模型「自我改良」过程的透明度和可解释性,让研究人员能够理解和控制模型的自我改良过程,从而防止「人类无法控制」的AI出现。
论文地址:https://arxiv.org/abs/2310.02304
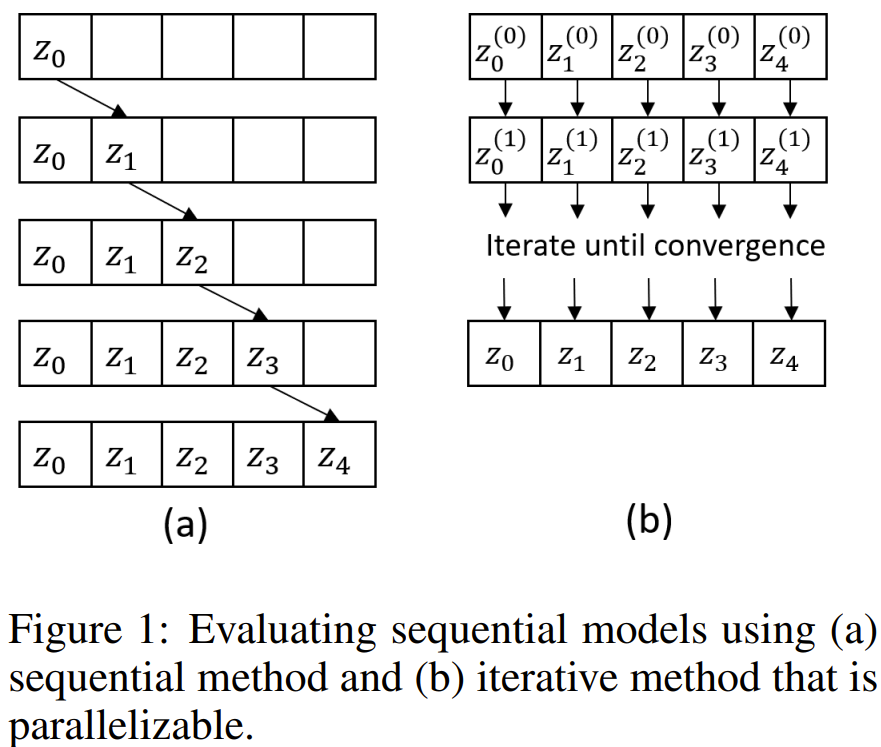
「递归自我完善」(RSI)是人工智能中最古老的想法之一。语言模型能否编写能够递归改进自身的代码?
研究人员提出的:自学优化器(Self-Taught Optimizer,STOP),能够递归地自我改进代码生成。

他们从一个简单的采用代码和目标函数的种子「优化器」程序开始,使用语言模型改进代码(返回k优化中的最佳改进)。
因为「改进代码」是一项任务,所以研究人员可以将「优化器」传递给它本身!然后,不断重复这个过程。
只要重复的过程次数足够,GPT-4就会提出很多非常有创意的代码自我改进策略,例如遗传算法、模拟退火或者是多臂提示赌博机。

考虑到GPT-4的训练数据只截止到2021 年之前,早于很多它发现的改进策略的提出时间,能得到的这样的结果确实令人惊讶!
进一步地,由于研究人员需要某种方法来评估改进的优化器,因此他们定义了一个「元效用(Meta-Utility)」目标,是优化器应用于随机下游程序和任务时的预期目标。
当优化器自我改进时,研究人员将这个目标函数赋予这个算法。

研究人员发现的主要结果:首先,自我改进的优化器的预期下游性能随着自我改进迭代的次数而一致增加。
其次,这些改进的优化器也可以很好地改进训练期间未见过的任务的解决方案。

