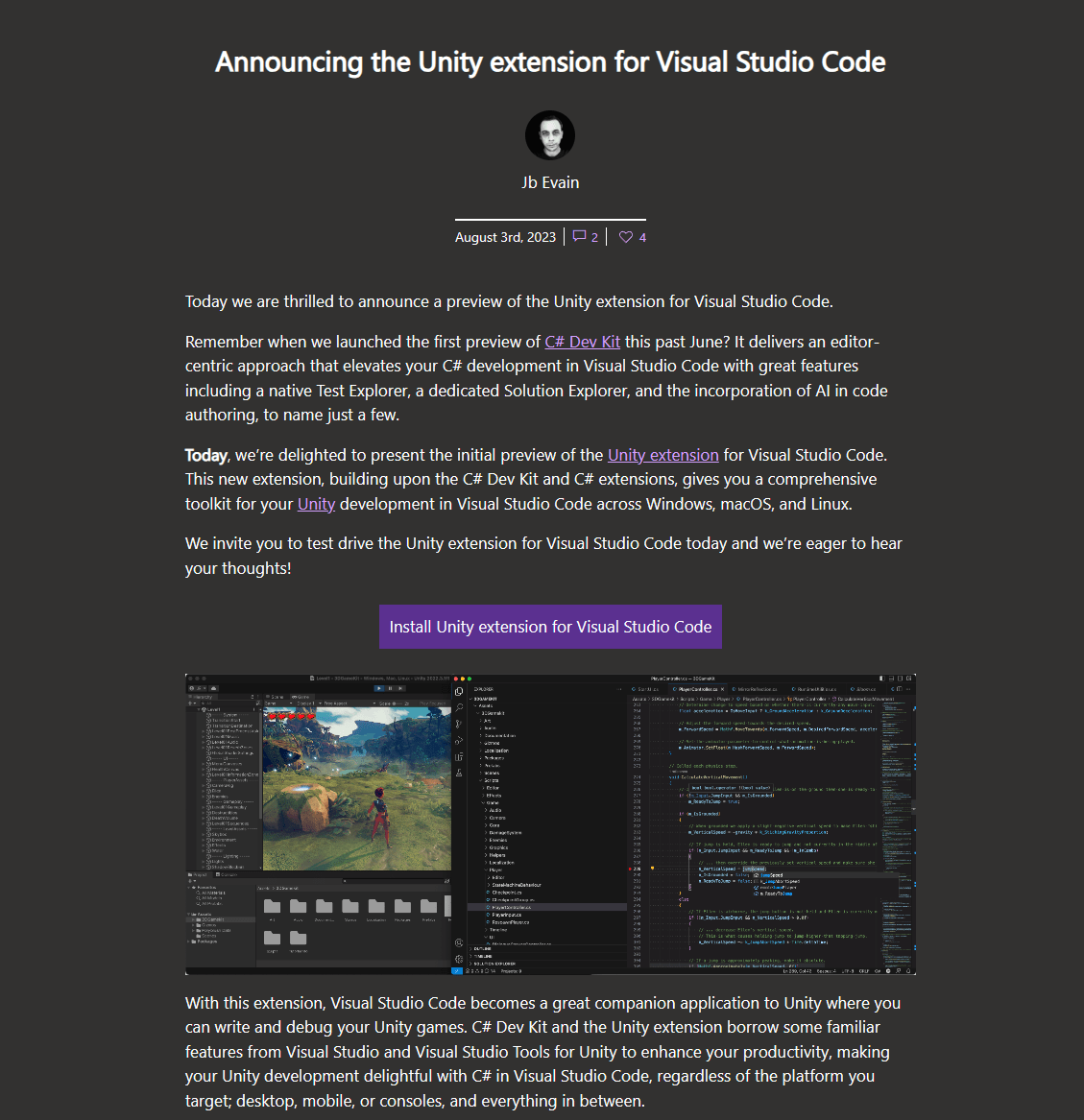
Kubernetes 多区域扩展轻松搞定:远不像你想象的那么难!
