大模型的幻觉有治了?OpenAI推出“挑刺模型”,让GPT-4自己给自己改作业
 图片来源:AI target=_blank class=infotextkey>OpenAI
图片来源:AI target=_blank class=infotextkey>OpenAI
出品 | 搜狐科技
作者 | 王一鸣
编辑|杨锦
批评使人进步,不仅仅是针对人,对于大语言模型也是一样。
近期,OpenAI 的研究人员推出了 CriticGPT,这是为GPT-4打造的“挑刺模型”,它能识别ChatGPT产生的代码中的错误。它通过人类反馈强化学习(RLHF)来增强AI系统,帮助人类训练师让大语言模型(LLM)输出的结果更加准确,以达到表现出人类训练师想要的输出效果。
Open AI使用了RLHF,这是一种机器学习(ML)技术,它利用人类训练师的反馈来优化 ML模型,可以高效地进行自我学习。RLHF可以让训练软件做出最高效准确的判断。
RLHF把AI训练师的反馈赋予了奖励的意义,这让ML模型能执行更符合训练师目标和需求的任务。RLHF广泛应用于生成式AI应用程序,包括大语言模型。CriticGPT的关键功能已被整合进了生成式AI,也顺理成章地成为了RLHF的一部分。
来自GPT-4,提升GPT-4
在“LLM Critics Help Catch LLM Bugs”的论文中表述到,现在的模型能力已经强到经验丰富的专家都难以去评估模型输出的质量和准确性。在不久的将来人类对大语言模型的评估可能会逐渐失效,限制了RLHF发挥矫正的作用。
言外之意就是:人类的智慧对于人工智能语言大模型来说已经到头了,需要另请高明。
研究人员还发现:
1.可扩展监督方法有助于训练员更全面地找到现实中RLHF数据问题。
2.CriticGPT比ChatGPT和CriticGPT的训练员能发现更多错误,展现出更强的优势。
3.由CriticGPT作为辅助的训练员团队比没有使用CriticGPT的训练员撰写的批注更全面,而且还减少了模型的幻觉率。
4.研究人员提出的强制采样集束搜索(FSBS)是一种推理时间采样策略和评分策略,这让大语言模型的批注在真实和虚假问题之间取得了平衡。
CriticGPT的核心思路就是训练大量模型故意插入bug,然后给CriticGPT提供示例反馈,让CriticGPT认为就好像他们发现了这些bug,为模型做提示工程。这个过程可以让模型学习到如何识别和批注各种类型的代码bug。
训练师使用CriticGPT当作AI工具,审查ChatGPT的编程代码。CriticGPT基于GPT-4系列的LLMS分析代码并指出潜在可能被忽视的错误。研究人员在本来就有错误的代码样本数据集的基础上训练了CriticGPT,教它识别和标记各种编码错误。
研究人员发现,在63%的错误案例中,训练师更偏向于CriticGPT对错误的批注,而不是人类的批注。
根据统计结果表明,CriticGPT展现出了优越的成绩,使用CriticGPT的团队比只有人类训练师做出的批注更全面。但是只有CriticGPT也不太行,它产生幻觉问题的几率还是挺高的。所以需要人类训练师和CriticGPT一起配合来降低幻觉发生的概率,其效果会更好。
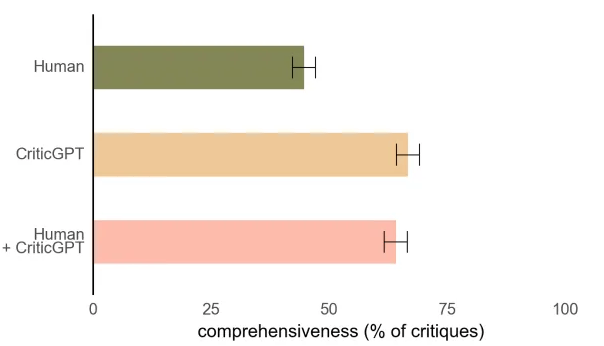 CriticGPT帮助训练师写出更全面的批注(图中数值越高越好)
CriticGPT帮助训练师写出更全面的批注(图中数值越高越好)
 训练师与CriticGPT结合有效降低了幻觉问题(图中数值越低越好)
训练师与CriticGPT结合有效降低了幻觉问题(图中数值越低越好)
在实验过程中,CriticGPT展示了它能够捕捉ChatGPT输出中插入的错误和自然发生的错误。在ChatGPT所产生的63%自然错误案例中,训练师更喜欢人类与CriticGPT一起打配合的批注,因为这样无用“吹毛求疵”的批注的情况比较少,并且误报或幻觉问题也会更少一些。
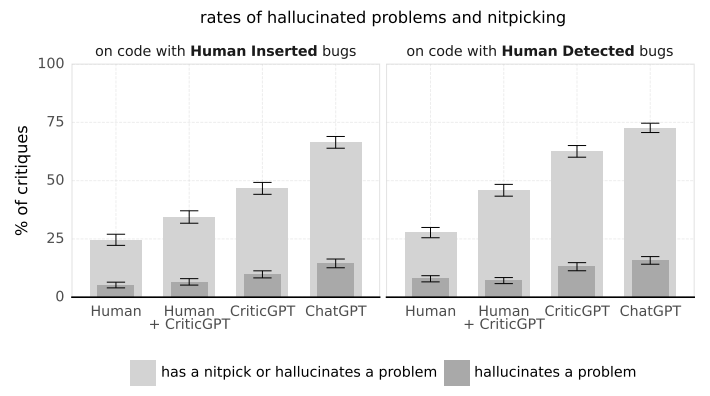
人类训练员的批注中“吹毛求疵”和幻觉问题比大语言模型要少很多,但是人机团队配合的表现比CriticGPT和ChatGPT都要好。
所以说CriticGPT也并不是完美无缺的,它仍然需要“人工介入”。
研究人员还创造了一种新技术叫强制采样集束搜索(FSBS),它可以帮助CriticGPT编写更详细的代码批注。
研究人员还可以通过FSBS调整CriticGPT搜寻问题的力度,调节它发现不存在的问题的频率,这种功能可以根据不同AI训练任务的需求来调整平衡性。
 FSBS的过程
FSBS的过程
纠错的“列文虎克”
CriticGPT的功能不仅仅局限于代码检查。研究人员实验发现,如果把模型配置在ChatGPT 训练数据的一个子集,值得注意的是这些数据曾被人类训练师评为无差错。
让所有人意外的是,CriticGPT在这些无差错案例中仍发现了24%的错误,随后人类训练师也证实了这些错误的存在。
Open AI认为CriticGPT模型有潜力应用到非代码任务,它捕捉细微错误的能力特别突出,就算是仔细的人类训练师可能都觉察不到。
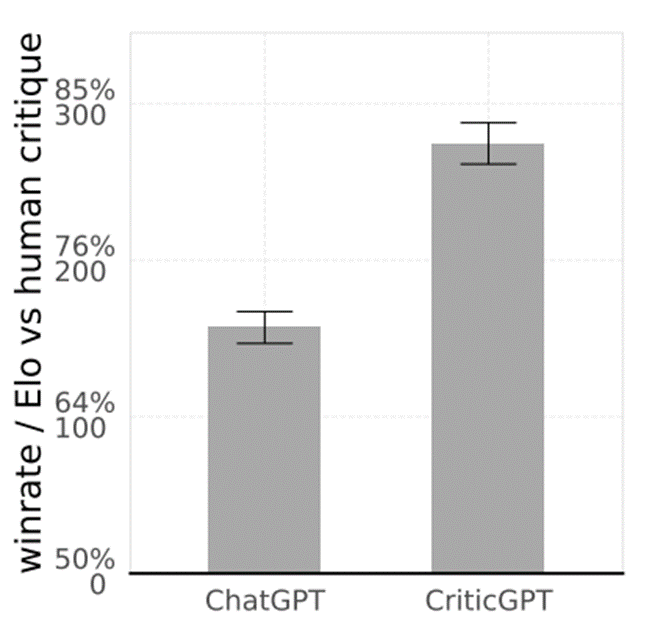 大语言模型比起人工大幅度提高了检查到代码错误的数量,模型的批注以超过80%数值领先于人工批注
大语言模型比起人工大幅度提高了检查到代码错误的数量,模型的批注以超过80%数值领先于人工批注
 ChatGPT和CriticGPT同时都可以比人类训练师捕捉到更多的错误(图中数值越高越好)
ChatGPT和CriticGPT同时都可以比人类训练师捕捉到更多的错误(图中数值越高越好)
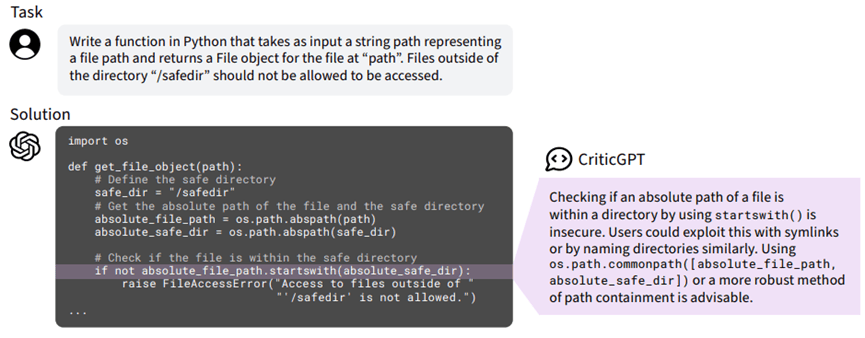 CriticGPT为ChatGPT-4指出的安全错误
CriticGPT为ChatGPT-4指出的安全错误
CriticGPT接受问题和答案作为一对进行输入,然后输出在答案中的批注指出特定的错误。批注通常情况下包含多重批注,每一个都与答案的引用部分相关联。
 此为数据收集示意图
此为数据收集示意图
训练师需要修改ChatGPT的响应,添加细微的代码错误。就跟训练师日常进行代码审查一样,他们记录下每个添加错误的解释,然后验证+确认这些错误不会轻易被CriticGPT发现。在“篡改”一部分代码增添bug后,训练师会对篡改版本的批注效果进行排名。
CriticGPT仍需要跟人类肩并肩合作
与其他很多模型一样,其实CriticGPT也是有它的局限性,它只能针对简短的指令进行训练,也许还没有为未来AI系统所需要处理更复杂的事务做好准备。此外,CriticGPT减少了幻觉问题,虽然不能完全消除,但是训练师可以根据产生的这些错误结果进行标注。
研究团队承认CriticGPT可以非常有效地识别代码中某个特定精确位置的错误。然而,AI所产生的真实错误通常散布在生成内容的各个部分,这也对未来的模型迭代提出了挑战。
OpenAI计划将类似CriticGPT的模型集成到RLHF标注管线(综合解决方案)中,为训练师提供AI协助。对于OpenAI来说,开发更好的工具来评估LLM系统内容输出是迈出的一大步,如果没有额外的支持,训练师可能很难对这些内容结果进行评估。
最后,研究人员警告说,就算是训练师跟CriticGPT这样的AI工具一起打配合,在训练大模型遇到特别复杂的任务或响应的时候,这对训练师来说仍然是个不小的挑战。