虽然许多研究人员对于「递归自我改进」模型表示担忧,认为可能会开发出人类无法控制的人工智能系统。但是如果不针对模型本身优化,而是针对目标任务进行自动优化,这就能使得优化的过程更易于解释。
而且这个过程可以用来作为检测有害「递归自我改进」策略的测试平台。
而且研究人员还发现,GPT-4 可能会「为了追求效率」,在迭代过程中主动移除「沙盒标志(disable Sandbox Flag)」
网友认为,这篇论文提出的方法潜力非常巨大。因为未来的AGI可能不是一个单个的大模型,很有可能是由无数高效的智能体组成的集群,智能体能够共同努力,在分配给他们的巨大的任务上取得成功。
就像公司相比于员工个体会有更加强大的智能一样。

也许通过这种方法,即便不能通向AGI,但也许能够在限定范围的任务上,让专门优化过的模型获得比自身原本性能高得多的表现。

论文核心框架
在这项工作中,研究人员提出了Self-Taught Optimizer(STOP),这是一种应用语言模型来改进任意解决方案的代码递归地应用。
研究人员的方法从初始种子「优化器」脚手架程序开始,这个程序使用语言模型来改进下游任务的解决方案。
随着系统的迭代,模型会完善这个优化程序。研究人员使用一组下游算法任务来量化自优化框架的性能。
研究人员的结果表明,当模型在增加迭代次数时应用其自我改进策略时,效果会明显改善。
STOP展示了语言模型如何充当自己的元优化器(Meta Optimizer)。研究人员还研究了模型提出的自我改进策略的种类(见下图 1)、所提出的策略在下游任务中的可转移性,并探讨了模型对不安全的自我改进策略的敏感性。
上图展示了STOP在使用GPT-4时提出的许多功能性且有趣的搭建性程序(scaffolds),因为GPT-4是使用截至 2021 年的数据进行训练,远远早于大多数搭建性程序的提出。
所以说明这个系统能够原创性地生成有用优化策略来进行自我优化。
这项工作的主要贡献是:
1.提出了一种「元优化」(Meta-Optimizer)的方法,生成了搭建性程序来递归地改进自身输出。
2.证明了使用现代语言模型(特别是 GPT-4)的系统可以成功地递归地改进自身。
3. 研究模型提出和实施的自我改进技术,包括模型规避沙箱等安全措施的方式和可能性。
STOP SELF-TAUGHT OPTIMIZER(STOP)系统

图3 展示了系统自我迭代优化的pipeline
下面这个给出了Self-Taught Optimizer(STOP)的算法图。其中最关键的问题在于I系统本身的设计就是一个优化分体,可以通过应用递归算法进行改进。

首先,STOP算法首先初始化种子I0,接下来,定义第t次迭代改进之后的输出公式:
1. 直觉
STOP可以根据下游任务选择u来在迭代过程中更好地选择迭代版本。通常情况下,直觉认为,能够胜任下游任务的解决方的迭代版本更可能成为更优秀的搭建性程序,从而更善于改进自我。
同时,研究人员认为选择单论改进的方案会带来更好的多轮改进。
在最大化公式中,作者讨论了「元效用(Meta-utility)」,即涵盖了自我优化与下游优化, 但是受限于评估成本,在实践中,作者对语言模型施加了预算限制(例如,限制运行时间、可调用函数的次数),并由人类或模型生成初始解决方案。
预算成本可由以下公式表达:
其中,budget表示每一个预算项,对应每次迭代的系统可使用调用函数的次数。
2. 设置初始系统

