AI“黑箱”被打开?谷歌找到大模型能力涌现机制

新智元报道
编辑:桃子
【新智元导读】大模型涌现能力如何理解?谷歌的最新论文研究了语言模型中的上下文学习,是如何受到语义先验和输入-标签映射影响。
前段时间,AI target=_blank class=infotextkey>OpenAI整出了神操作,竟让GPT-4去解释GPT-2的行为。
对于大型语言模型展现出的涌现能力,其具体的运作方式,就像一个黑箱,无人知晓。
众所周知,语言模型近来取得巨大的进步,部分原因是它们可以通过上下文学习(ICL)来执行任务。
上下文学习是一种过程,模型在对未见过的评估样本执行任务之前,会先接收几个输入-标签对的范例。
在谷歌最新发表的论文中,研究人员研究了语义先验,以及输入-标签映射在ICL中如何相互作用。

论文地址:https://arxiv.org/pdf/2303.03846.pdf
特别是,语言模型在上下文学习能力,如何随着参数规模而改变。
论文一作Jerry Wei表示,大型语言模型(GPT-3.5、PaLM)可以遵循上下文中的范例,即使标签被翻转或在语义上不相关。这种能力在小型语言模型中是不存在的。

网友表示,这对模型新的涌现能力很有见解。
AI「黑箱」怎么破?
一般来说,模型能够在上下文中学习,有以下2个因素:
一种是使用预先训练的语义先验知识来预测标签,同时遵循上下文范例的格式。
比如,见到以「积极情绪」和「消极情绪」作为标签的影评例子,并用先验知识进行情感分析。
另一种是从提供的范例中,学习ICL中的输入-标签映射。比如,找到正面评价映射到一个标签,而负面评价映射到另一个标签的模式。
最新研究的目标就是为了了解这两个因素在上下文中如何作用。
因此,在论文中,研究者调查了两个设置来进行研究:翻转标签ICL,语义无关标签的ICL (SUL-ICL)。
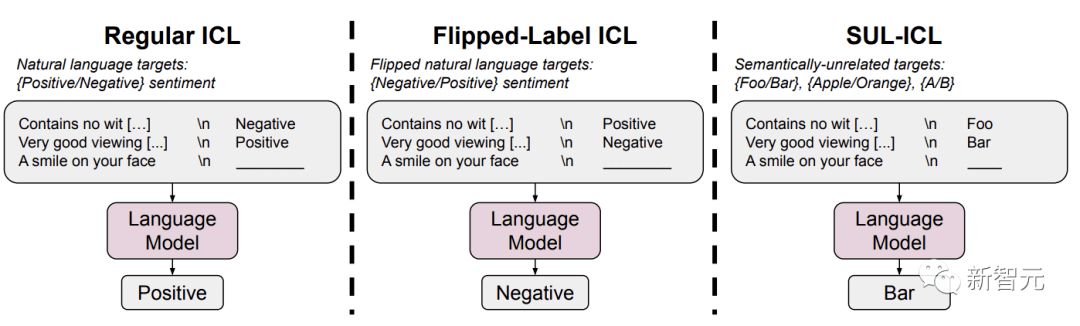
翻转标签ICL和语义无关标签ICL(SUL-ICL)在情感分析任务中的概述
在翻转标签ICL中,上下文范例的标签被翻转,强制模型覆盖语义先验,以遵循上下文范例。
在SUL-ICL中,使用与任务无语义关系的标签,意味着模型必须学习输入标签映射才能执行任务,因为它们不再依赖于自然语言标签的语义。
研究者发现,覆盖先验知识是模型规模能力,就像在上下文中学习与语义无关的标签的能力一样。
此外,指令调优加强了先验知识的使用,而不是增加了学习输入-标签映射的能力。
实验过程
此外,研究人员还对五种语言模型进行了测试:PalM、Flan-PalM、GPT-3、DirectGPT和Codex。
翻转标签
在这个实验中,上下文示例的标签被翻转,这意味着先验知识和输入-标签映射不一致。比如,包含积极情绪的句子被标记为「消极情绪」,从而研究模型是否可以覆盖其先验知识。
在此设置中,能够覆盖先验知识,并在上下文中学习输入-标签映射的模型性能会下降,因为真实评估标签没有被翻转。
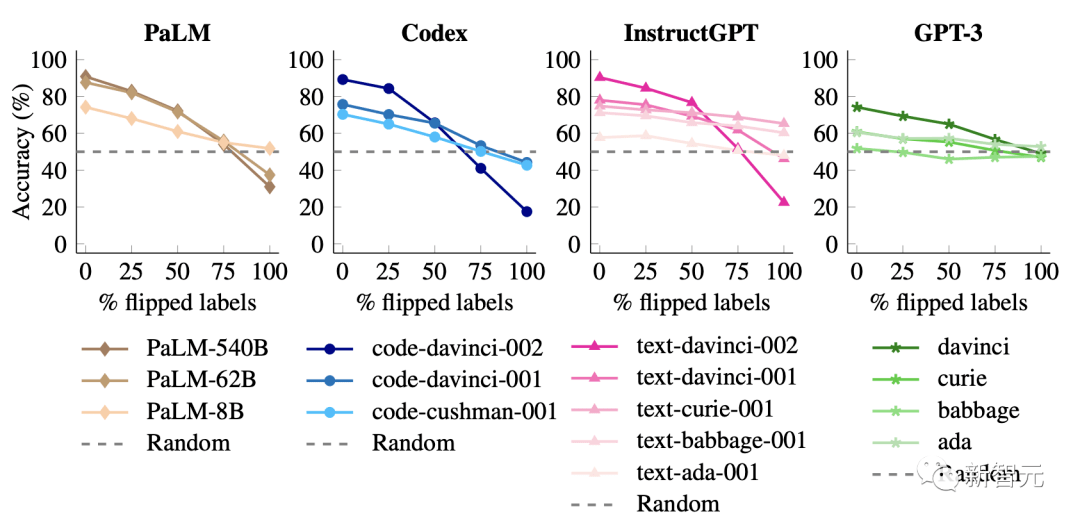