对 Kube.NETes 来说,跨越多个地域(Region)部署工作负载,这是个有趣的挑战。虽然从技术上来说,我们可以用分布在多个地域的节点创建集群,但因为会造成额外的延迟,通常并不建议这样做。
一种比较流行的替代方法是在每个地域部署一个集群,然后设法对多个集群进行必要的编排。

本文将介绍如何:
- 分别在北美、欧洲和东南亚各自创建一个集群。
- 创建第四个集群,将其作为上述三个集群的编排器。
- 设置一个将三个集群连接在一起的网络,从而实现跨集群的无缝通信。
本文涉及的操作均可通过脚本实现,只需最少量人工介入即可适用于 Terraform。相关代码请访问 LearnK8s Github。
创建集群管理器
首先创建用于管理其余集群的集群。我们可以通过下列命令创建该集群并保存 Kubeconfig 文件。
bash
$ linode-cli lke cluster-create
--label cluster-manager
--region eu-west
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tAIl +2 | base64 -d > kubeconfig-cluster-manager
随后可通过下列命令验证安装过程已成功完成:
bash
$ kubectl get pods -A --kubecnotallow=kubeconfig-cluster-manager
我们还需要在集群管理器中安装 Karmada,这个管理系统可以帮助我们跨越多个 Kubernetes 集群或多个云平台运行自己的云原生应用程序。Karmada 是一种安装在集群管理器中的控制平面,其他集群中需要安装代理程序。
该控制平面包含三个组件:
- 一个 API 服务器(API Server)
- 一个控制器管理器(Controller Manager)
- 一个调度器(Scheduler)

是否看起来觉得很熟悉?这是因为它与 Kubernetes 控制平面功能其实是相同组件,只不过 Karmada 能适用于多种集群。
理论部分说的差不多了,接下来开始看看具体要用的代码。我们可以使用 Helm 安装 Karmada API 服务器。为此可使用下列命令添加 Helm 仓库:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
由于 Karmada API 服务器必须能被所有其他集群访问,因此我们必须:
- 从节点上将其暴露出来;并且
- 确保连接是可信任的。
因此首先需要通过下列命令获取承载了控制平面的节点的 IP 地址:
bash
kubectl get nodes -o jsnotallow='{.items[0].status.addresses[?(@.type=="ExternalIP")].address}'
--kubecnotallow=kubeconfig-cluster-manager
随后即可用下列命令安装 Karmada 控制平面:
bash
$ helm install karmada karmada-charts/karmada
--kubecnotallow=kubeconfig-cluster-manager
--create-namespace --namespace karmada-system
--versinotallow=1.2.0
--set apiServer.hostNetwork=false
--set apiServer.serviceType=NodePort
--set apiServer.nodePort=32443
--set certs.auto.hosts[0]="kubernetes.default.svc"
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local"
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local"
--set certs.auto.hosts[3]="*.karmada-system.svc"
--set certs.auto.hosts[4]="localhost"
--set certs.auto.hosts[5]="127.0.0.1"
--set certs.auto.hosts[6]="<insert the IP address of the node>"
安装完成后,即可通过下列命令获得 Kubeconfig 并连接到 Karmada API:
bash
kubectl get secret karmada-kubeconfig
--kubecnotallow=kubeconfig-cluster-manager
-n karmada-system
-o jsnotallow={.data.kubeconfig} | base64 -d > karmada-config
不过为什么这里要用另一个 Kubeconfig 文件?