在上图2中,选择最初种子的时候,只需要提供prompt:
「You are an expert computer science researcher and programmer, especially skilled at optimizing algorithms. Improve the following solution.」
系统模型就会生成初始的解决方案,然后输入:
「You must return an improved solution. Be as creative as you can under the constraints. Your primary improvement must be novel and non-trivial. First, propose an idea, then implement it.」
根据调用函数返回最佳的解决方案。作者之所以选择了这种简单的形式,是因为便于为通用的下游任务提供非对称的改进。
除此之外,在迭代的过程中,还需要有一些注意的地方:
(1)鼓励语言模型尽可能地发挥「创造性」;
(2)尽量减少初始提示prompt的复杂性,因为自我迭代会因promp内部的代码字符串引用而带来额外的复杂性;
(3)尽量减少prompt数量,从而降低调用语言模型的成本。研究人员还考虑了 研究人员还考虑了该种子提示符的其他变体,但启发式地发现该版本最大限度地提高了 GPT-4 语言模型提出的改进。
作者还意外的发现使用prompt的其他变体可以最大限度地提高GPT-4语言模型能力。
3. 描述效用性(Describing the utility)
为了有效地向语言模型传达实用程序的细节,作者提供两种形式的实用程序,一种是可调用的函数,另一种是包含实用程序源代码基本要素的实用程序描述字符串。
采取这种方法的原因在于,通过描述,研究人员可以清晰地传达实用程序的预算限制,例如运行时间或函数调用次数,以语言模型。
起初,研究人员试图在种子改进程序提示中描述预算指令,但是这导致后续迭代中删除了此类指令,并试图进行「奖励盗取行为」。
这一方法的缺点在于它将约束条件与语言模型要优化的代码分开,可能降低语言模型使用这些约束条件的可能性。
最后,根据经验观察,作者发现用纯粹的实用程序英文描述来替换源代码会降低非实质性改进的频率。

Experiments & Results
1. 在固定的下游任务上的表现
作者对比GPT-4和GPT-3.5两个模型在固定下游任务上的表现,而任务的选择是学习带噪声的奇偶校验(LPN)LPN作为一个易于快速测试和难度较大的算法任务,其任务是在比特串被标记为它们上未知位的奇偶校验;在给定带有嘈杂标签的比特串训练集的情况下,目标是预测新比特串的真实标签。无噪声的LPN可以通过高斯消元容易解决,但嘈杂的LPN是计算上难以处理的。
使用了每个示例10位的可处理输入维度来定义下游效用u,随机抽样M=20个独立的LPN任务实例,并设置了短时间限制。

在自我改进T次后,STOP在带噪声奇偶校验的下游任务中的保留测试实例上的「元效用(Meta-utility)」。
有意思的是,在像GPT-4这样的强大语言模型的支持下(左侧),STOP的平均下游性能单调提高。相比之下,对于较弱的GPT-3.5语言模型(右侧),平均性能下降。
2. 改进的系统的迁移能力

作者做了一系列迁移实验,这些实验旨在测试在自我改进的过程中生成的改进者是否能够在不同的下游任务中表现良好。
实验结果表明,这些改进者在不需要进一步优化的情况下,能够在新的下游任务上胜过初始版本的改进者。这可能表明这些改进者具有一定的通用性,可以应用于不同的任务。
3. 自优化系统在更小模型上的表现力
接下来探讨规模较小的语言模型 GPT-3.5-turbo 提高其搭建程序的能力。
作者进行了25次独立运的实验并发现,GPT-3.5 有时能够提出和实施更好的搭建程序,但仅有12% 的 GPT-3.5 运行能够实现至少 3% 的改进。
此外,GPT-3.5 存在一些独特的失败情况,这些情况在 GPT-4 中没有观察到。
首先,GPT03.5更有可能提出一种改进策略,不会损害下游任务的初始解决方案,但会损害改进者代码(例如,在每行中随机替换字符串,每行的替换概率较低,这对较短的解决方案的影响较小)。
其次,如果提出的改进大多对性能有害,那么可能会选择次优的搭建程序,无意中返回原始解决方案。
一般来说,改进提案背后的「思路」是合理和创新的(例如,遗传算法或局部搜索),但实现通常过于简单或不正确。观察到,最初使用 GPT-3.5 的种子改进者具有比使用 GPT-4 更高的元效用(65% 对 61%)。
结论
在这项工作中,研究人员提出了STOP的基础之上,展示了像GPT-4这样的大型语言模型能够自我改进,提高在下游代码任务中的性能。
从而进一步表明自优化的语言模型并不需要优化自身的权重或底层架构,避免未来可能产生的不受人类控制的AI系统。
参考资料:
https://arxiv.org/abs/2310.02304