手把手教你用 AI 取代淘宝模特
“ 这是不是第一个被 AI 颠覆的职业?”我在小红书上看到这么一个热搜,点开发现, 人们说的是淘宝模特。
大概内容是说如果淘宝店主完全用 AI 穿拍,可以不用在模特、化妆师、摄影师身上反复掏钱了,而且 AI 是 24/7 在岗,出图更是以秒为单位,成本低廉,打几行 prompt(提示词),把衣服图样导入,再调整、挑选就可以了。
著名牛仔装品牌李维斯(Levi's)就曾宣布今年开始测试用 AI 模特来展示服装。因为相比真人,品牌可以任意选择模特的年龄、肤色、体态。
对淘宝模特来说,现在除了要和同行竞争,还要和 AI 竞争。
有意思的是,消费者对 AI 模特并不满意,因为 “没人味”,也 “展现不了真实的衣服质感”,因为衣服也“数字化”了,“是假的”。
但对于视觉工作者来说,AI 工具这般涌现让我无比兴奋,我开始研究如何做出 AI 模特,让他们穿上我指定的服装……
结果, 单个人形的效果让我很满意,于是我萌生了一个想法:干脆就做一个全员 AI 的虚拟时尚杂志。

我在小红书上运营这本杂志 @AI Bubbles泡泡丨作者提供
初试:Midjourney V5 是能出片,但无法精确还原衣服
自 Midjourney 在三月底更新到了第五代后,这个 AI 画画工具又在全球的社交网络上掀起一股狂潮——人们热烈地分享自己的“摄像级”画作,以及对应的提示词,以下就是我用 Midjourney V5 生成的:



Midjourney 有“垫图”功能,也就是上传图片让 AI 参考用户指定的场景、色彩、布局、物件等等。

那么,如果我 把衣服照片当作底图发给 Midjourney,再用文本指令让 AI 帮我生成一个人,是不是就能让模特穿上我指定的衣服了?
一分钟后,我得到了答案:能,但不完全能。

Prompt: A young girl in a rainbow tank top, knitted and crocheted, wearing yellow sun glasses, ink-washed ship tattoo, hazy, dreamlike quality.
(一个身穿彩虹背心的年轻女孩,针织和钩编,戴着黄色太阳眼镜,有墨水脱色感的船舶纹身,朦胧,有梦境般的质感。)
虽然图片非常惊艳,但并不能 1:1 还原衣服的细节。 你看,袖套就不见了!(AI 工具的进化,简直是以日为单位的,没准 V6、V7 就能解决这个问题了。)
再试:自己训练一个专属模型?让它记得住我喂的衣服单品