按照设计,Karmada API 是为了取代标准的 Kubernetes API,同时依然提供了用户需要的全部功能。换句话说,我们可以借助 kubectl 创建横跨多个集群的部署。
在测试 Karmada API 和 kubectl 之前,还需要调整 Kubeconfig 文件。默认情况下生成的 Kubeconfig 只能在集群网络的内部使用。不过我们只需调整这几行内容就可以消除这一限制:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncated
请将之前获取的节点 IP 地址替换进去:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncated
接下来就可以开始测试 Karmada 了。
安装 Karmada 代理程序
运行下列命令检索所有部署和所有集群:
bash
$ kubectl get clusters,deployments --kubecnotallow=karmada-config
No resources found
可想而知,目前没有任何部署,也没有任何额外的集群。我们可以添加几个集群并将其连接到 Karmada 控制平面。
请重复执行下列命令三次:
bash
linode-cli lke cluster-create
--label <insert-cluster-name>
--region <insert-region>
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>
执行时请分别使用如下的值:
- Cluster name eu, region eu-west 以及 kubeconfig file kubeconfig-eu
- Cluster name ap, region ap-south 以及 kubeconfig file kubeconfig-ap
- Cluster name us, region us-west 以及 kubeconfig file kubeconfig-us
随后通过下列命令确认集群已经成功创建:
bash
$ kubectl get pods -A --kubecnotallow=kubeconfig-eu
$ kubectl get pods -A --kubecnotallow=kubeconfig-ap
$ kubectl get pods -A --kubecnotallow=kubeconfig-us
接下来要将这些集群加入 Karmada 集群。Karmada 需要在其他每个集群中使用代理程序来协调控制平面的部署。

我们可以使用 Helm 安装 Karmada 代理程序并将其链接至集群管理器:
bash
$ helm install karmada karmada-charts/karmada
--kubecnotallow=kubeconfig-<insert-cluster-name>
--create-namespace --namespace karmada-system
--versinotallow=1.2.0
--set installMode=agent
--set agent.clusterName=<insert-cluster-name>
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority>
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data>
--set agent.kubeconfig.key=<karmada kubeconfig client key data>
--set agent.kubeconfig.server=https://<insert node's IP address>:32443
上述命令同样需要重复三次,每次分别插入下列变量:
- 集群名称:分别为 eu、ap 和 us。
- 集群管理器的证书授权机构。我们可以在 karmada-config 文件的 clusters [0].cluster ['certificate-authority-data'] 中找到该值,这些值可以通过 base64 进行解码。
- 用户的客户端证书数据。我们可以在 karmada-config 文件的 users [0].user ['client-certificate-data'] 中找到该值,这些值可以通过 base64 进行解码。
- 用户的客户端密钥数据。我们可以在 karmada-config 文件的 users [0].user ['client-key-data'] 中找到该值,这些值可以通过 base64 进行解码。
- 承载 Karmada 控制平面的节点的 IP 地址。
随后可以运行下列命令来验证安装是否成功完成:
bash
$ kubectl get clusters --kubecnotallow=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull True
借助 Karmada Policies 编排多集群部署
只要配置正确无误,我们即可将工作负载提交给 Karmada,由它将任务分发给其他集群。
为了进行测试,我们首先需要创建一个部署:
yaml
apiVersion: Apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: hello
随后通过下列命令将该部署提交至 Karmada API 服务器:
bash
$ kubectl apply -f deployment.yaml --kubecnotallow=karmada-config
该部署包含三个副本,那么是否可以平均分发给这三个集群?一起来验证一下:
bash
$ kubectl get deployments --kubecnotallow=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0
Karmada 为何没有创建 Pod?先来看看这个部署:
bash
$ kubectl describe deployment hello --kubecnotallow=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resource
Karmada 并不知道该如何处理这个部署,因为我们尚未指定策略。
Karmada 调度器会使用策略将工作负载分配给集群。那么我们就定义一个简单的策略,为每个集群分配一个副本:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1
并用下列命令将该策略提交给集群:
bash
$ kubectl apply -f policy.yaml --kubecnotallow=karmada-config
然后再来看看部署和 Pod:
bash
$ kubectl get deployments --kubecnotallow=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubecnotallow=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubecnotallow=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubecnotallow=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0

Karmada 会为每个集群分配一个 Pod,因为策略中为每个集群定义了相等的权重。
我们用下列命令将该部署扩展为 10 个副本:
bash
$ kubectl scale deployment/hello --replicas=10 --kubecnotallow=karmada-config
随后查看 Pod 会看到如下的结果:
bash
$ kubectl get deployments --kubecnotallow=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubecnotallow=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubecnotallow=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubecnotallow=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0
随后修改策略,让 EU 和 US 集群各承载 40% 的 Pod,让 AP 集群只承载 20%。
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2
并通过下列命令提交策略:
bash
$ kubectl apply -f policy.yaml --kubecnotallow=karmada-config
接着可以看到,Pod 的分配情况也酌情产生了变化:
bash
$ kubectl get pods --kubecnotallow=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubecnotallow=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubecnotallow=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s

Karmada 支持通过多种策略分配工作负载,更多高级用例可以参考文档。
Pod 在三个集群中运行,但我们该如何访问?
先来看看 Karmada 中的服务:
bash
$ kubectl describe service hello --kubecnotallow=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.
这些服务被部署在全部的三个集群中,但彼此之间并未连接。
尽管 Karmada 可以管理多个集群,但它并未提供任何网络机制将这三个集群连接在一起。换句话说,Karmada 是一种跨越多个集群编排部署的好工具,但我们需要通过其他机制让这些集群相互通信。
使用 Istio 连接多个集群
Istio 通常被用于控制同一个集群中应用程序之间的网络流量,它可以检查所有传入和传出的请求,并通过 Envoy 以代理的方式发送这些请求。

Istio 控制平面负责更新并收集来自这些代理的指标,还可以发出指令借此转移流量。

因此我们可以用 Istio 拦截到特定服务的所有流量,并将其重定向至三个集群之一。这就是所谓的 Istio 多集群配置。
理论知识这就够了,接下来亲自试试吧。首先需要在三个集群中安装 Istio。虽然安装方法很多,但 Helm 最方便:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/charts
我们可以用下列命令将 Istio 安装给三个集群:
bash
$ helm install istio-base istio/base
--kubecnotallow=kubeconfig-<insert-cluster-name>
--create-namespace --namespace istio-system
--versinotallow=1.14.1
请将 cluster-name 分别替换为 ap、eu 和 us,并将该命令同样执行三遍。
Base chart 将只安装通用资源,例如 Roles 和 RoleBindings。实际的安装会被打包到 istiod chart 中。但在执行该操作前,我们首先需要配置 Istio Certificate Authority (CA),以确保这些集群可以相互连接和信任。
请在一个新目录中使用下列命令克隆 Istio 代码库:
bash
$ git clone https://github.com/istio/istio
创建一个 certs 文件夹并进入该目录:
bash
$ mkdir certs
$ cd certs
使用下列命令创建根证书:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-ca
该命令将生成下列文件:
- root-cert.pem:生成的根证书
- root-key.pem:生成的根密钥
- root-ca.conf:供 OpenSSL 生成根证书的配置
- root-cert.csr:为根证书生成的 CSR
对于每个集群,还需要为 Istio Certificate Authority 生成一个中间证书和密钥:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacerts
上述命令会在名为 cluster1、cluster2 和 cluster3 的目录下生成下列文件:
bash
$ kubectl create secret generic cacerts -n istio-system
--kubecnotallow=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem
--from-file=<cluster-folder>/ca-key.pem
--from-file=<cluster-folder>/root-cert.pem
--from-file=<cluster-folder>/cert-chain.pem
我们需要使用下列变量执行这些命令:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |
上述操作完成后,可以安装 istiod 了:
bash
$ helm install istiod istio/istiod
--kubecnotallow=kubeconfig-<insert-cluster-name>
--namespace istio-system
--versinotallow=1.14.1
--set global.meshID=mesh1
--set global.multiCluster.clusterName=<insert-cluster-name>
--set global.network=<insert-network-name>
请使用下列变量将上述命令重复执行三遍:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |
我们还可以使用拓扑注释来标记 Istio 的命名空间:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubecnotallow=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubecnotallow=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubecnotallow=kubeconfig-eu
至此几乎就快完成了。
通过东西网关为流量创建隧道
接下来我们还需要:
- 一个网关,借此通过隧道将流量从一个集群发送到另一个
- 一种机制,借此发现其他集群中的 IP 地址

我们可以使用 Helm 安装网关:
bash
$ helm install eastwest-gateway istio/gateway
--kubecnotallow=kubeconfig-<insert-cluster-name>
--namespace istio-system
--versinotallow=1.14.1
--set labels.istio=eastwestgateway
--set labels.app=istio-eastwestgateway
--set labels.topology.istio.io/network=istio-eastwestgateway
--set labels.topology.istio.io/network=istio-eastwestgateway
--set networkGateway=<insert-network-name>
--set service.ports[0].name=status-port
--set service.ports[0].port=15021
--set service.ports[0].targetPort=15021
--set service.ports[1].name=tls
--set service.ports[1].port=15443
--set service.ports[1].targetPort=15443
--set service.ports[2].name=tls-istiod
--set service.ports[2].port=15012
--set service.ports[2].targetPort=15012
--set service.ports[3].name=tls-webhook
--set service.ports[3].port=15017
--set service.ports[3].targetPort=15017
请使用下列变量将上述命令执行三遍:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |
随后对于每个集群,请使用下列资源暴露一个网关:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"
并使用下列命令将文件提交至集群:
bash
$ kubectl apply -f expose.yaml --kubecnotallow=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubecnotallow=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubecnotallow=kubeconfig-us
对于发现机制,我们需要共享每个集群的凭据。这是因为集群并不知道彼此的存在。
为了发现其他 IP 地址,集群必须能彼此访问,并将这些集群注册为流量的可能目的地。为此我们必须使用其他集群的 kubeconfig 文件创建一个 Kubernetes secret。Istio 可以借此连接其他集群,发现端点,并指示 Envoy 代理转发流量。
我们需要三个 Secret:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>
请使用下列变量创建这三个 Secret:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |
接下来需要向集群提交 Secret,但是请注意,不要将 AP 的 Secret 提交给 AP 集群。
为此需要执行下列命令:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubecnotallow=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubecnotallow=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubecnotallow=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubecnotallow=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubecnotallow=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubecnotallow=kubeconfig-eu
至此,大部分操作已经完成,我们可以开始测试整个配置了。
测试多集群网络连接
首先为一个睡眠中的 Pod 创建一个部署。我们可以使用该 Pod 向刚才创建的 Hello 部署发出请求:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: true
请用下列命令创建部署:
bash
$ kubectl apply -f sleep.yaml --kubecnotallow=karmada-config
因为该部署尚未指定策略,Karmada 将不处理该部署,使其处于 “未决” 状态。我们可以修改策略以包含该部署:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1
使用下列命令应用该策略:
bash
$ kubectl apply -f policy.yaml --kubecnotallow=karmada-config
要了解该 Pod 被部署到哪里,可以使用下列命令:
bash
$ kubectl get pods --kubecnotallow=kubeconfig-eu
$ kubectl get pods --kubecnotallow=kubeconfig-ap
$ kubectl get pods --kubecnotallow=kubeconfig-us
接下来,假设该 Pod 被部署到 US 集群,请执行下列命令:
bash
for i in {1..10}
do
kubectl exec --kubecnotallow=kubeconfig-us -c sleep
"$(kubectl get pod --kubecnotallow=kubeconfig-us -l
app=sleep -o jsnotallow='{.items[0].metadata.name}')"
-- curl -sS hello:5000 | grep REGION
done
我们将会发现,响应会来自不同地域的不同 Pod!搞定!
总结
该配置其实非常基础,缺乏真实环境中可能需要的其他很多功能:
- 我们可以从每个集群暴露出一个 Istio 入口以摄入流量
- 我们可以使用 Istio 进行流量塑型,这样就会优先进行本地处理
- 还可以使用 Istio 策略强制规则定义流量如何在不同集群之间流动