sqltoy-orm4.18.22发版,别在jpa和mybatis之间争了
- 开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
- 更新内容
1、在findEntity中EntityQuery可以设置fetchSize,在sqltoyContext中可以全局设置fetchSize,实现查询数据提取的性能
2、针对一些特殊原因导致表名是数据库关键词场景的兼容
- ORM的最佳形态:类JPA对象式操作+超强查询
- jpa对象式操作:dao.save(entity)/saveAll(List<Entity>)/update(entity)/load(new Entity(id)) 模式,简单直接,对此大家基本能形成共识,也是各种ORM差异最小的。sqltoy在这个方面相信是对等的,因为是共识理论上来说不必要每次都提及!

2. 超强查询:最理想的状态就是:第一在数据库客户端调试好的sql 最直观高效地移入项目工程中;第二、在需求变化时最简单快速的可以从工程中放入数据库客户端中进行调试。也就是说要最大限度地保持sql的原始面貌;

最合理的sql编写模式

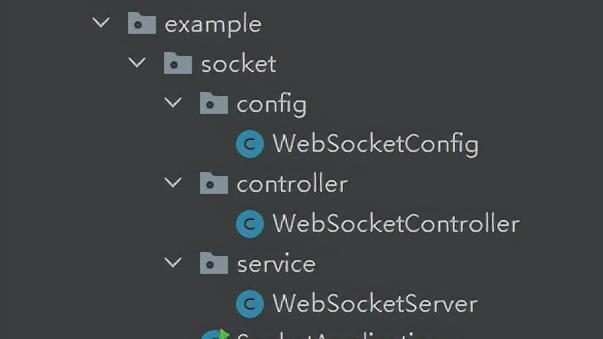
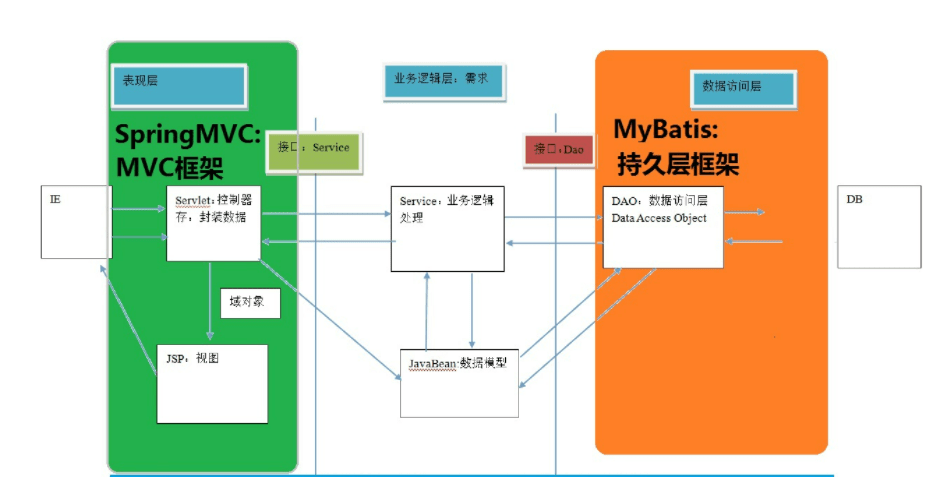
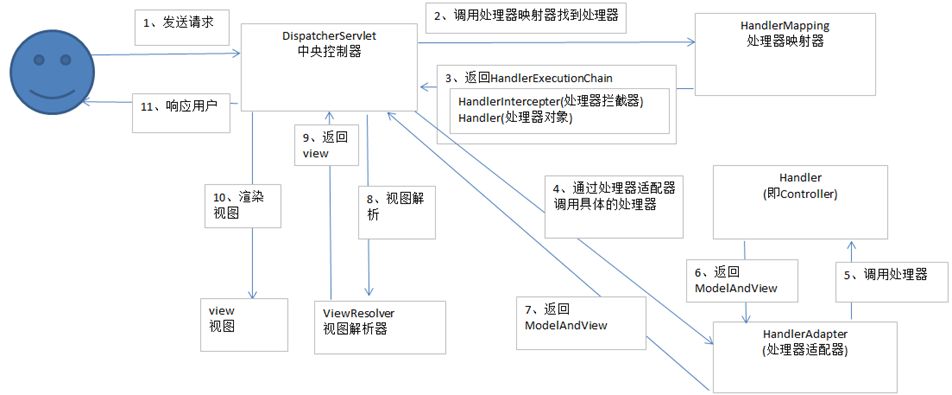
mybatis 的sql如何高效维护?
- 用ORM我们真真正正的痛点是什么?
1、sql的编写和后期维护,上面的图例已经说明问题。
2、执行效率:当同样功能效率有几倍差距时其实就是天壤之别了,带来的直接效果就是:一边是用户的高度夸赞、一边是用户的鄙视,您能理解这是什么差距吗?
- sqltoy的缓存翻译,大幅减少表关联简化sql,让你的查询性能成几何级提升

缓存翻译减少关联查询
- 极致的分页,同样帮助你实现查询的性能大幅提升
- 快速分页:@fast() 实现先取单页数据然后再关联查询,极大提升速度
- 分页优化器:page-optimize 让分页查询由两次变成1.3~1.5次(用缓存实现相同查询条件的总记录数量在一定周期内无需重复查询
- sqltoy的分页取总记录的过程不是简单的select count(1) from (原始sql);而是智能判断是否变成:select count(1) from 'from后语句', 并自动剔除最外层的order by
- sqltoy支持并行查询:parallel="true",同时查询总记录数和单页数据,大幅提升性能
- 在极特殊情况下sqltoy分页考虑是最优化的,如:with t1 as (),t2 as @fast(select * from table1) select * from xxx 这种复杂查询的分页的处理,sqltoy的count查询会是:with t1 as () select count(1) from table1, 如果是:with t1 as @fast(select * from table1) select * from t1 ,count sql 就是:select count(1) from table1

最极致的分页
- 做过统计分析的您,害怕数据旋转吗?害怕同比环比吗?

- 无限极分组统计(含汇总求平均),算法配置简单又跨数据库!

- 同比环比

- sqltoy还有什么?
因为篇幅原因,这里不过多展开,我相信您想要的,在sqltoy中基本都可以找到满意的答案!比如:分库分表、树形数据处理、sql跨数据库等等!
- 致谢
感谢广大网友的支持,提出宝贵的反馈意见,sqltoy的一步步的成熟是大家独到的眼光和敢于试错的精神加入到sqltoy这个还处于发展中的框架用户群体中来!也祝愿sqltoy可以帮助到大家,愿大家可以工作生活平衡!