一文带您快速入门Kafka
作者 | 蔡柱梁
审校 | 重楼
Kafka 在我们工作中最常扮演的三个角色:
上图(图出自于《深入理解Kafka核心设计与实践原理》)体现了 Kafka 的整体架构,Producer 发送消息,Kafka 将元数据存储在 ZK 中并交由ZK 管理,Consumer 通过拉模式获取消息。
上面的概念都是物理层面上的,但是在实际使用过程中还有很多逻辑方面的定义,这些概念也是需要了解的。如果不了解,就算勉强写出了代码,但是自己还是一脸懵不知道自己都定义了什么,它们都有什么意义,估计离生产故障就不远了。
接下来我们再去了解三个重要的逻辑概念:
为了更好,更直观体现上面三者的关系,我们先一起看下图(图出自于《深入理解Kafka核心设计与实践原理》)

该图展示了一个拥有4个 Partition 的 Topic,而分区里面的阿拉伯数字就是 Offset(也表示着一条消息),虚线部分代表新消息可以插入的位置。每条消息在发送到 Broker 之前,会先计算当前消息应该发送到哪个 Partition。因此,只要我们设置合理,消息可以均匀地分配在不同的 Partition 上,当发现请求数量激增时,我们也可以考虑通过适当增加 Partition(Broker 也要增加)的方式,从而降低每个 Broker 的 I/O 压力。
另外,为了降低消息丢失的风险,Kafka 为 Partition 引进了多副本(Replica)机制,通过增加副本数量来提高容灾能力。副本之间采用的是“一主多从”的设计,其中 Leader 负责读写请求,Follower 则仅负责同步 Leader 的消息(这种设计方式,大家应该要意识到会存在同步滞后的问题),并且副本处于不同的 Broker 中,当 Leader 出现故障(一般是因为其所在的 Broker 出现故障导致的)时,就从 Follower 中重新选举出新的 Leader 提供服务。当选出新的 Leader 并恢复服务后,Consumer 可以通过之前自己保存的 Offset 来继续拉取消息消费。
结合到目前为止我们所知道的知识点,一起看下 4 个 Broker 的 Kafka 集群中,某一个 Topic 有三个 Partition,其副本因子为 3(副本因子为3就是每个 Partition 有 3 个副本,一个 Leader,两个 Follower)的架构图(图出自于《深入理解Kafka核心设计与实践原理》)。

上面有提到 Kafka 的多副本机制是 Leader 提供读写,而 Flower 是需要同步 Leader 的数据的,那么具体是怎样的呢?请看下图(单主题单分区3副本):

当Producer 不断往 Leader 写入消息时,Flower 会不断去 Leader 拉取消息,但是每台机器的性能会有出入,所以同步也有差异,正如上图这般。对于 Consumer 而言,只有 HW 之前的消息是可见可拉取消费的,这样做有个好处就是当发生故障转移时,Consumer 的 Offset 也不会发生数组越界的问题。这种做法是 Kafka 权衡利弊后给出的数据可靠性与性能平衡的方案,即不采取同步复制(性能差,对于高并发场景是灾难般的设计),也不采取异步复制(完全异步,数据丢失问题突出)。
当然,对于Producer 而言就是消息丢失了,有时我们需要确保消息百分百投递,这样不就有问题了吗?不急,Kafka 可以在 Producer 的配置上配置 acks=-1 + min.insync.replicas=n(n 大于 1),这样配置后,只有消息被写入所有副本后,Kafka 服务端才会返回 ack 给 Producer。
下面来梳理下上面提及的几个概念:
1.首先检查自己的linux 是否安装好了 yum 工具

使用 yum 安装好 wget
2.下载 ZK
wget https://archive.Apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz


3.解压
4.为ZK 创建存放数据和日志的文件夹

5.修改ZK 配置文件

vi zoo.cfg
修改配置内容具体如下:
接着,到 /root/zookeeper-3.4.6/data 创建文件 myid(如果部署的是集群,那么这个 myid 必需唯一,不能重复)。
具体如下:

6.配置环境变量

再执行 source /etc/profile
至此,ZooKeeper 已经配置好了,我们可以启动看下是否有问题。

2.使用 psftp 上传到服务器


3.解压
4.修改配置
由于 server.properties 比较大,就不全部贴上来了,只贴我修改的部分:
5.修改环境变量
再执行 source /etc/profile
6.进入bin目录,启动 Broker
ps -ef|grep kafka 看下进程,但是是否已经可以使用,要通过发送消息和消费消息来验证。

pom.xml
Application.yml
application-dev.yml
logback.xml
ProducerDemo
ConsumerDemo
TestController
postman请求测试如下:

控制台信息如下:

审校 | 重楼
目标
- 了解 Kafka 的重要概念
- 搭建 Kafka 服务端
- 使用SpringBoot 实现简单的 Demo
1 了解 Kafka 的重要概念
Kafka 是使用 Scala 语言开发的一个多分区、多副本且基于 ZooKeeper 协调的分布式消息系统。目前,它的定位是一个分布式流式处理平台。Kafka 在我们工作中最常扮演的三个角色:
- 消息系统
- 存储系统
- 流式处理平台
1.1 基本概念
上图(图出自于《深入理解Kafka核心设计与实践原理》)体现了 Kafka 的整体架构,Producer 发送消息,Kafka 将元数据存储在 ZK 中并交由ZK 管理,Consumer 通过拉模式获取消息。
- Producer
- Broker
- Consumer
上面的概念都是物理层面上的,但是在实际使用过程中还有很多逻辑方面的定义,这些概念也是需要了解的。如果不了解,就算勉强写出了代码,但是自己还是一脸懵不知道自己都定义了什么,它们都有什么意义,估计离生产故障就不远了。
接下来我们再去了解三个重要的逻辑概念:
- Topic(主题)
- Partition(分区)
- Offset(偏移量)
为了更好,更直观体现上面三者的关系,我们先一起看下图(图出自于《深入理解Kafka核心设计与实践原理》)
该图展示了一个拥有4个 Partition 的 Topic,而分区里面的阿拉伯数字就是 Offset(也表示着一条消息),虚线部分代表新消息可以插入的位置。每条消息在发送到 Broker 之前,会先计算当前消息应该发送到哪个 Partition。因此,只要我们设置合理,消息可以均匀地分配在不同的 Partition 上,当发现请求数量激增时,我们也可以考虑通过适当增加 Partition(Broker 也要增加)的方式,从而降低每个 Broker 的 I/O 压力。
另外,为了降低消息丢失的风险,Kafka 为 Partition 引进了多副本(Replica)机制,通过增加副本数量来提高容灾能力。副本之间采用的是“一主多从”的设计,其中 Leader 负责读写请求,Follower 则仅负责同步 Leader 的消息(这种设计方式,大家应该要意识到会存在同步滞后的问题),并且副本处于不同的 Broker 中,当 Leader 出现故障(一般是因为其所在的 Broker 出现故障导致的)时,就从 Follower 中重新选举出新的 Leader 提供服务。当选出新的 Leader 并恢复服务后,Consumer 可以通过之前自己保存的 Offset 来继续拉取消息消费。
结合到目前为止我们所知道的知识点,一起看下 4 个 Broker 的 Kafka 集群中,某一个 Topic 有三个 Partition,其副本因子为 3(副本因子为3就是每个 Partition 有 3 个副本,一个 Leader,两个 Follower)的架构图(图出自于《深入理解Kafka核心设计与实践原理》)。
1.2 Message 与 Partition
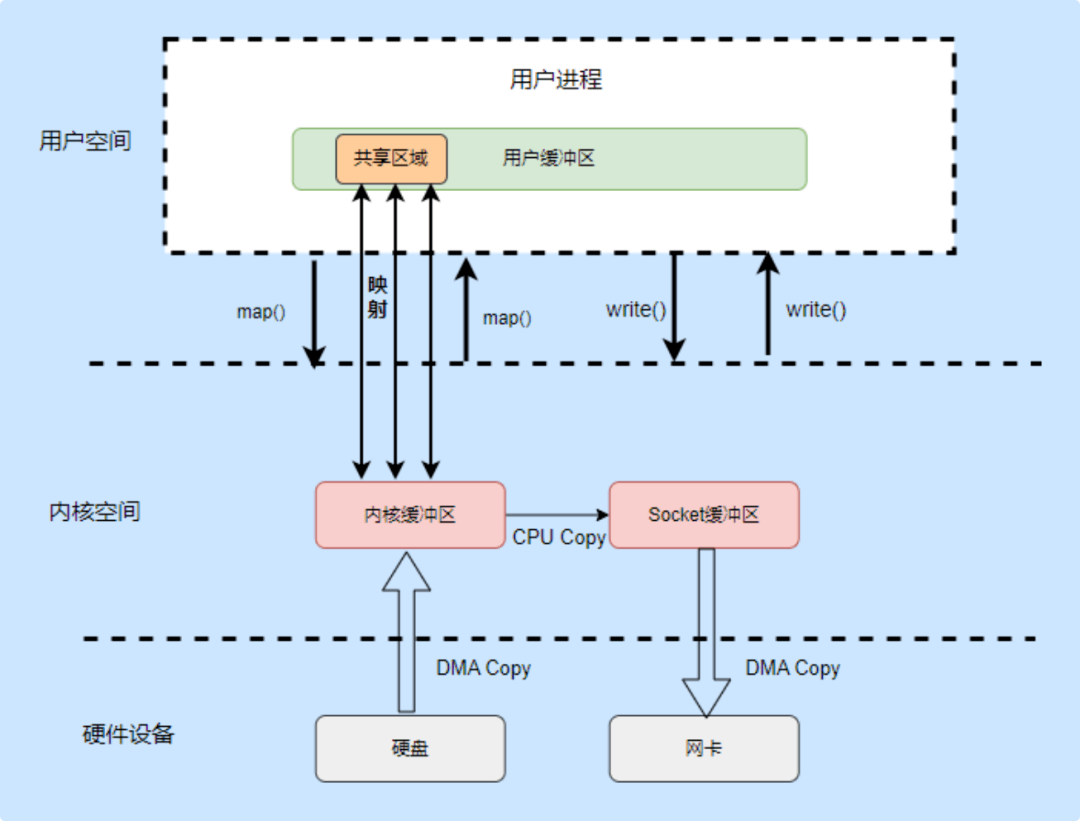
在 1.1 小节中,我们已经知道一条消息只会存在一个 Partition中(只管 Leader,不管 Follower),而 Offset 则是消息在 Partition 中的唯一标识。而在本章节,我们将一起更深入地了解消息与 Partition 的关系,还有副本间同步数据所衍生的一些概念。上面有提到 Kafka 的多副本机制是 Leader 提供读写,而 Flower 是需要同步 Leader 的数据的,那么具体是怎样的呢?请看下图(单主题单分区3副本):
当Producer 不断往 Leader 写入消息时,Flower 会不断去 Leader 拉取消息,但是每台机器的性能会有出入,所以同步也有差异,正如上图这般。对于 Consumer 而言,只有 HW 之前的消息是可见可拉取消费的,这样做有个好处就是当发生故障转移时,Consumer 的 Offset 也不会发生数组越界的问题。这种做法是 Kafka 权衡利弊后给出的数据可靠性与性能平衡的方案,即不采取同步复制(性能差,对于高并发场景是灾难般的设计),也不采取异步复制(完全异步,数据丢失问题突出)。
当然,对于Producer 而言就是消息丢失了,有时我们需要确保消息百分百投递,这样不就有问题了吗?不急,Kafka 可以在 Producer 的配置上配置 acks=-1 + min.insync.replicas=n(n 大于 1),这样配置后,只有消息被写入所有副本后,Kafka 服务端才会返回 ack 给 Producer。
下面来梳理下上面提及的几个概念:
- HW(Heigh Watermark)
- LEO(Log End Offset)
- AR(Assigned Rplicas)
- ISR(In-Syns Rplicas)
- OSR(Out-of-Sync Rplicas)
2 搭建 Kafka 服务端
这里仅以单节点为例,不配置集群。2.1 安装 ZooKeeper
在第一章节,我们知道 Kafka 会将元数据交由 ZK 管理,所以我们要先安装好 ZK。1.首先检查自己的linux 是否安装好了 yum 工具
rpm -qa|grep yum
使用 yum 安装好 wget
2.下载 ZK
wget https://archive.Apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
3.解压
tar -zxvf zookeeper-3.4.6.tar.gz
mkdir data
mkdir logs
5.修改ZK 配置文件
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改配置内容具体如下:
# ZooKeeper 服务器心跳时间,单位:毫秒
tickTime=2000
# 投票选举新 Leader 的初始化时间
initLimit=10
# Leader 与 Flower 心跳检测最大容忍时间,响应超过 syncLimit*tickTime,就剔除 Flower
syncLimit=5