现有的画画 AI 并不能满足我的“刁钻”需求,有没有可能自己整一个呢?我想到了“炼丹”。
炼丹就是人将大量灵材置入丹炉,最终凝炼成丹。到了 AI 绘画界, 炼丹就是给 Stable Diffusion 这样的大模型,专门投喂一个指定方向(比如二次元)的数据集,训练出对应垂类的小模型,让 AI 可以根据需求精准出图。
丹要咋炼?有一种训练方法叫 LoRA,你按照自己的喜好微调 Stable Diffusion 大模型,然后就能导出体积更小的模型,保存、传播都更方便了。
比如,我的一个朋友就通过投喂了 200 余张明清两代水墨大师的画作,做出了国风墨心模型:

通过 LoRA 的脚本训练,不光可以训练风格模型,还可以训练人物角色模型。在 CivitAI 上,就有人做了“瑞秋”Jennifer Aniston 的模型:

能记住风格和人物,那记一件衣服应该不难吧?我跑了一遍流程后,发现……还真的行。我先发出一些实验成果:


接下来,我将手把手教大家训练出一个服装模型。 你千万别刚滑几屏就被劝退了,一步步跟着做,其实非常简单。
注:本教程只适用于 windows 电脑
保姆级教程:如何训练一个服装模型
准备:看看自己的显卡,安装必备软件
选显卡的时候,主要看算力和显存。其中,显存的重要性主要体现在以下两个方面:
- 训练模型时有更大的显存,就能用上更高清的素材;
- 生成图片如使用放大算法,如果显存够大,放大倍数也能跟着上去。这样,生成的图片细节会更多,质量也会更高。
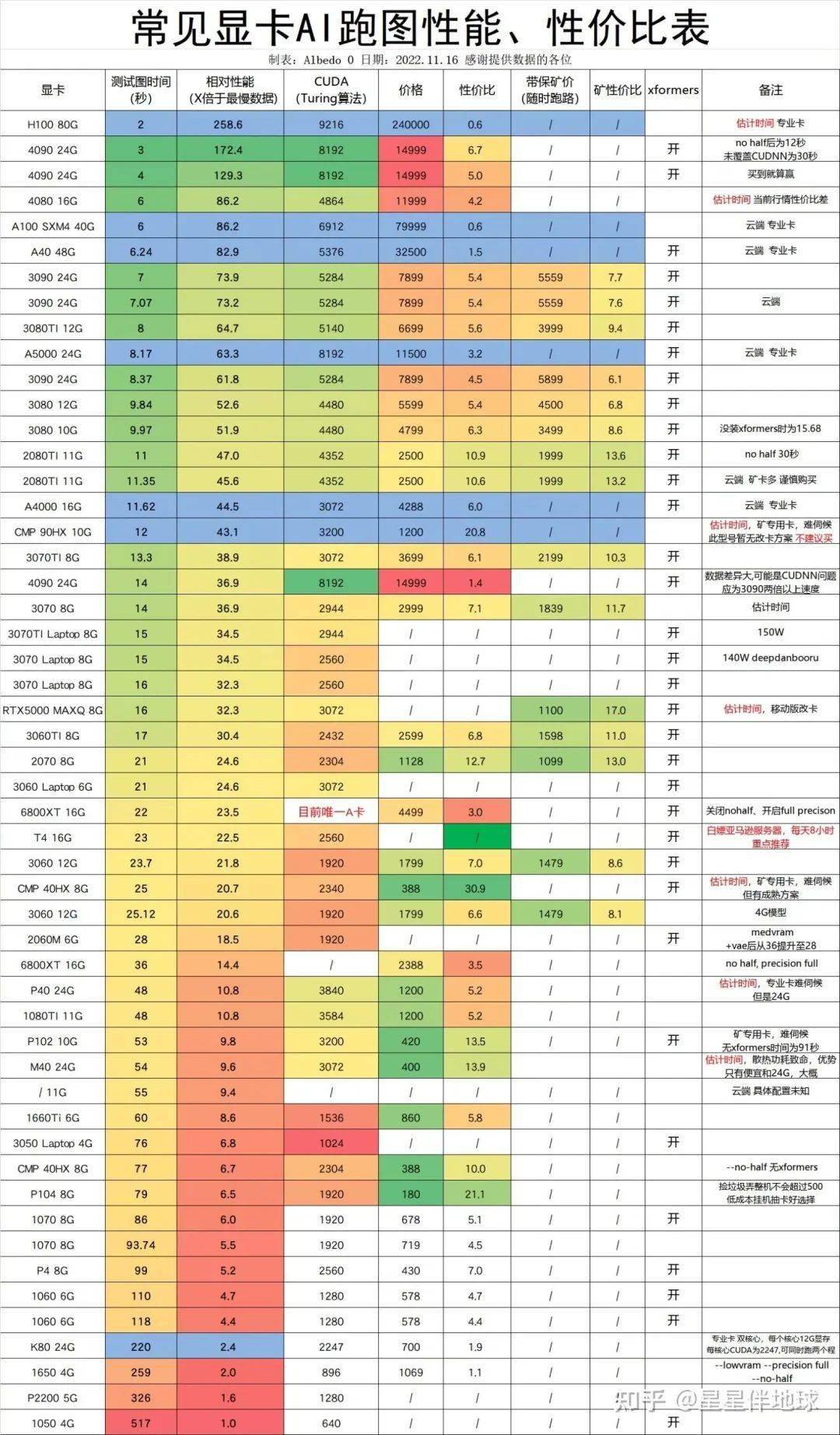
我在用的显卡是 RTX 3070 8G,应对本文的训练场景够用了。我在网上找到了一张“常见显卡 AI 跑图性能、性价比表”,供大家参考:
接下来,准备 Kohya_ss 版本的 LoRA 脚本需要的环境:
- 安装 Python/ target=_blank class=infotextkey>Python 3.10 (https://www.python.org/ftp/python/3.10.9/python-3.10.9-amd64.exe) ,下载成功后,直接双击安装,唯一需要注意的是勾选 【add python to the ‘PATH’ environment variable】 ;
- 安装 Git (https://git-scm.com/download/win) ,找到你电脑的对应版本号,下载,安装;
- 安装 Visual Studio 2015, 2017, 2019 和 2022 的可再开发组件 (https://aka.ms/vs/17/release/vc_redist.x64.exe) ,下载,安装。
在安装好 Python 3.10 和 Git 后,搜索 Powershell,点击右键,以管理员模式启动,输入 【Set-ExecutionPolicy Unrestricted】后回车,接着会跳出一段文字,选择 【A】回答 【全是】即可,关闭该窗口。
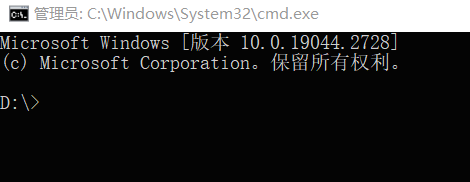
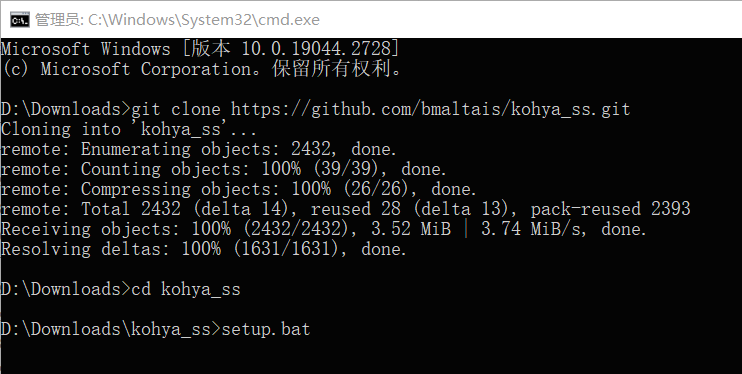
然后,就可以安装 Kohya_ss 版本的 LoRA (https://Github.com/bmaltais/kohya_ss)了。如果你想安装在电脑上某个特定位置,先在地址栏处敲击 【cmd】,回车,你会进入这样一个命令窗:
将以下代码粘贴到窗口中:
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.venvsactivate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .bitsandbytes_windows*.dll .venvLibsite-packagesbitsandbytes
cp .bitsandbytes_windowscextension.py .venvLibsite-packagesbitsandbytescextension.py
cp .bitsandbytes_windowsmain.py .venvLibsite-packagesbitsandbytescuda_setupmain.py
accelerate config
在执行 【accelerate config】后,它将询问一些设置选项,请按照以下选项依次选择:
This machine No distributed training NO NO NO all fp16
执行完后,就算装好啦!
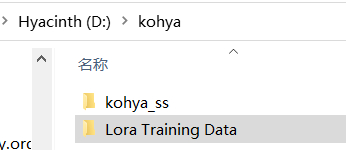
如图,文件夹的名字叫 【Kohya】, 点进去后可以看到一个叫 【kohya_ss】的文件夹。
我们还需要新建一个文件夹,比如 【Lora Training Data】用来存放后续要用的训练数据。
准备训练:多找几张图
恭喜你成功到了这一步,接下来就是 fun part 啦!
先回答一个问题: 到底需要准备多少张图做训练呢?能不能就喂一张图片?
我帮大家试了:


可见,AI 能学习到大致风格,模特穿着也像样,但没法还原花纹和细节。因为单张图片能提供的信息有限。所以, 我们应该尽量给出衣服在各个角度的图像。
以这一款动物帽子为例,我准备了三个角度的图像。

虽然数量不多,但效果竟然还不错:
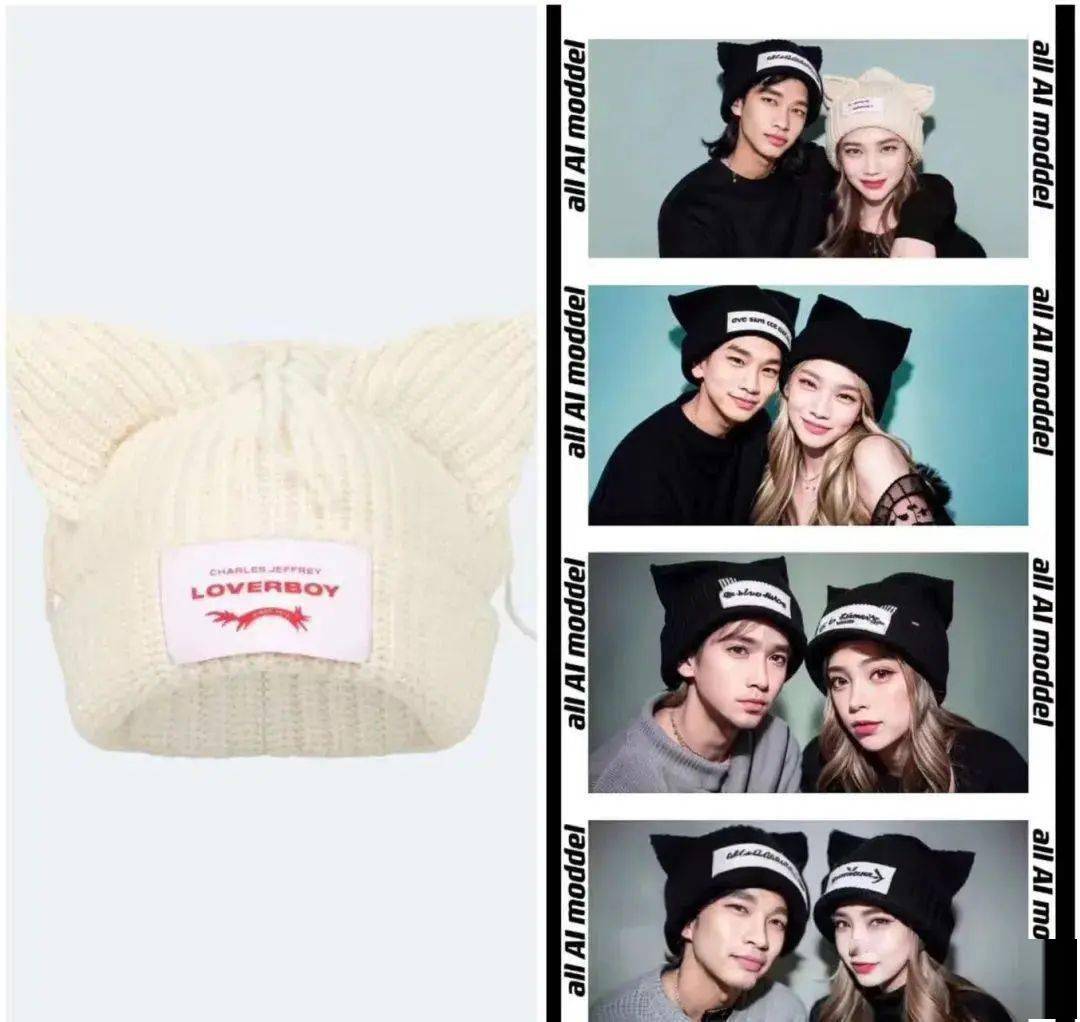
插播一句,图像的清晰度会直接影响到训练的质量, 如果图片不够清晰,我一般会先用 Topaz Gigapixel 这类 AI 修复工具将它先放大处理。
再插播一句, 为了让 AI 更有针对性地捕捉和学习到目标对象,我还会裁剪图片,尽量剪掉不必要的画面, 让目标单品更显眼。
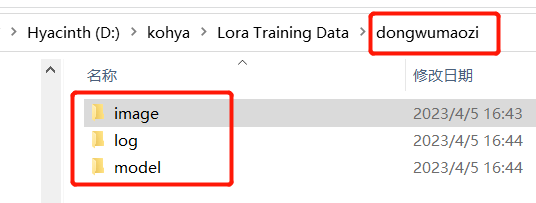
我们回到 【Lora Training Data】文件夹中,在里面创建一个新文件夹,随便命名,我起的是 【dongwumaozi】(动物帽子),然后在其中创建 3 个子文件夹,依次是 【image】、 【log】和 【model】,如图:
接着,你在 【image】这个文件夹里,再创建一个文件夹,格式是 【数字_训练的概念】, 【数字】指的是图片会被训练多少遍,我写了 【100】(100 是默认训练次数,经试用,我觉得效果都不错),AI 就会把我每张照片训练 100 遍:
然后,将准备好的图像刚进去:
让 AI 自动给图像标注
接下来,我们要打开 kohya 脚本。到 【kohya_ss】这个文件夹里,找到 【gui.bat】这个运行文件。
双击后,你会看到这么一个窗口:
复制其中的地址到浏览器中,回车。
我们会在这个界面里,指导 AI 自动给图像做标注