研究者还发现当没有标签被翻转时,参数规模较大的模型比较小的模型,拥更好的性能。
但是,当翻转越来越多的标签,小型模型的性能保持相对平稳,但大型模型的性能大幅下降,远低于随机猜测。
比如,code-davinci-002的性能从90%下降到22.5%。
这些结果表明,当输入标签映射相互矛盾时,大模型可以覆盖预训练的先验知识。
小型模型无法做到这一点,这使得这种能力成为模型规模的涌现现象。
语义无关的标签
在这个实验中,研究人员用语义无关的标签替换原来标签。
比如,在情感分析中,用「foo/bar」代替「消极/积极」 ,这意味着模型只能通过学习输入-标签映射来执行 ICL。
如果一个模型主要依赖于ICL的先验知识,那么在这种替换之后,它的性能应该会下降,因为它将不再能够使用标签的语义意义来进行预测。
另一方面,可以在上下文中学习输入-标签映射的模型,将能够学习这些语义不相关的映射,其性能不会出现大幅的下降。
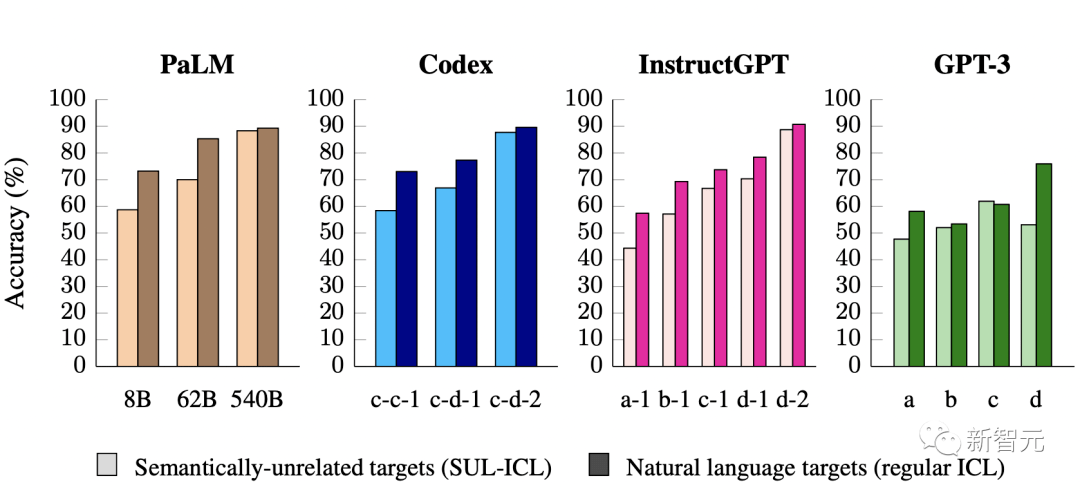
事实上,使用语义无关的标签会导致小型模型的性能大幅下降。
这表明较小的模型主要依赖于它们在上下文中的语义先验,而不是从提供的输入标签映射中学习。
另一方面,当标签的语义特性被移除时,大型模型具有在上下文中学习输入标签映射的能力。
此外,研究人员还发现,包含更多的上下文范例对大型模型的性能改善,比对小型模型的性能改善更大。
显然,大型模型比小型模型更善于从上下文范例中学习。
指令调优模型如何?
当前,指令调优是提高模型性能比较流行的一种方法。
这两者都将导致标准上下文任务性能的提高。
研究人员继续通过与前面相同的两个设置来研究这个问题,只是这一次将重点放在比较标准语言模型(特别是 PaLM)和它们的指令调优变体(Flan-PaLM)上。
首先,当使用语义不相关的标签时,Flan-PalM比PalM性能更好。
这种效应在小型模型中非常显著,因为Flan-PalM-8B的性能比PaLM-8B高9.6% ,几乎赶上了PaLM-62B。
这种趋势表明,指令调优加强了学习输入标签映射的能力,但这并不是令人惊讶的发现。
更有趣的是,研究者还发现Flan-PalM在遵循翻转标签上比PalM更差,这意味着指令调优模型无法覆盖它们的先验知识。
在100%翻转标签的情况下,Flan-PaLM模型无法做到随机猜测,但是在相同的设置下,没有进行指令调优的PaLM模型可以达到31%的准确率
这些结果表明,指令调优必须增加模型在语义先验可用时的依赖程度。
结合前面的研究结果,研究者得出结论:虽然指令调优提高了学习输入-标签映射的能力,但它更强化了语义先验知识的使用。
谷歌这篇论文强调了语言模型的ICL行为如何根据其参数而改变,并且更大的语言模型具有将输入映射到许多类型的标签的涌现能力。
这是一种推理形式,其中输入-标签映射可以潜在地学习任意符号。
未来,更进一步的研究可以帮助人们去了解为什么这些现象会与模型参数相关。
参考资料:
https://ai.googleblog.com/2023/05/larger-language-models-do-in-context.html