# 存放数据的文件夹
dataDir=/root/zookeeper-3.4.6/data
# 存放日志的文件夹
dataLogDir=/root/zookeeper-3.4.6/logs
# ZooKeeper提供给接入客户端的连接端口
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the mAIntenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
cat > myid
vi myid
6.配置环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/root/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin再执行 source /etc/profile
至此,ZooKeeper 已经配置好了,我们可以启动看下是否有问题。
2.2 安装 Kafka
1.到官网下载安装包2.使用 psftp 上传到服务器
# put dir remoteDir
put D:downloadskafka_2.13-3.5.0.tgz /root/kafka_2.13-3.5.0.tgz
3.解压
tar -zxvf kafka_2.13-3.5.0.tgz
cd kafka_2.13-3.5.0cd config/
# 是Broker的标识,因此在集群中必需唯一
broker.id=0
# Broker 对外服务地址(我这里vmware的ip是192.168.226.140)
listeners=PLAINTEXT://192.168.226.140:9092
# 实际工作中,会分内网外网,当有需要提供给外部客户端使用时,我们一般 listeners 配置内网供 Broker 之间通信使用,而 advertised.listeners 配置走外网给接入的客户端使用
#advertised.listeners=PLAINTEXT://your.host.name:9092
# 存放消息日志文件地址
log.dirs=/root/kafka_2.13-3.5.0/logs
# ZK 的访问路径,我这里因为 ZK 和 Kafka 放在了同一个服务器上,所以就使用了 localhost
zookeeper.connect=localhost:2181
vi /etc/profile
export KAFKA_HOME=/root/kafka_2.13-3.5.0
export PATH=$PATH:$KAFKA_HOME/bin6.进入bin目录,启动 Broker
kafka-server-start.sh ../config/server.properties &
3 使用 Spring Boot 实现简单的 Demo
下面是示例代码:pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<!-- spring boot3.0+ 只支持jdk17,如果使用1.8出现包冲突需要自己处理 -->
<version>2.7.12</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example.czl</groupId>
<artifactId>kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-kafka</name>
<description>spring boot集成kafka demo</description>
<properties>
<JAVA.version>1.8</java.version>
<MyBatis-plus.version>3.5.3.1</mybatis-plus.version>
<velocity-engine-core.version>2.3</velocity-engine-core.version>
<lombok.version>1.18.26</lombok.version>
<guava.version>31.1-jre</guava.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.MySQL</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<artifactId>scala-library</artifactId>
<groupId>org.scala-lang</groupId>
</exclusion>
<exclusion>
<artifactId>scala-reflect</artifactId>
<groupId>org.scala-lang</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>${velocity-engine-core.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
</dependencies>
<!-- 对于一些特殊的依赖指定特定版本 -->
<!--<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>2.0</version>
</dependency>
</dependencies>
</dependencyManagement>-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>Application.yml
spring:
application:
name: spring-boot-kafka
profiles:
active: dev
server:
port: 8080
spring:
datasource:
url: "jdbc:mysql://***:***/***?useSSL=false&useUnicode=true&characterEncoding=utf8&ApplicationName=spring-boot-demo&serverTimezone=UTC&allowMultiQueries=true"