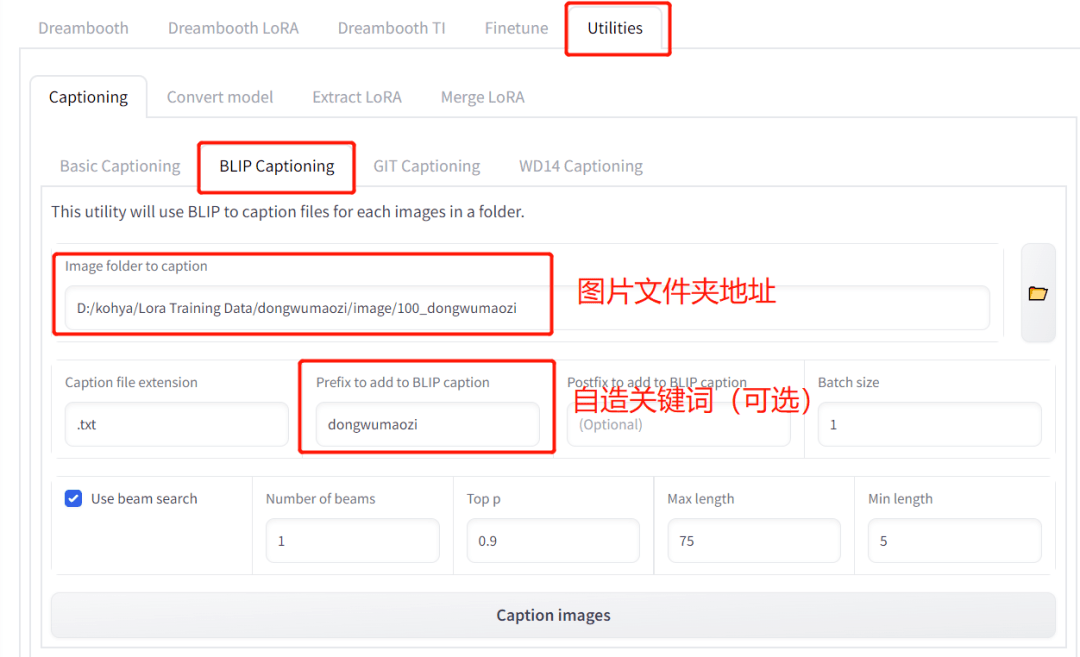
- 选择上面的 【Utilities】 ;
- 在 【Captioning】 下选择 【BLIP Captioning】 作为标注手段;
- 选择刚刚放图片的文件夹;
- (可选)在 【Prefix to add to BLIP aption】 处,看是否加入自造词,方便在后续用模型时用这个词更高效地做出对应概念,比如我这个案例里就用 【dongwumaozi】 作为一个自造关键词;
- 点击 【Caption images】 ,等待 AI 自动标注。
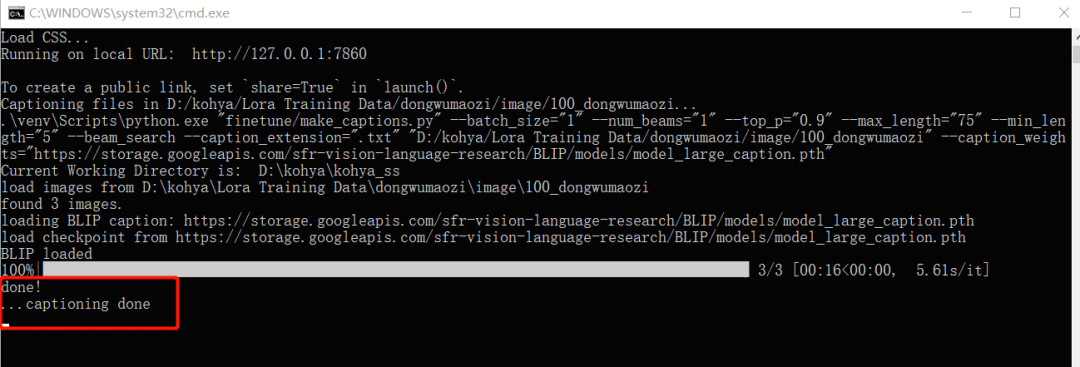
当你看到 【captioning done】后,AI 就算是标注好了。

回到 【image】文件夹后,就能看到和图片名称对应的 txt 文本描述了。如果你对机器标注的效果不太满意,打开 txt 文档手动修改,保存即可。
我也写累了,但快能开始训练了啊!
坚持住,最后再做些设置就可以开始训练了!
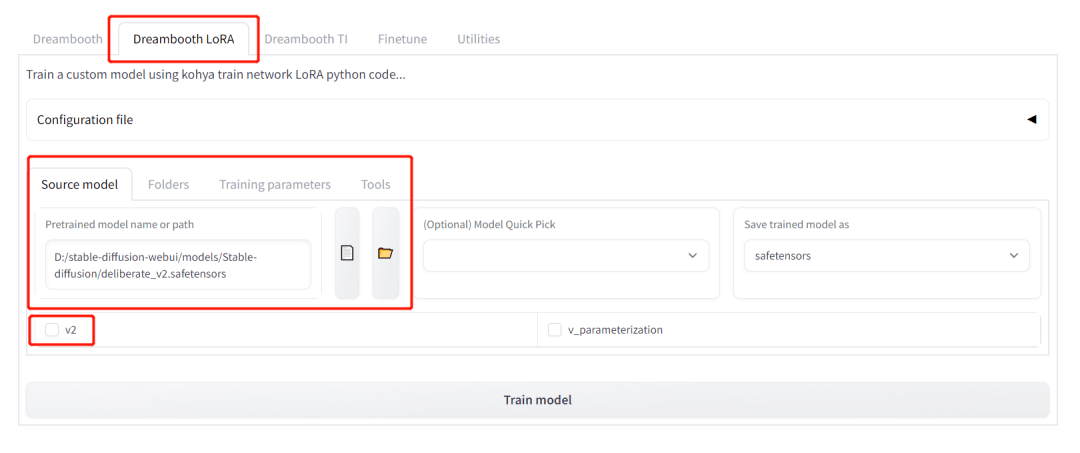
还是在刚才你执行 AI 标注的界面,点击 【Dreambooth LoRA】,点击 【Source Model】,选择你想进行训练的基础模型,默认可选 Stable Diffusion v1.5(也可以是你在 CivitAI 上下载的其他与 Stable Diffusion v1.5 平行的模型),底模我用的是 Deliberate。
需要提前下载的模型
Stable Diffusion V1.5 下载地址:
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
Deliberate 下载地址:
https://civitai.com/models/4823/deliberate
点击 【Source Model】右侧的 【Folders】,选择此前我们设置的 【Lora Training Data】底下的 【image】、 【log】和 【model】这三个文件夹。
目前在训练服装 LoRA 上,我感觉默认的训练参数效果已经很好,所以并没有再做额外的更改、调整。如果你对训练参数的设置感兴趣,可以去看看 Kohya 脚本的官方教程 (https://www.YouTube.com/watch?v=k5imq01uvUY&t=1597s)。
接下来,你就可以点击 【Train Model】炼丹了!
在 3070 上,训练时长差不多在 30 分钟左右,出去跑个步或者冲个澡,模型就训练好啦!
一般默认参数训练出来的 LoRA 大小在 9 M 左右,在 【model】这个文件夹里可以找到。
最后的最后,将 LoRA 文件拷贝到 【stable-diffusion-webui】的 【models】文件夹里对应的 【LoRA】文件夹处,再次重启 WebUI,点选出对应的 LoRA 后,写好关键词就可以生成“淘宝模特”图了:



以上图片皆由该 LoRA 生成。拿最后一张图举例,我提供以下关键词,供你参考:
正向关键词:dongwumaozi, masterpiece, best quality, photorealistic, a couple wearing black, posing for the camera, ((posing)), hugging, hands posing, (((cute couple))), wearing dongwumaozi, thick black knitted wool cap with pig ear shape decoration (loveboy’s logo label), ((black)), ((detailed face)), cinematic lighting, film poster, photo shoot, depth of field, film screeshot, soft light
另外,也可以输入一些常用的 负向关键词,比如“bad hands”等, 让 AI 消除这种生成可能。
以淘宝模特和时尚杂志开篇,后面全在讲 Python
虽然在生成“动物帽子”这个案例中,喂 3 张图就有不错的效果, 但如果你的目标单品版型、材质都较为复杂,可能得备上 5 到 30 张不同角度的图,才能更好还原。
这篇教程就当是抛砖引玉,我期待能有更多朋友分享自己的训练经验和效果。
就我个人而言,比起 AI 模特,我在买衣服时更希望看真人试穿,因为这样材质和版型才更有参加价值。
不过,未来我可能会训练一个自己的模型,然后再去叠加服装的模型,看自己的试穿效果。
还在上学那会儿,我看日剧《校对女孩河野悦子》,剧里石原里美饰演的主角将不同服装搭配剪下来再贴在一起,以此寻找灵感。那时,我觉得时尚编辑就像是魔法师。 而现在,AI 给了我更多创造的机会。
电商模特、虚拟时尚博主、服装设计师的灵感助手……AI 还有更多可被激发的潜力。
现在涌现的 这些 AI,就像是一摊墨水,所有人似乎都可以来蘸一蘸,然后写下一些特别的字迹。
参考文献
[1] 开源图像模型 Stable Diffusion 入门手册(https://mp.weixin.qq.com/s/8czNX-pXyOeFDFhs2fo7HA)
作者:海辛
编辑:biu
本文照片如无特别指出,均为作者提供。