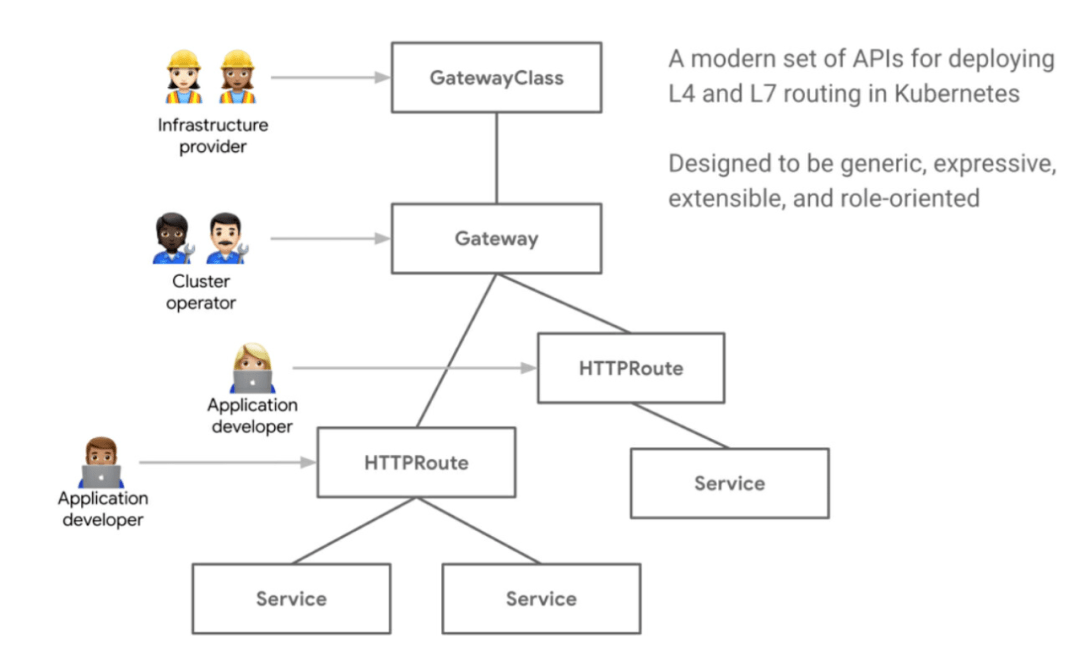
在当今大数据时代,数据湖作为一种新兴的数据存储和分析解决方案,正受到越来越多企业的青睐。而作为一种高性能、可扩展的事件流平台,Kafka在数据湖领域发挥着重要的作用。本文将深入探讨Kafka作为数据湖的优势,以及它所具备的所有数据湖属性。
首先,Kafka具备ACID属性。Kafka已经发展到包含所有类似数据库的属性,特别是原子性、一致性、隔离性和持久性(ACID)。这意味着Kafka不仅可以存储最近的数据,还可以无限保留大量的历史数据,类似于现代数据湖的特性。这使得Kafka成为存储和管理大规模数据的理想选择。
其次,Kafka支持分层存储。以前,人们犹豫是否使用Kafka存储长期数据的一个关键原因是认为Kafka是基于高性能机器的,其使用价格昂贵。然而,随着Kafka的发展,这种情况已经发生了变化。最新版本的Kafka以及其他流行的事件流平台如Redpanda和ApachePulsar都采用了分层存储的设计。这种设计将冷数据存储在廉价的对象存储中,从而降低了成本,并使得持久化存储大量数据成为可能。这使得Kafka能够以低成本存储和管理大规模数据,而无需担心可扩展性的问题。
第三,Kafka具备存储实时数据的能力。尽管许多人使用数据湖来存储历史数据,但现代数据湖正在不断发展并变得越来越实时化。越来越多的人开始使用数据湖来支持流批一体的能力。作为一个事件流平台,Kafka天生就支持实时数据摄取。其架构非常适合存储快速移动的实时数据和缓慢移动的历史数据。这使得企业能够及时获取和分析实时数据,从而做出更准确的决策和预测。
此外,Kafka还可以存储不同类型的数据。无论是关系数据、半结构化数据如JSON和Avro,还是非结构化数据如文本文档、图像和视频,Kafka都能够处理多种数据类型。这种多功能性在当今多样化的数据环境中至关重要,它使得Kafka能够充当组织所有数据的集中存储库,从而降低管理多个存储解决方案的复杂性和开销。企业可以将所有类型的数据存储在Kafka中,实现数据的集中管理和统一访问。
综上所述,Kafka作为一种高性能、可扩展的事件流平台,具备ACID属性、支持分层存储、能够存储实时数据以及处理不同类型数据的能力,完全符合数据湖的要求。它能够满足企业对于高性能、可扩展性和多功能性的需求,帮助企业构建强大的数据湖,实现对大规模数据的搜索和分析。Kafka的出色表现使得它成为解锁大数据时代的重要工具,为企业带来了无限的商业价值。