username: "***"
password: "***"
kafka:
bootstrap-servers: "192.168.226.140:9092" # 访问Kafka服务端的地址
consumer:
group-id: ${spring.application.name}-${spring.profiles.active} # 一条消息只会被订阅了该主题的同一个分组内的一个消费者消费
mybatis-plus:
configuration:
# 打印sql
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_PATH_HOME" value="./logs/spring-boot-kafka"/>
<property name="LOG_LEVEL" value="INFO"/>
<!-- 日志文件布局 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}(%L) - [%X{traceId}] %msg%n</pattern>
</encoder>
<!-- 按时间大小归档日志 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<FileNamePattern>${LOG_PATH_HOME}/log.%d{yyyy-MM-dd}.%i.log</FileNamePattern>
<maxFileSize>200MB</maxFileSize>
</rollingPolicy>
</appender>
<!-- 控制台日志布局 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}(%L) - [%X{traceId}] %msg%n</Pattern>
</encoder>
</appender>
<logger name="org.springframework.web.filter.CommonsRequestLoggingFilter" level="INFO"/>
<logger name="org.springframework" level="INFO"/>
<logger name="com.czl.demo" level="${LOG_LEVEL}"/>
<root level="${LOG_LEVEL}">
<appender-ref ref="FILE"/>
<appender-ref ref="STDOUT"/>
</root>
</configuration>
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* @author CaiZhuliang
* @date 2023/6/18
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class ProducerDemo {
private final KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息
* @param topic 主题
* @param msg 消息
* @param callback 钩子
*/
public void send(String topic, String msg, ListenableFutureCallback<SendResult<String, String>> callback) {
log.info("发送Kafka消息 - topic : {}, msg : {}", topic, msg);
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, msg);
if (null != callback) {
future.addCallback(callback);
}
}
}
package com.example.czl.kafka.kafka.producer.consumer;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @author CaiZhuliang
* @date 2023/6/18
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class ConsumerDemo {
@KafkaListener(topics = "test-topic-1")
public void receivingMsg(String msg) {
log.info("接收到Kafka消息 - msg : {}", msg);
}
}
package com.example.czl.kafka.controller;
import com.example.czl.kafka.kafka.producer.ProducerDemo;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CaiZhuliang
* @date 2023/6/18
*/
@Slf4j
@RestController
@RequiredArgsConstructor
@RequestMapping("/test")
public class TestController {
private final ProducerDemo producerDemo;
@GetMapping("/send/kafka_msg")
public Long sendMsg(String msg) {
log.info("测试发送kafka消息 - msg : {}", msg);
producerDemo.send("test-topic-1", msg, null);
return System.currentTimeMillis();
}
}
控制台信息如下: