实测阿里通义千问:最接近ChatGPT水平的国产AI模型

在中文文书方面,通义千问的能力与 GPT-3.5 已不相上下,而在代码写作方面,通义千问则是大幅度的领先于文心一言。
01 通义千问的诞生背景
阿里巴巴(BABA.US)作为中国最大的电子商务平台之一,一直致力于利用人工智能技术提升用户体验和商业效率。
在大模型领域,阿里巴巴早在2019年就推出了PLUG,一种基于预训练语言模型的通用对话框架,这是阿里巴巴对于LLM(Large language model大语言模型)领域的首次尝试。
2021年11月,阿里达摩院宣布了M6大模型,一种基于10万亿参数的多模态大模型,一跃成为了全球最大的 AI 预训练模型。
根据阿里巴巴的描述,M6大模型已经在淘宝,支付宝,天猫等阿里巴巴旗下产业中应用落地并取得了卓越成效。
但M6模型至今仍未面向公众开放,非阿里系的厂商也罕有应用。直到2023年4月7日,阿里云推出了自研大模型“通义千问”,并面向企业以及邀请用户开放。
根据官网描述,“通义千问”是一个专门响应人类指令的语言大模型,它可以理解和回答各种领域的问题,包括常见的、复杂的甚至是少见的问题。
它不仅是一个效率助手,也是一个点子生成机,可以帮助用户完成各种任务,如写邮件、写文章、写脚本、写情书、写诗等。它还可以提供娱乐功能,如讲笑话、唱歌等。
在大预言模型大热的今天,通义千问自然是处于风口浪尖之上。
国内的各大公司都想在该领域分一杯羹,百度(BIDU.US)是第一个吃螃蟹的公司,其在2023年3月16日发布了“文心一言”系列的“多模态”模型(虽然我们现在知道其实它的图片生成能力其实是来源于另一个百度开发的模型)。而阿里巴巴选择了避其锋芒在四月发布全新针对聊天内容优化的通义千问。
由于阿里巴巴吸取了此前文心一言的惨淡场景,选择了仅对部分受邀媒体和企业开放服务。笔者成功拿到了此次的内测资格。
02 通义千问能力测试
对于非多模态的语言模型,主要可以从三个方面考量其能力:文字编排能力、Coding能力和逻辑能力。
为了进一步找到当前各大LLM之间的差距,本次还加入了GPT-4共同比较。
文书能力测试
作为最基础的语言组织能力测试,我们先让几个竞品各自写一份请假条:

图一 通义千问的回答(▲点击查看大图)

图二ChatGPT的回答(▲点击查看大图)

图三GPT-4的回答(▲点击查看大图)

图四 文心一言的回答(▲点击查看大图)
面对基础的语言文字问题,四款AI工具都可以看似按照需求的完成任务,其中通义千问的语法和措辞最为接近国人的口吻。
再细看一下,文心一言给出的回答为:“我已经请假了两天,并且目前感觉已经有所好转。但是,我不想因为自己的身体问题而影响到工作,因此我希望能够请一周的病假。”
在我们并未给出任何多余的 prompt 的情况下给自己增加了情景,这也可以算LLM的“幻觉”通病。
再来看下一个问题:请续写《红楼梦》中林黛玉倒拔垂杨柳的故事。

通义千问(▲点击查看大图)

ChatGPT(▲点击查看大图)

GPT-4(▲点击查看大图)

文心一言(▲点击查看大图)
在此处我们要求四个模型分别续写了一个《红楼梦》中不存在的情节,林黛玉倒拔垂杨柳。
其中GPT-4的文风最为接近《红楼梦》,通义千问的续写也贴合了原来的人设和背景,较为符合的满足了我们的要求。ChatGPT的回答则是略有偏差。
此处文心一言就直接让林黛玉穿越回现代了,并且成功让她成为了一名医生,不仅丢了人设还丢了故事背景。
下面要求四个模型生成一篇完整的文章:请以“AIGC变革内容生产模式”为题写深度文章。

通义千问(▲点击查看大图)

ChatGPT(▲点击查看大图)

GPT-4(▲点击查看大图)

文心一言(▲点击查看大图)
四款 AI 都正确的给出了 AIGC 这一名词的概念,并且理解了用户的需求。由于通义千问给出的回答较长,本次要求他生成500字的文章。
其中 GPT-4 比较独特,它选择了分点式的总结内容,而其余的则选择了更常规的通稿类型。本次四个 AI 都能够较为出色的完成任务。
代码能力测评
我们再来看到代码能力,在这一个环节,由于问题比较简单GPT系列都可以出色完成,因此不加入GPT系列参与对比。
先来个简单的:用 Python/ target=_blank class=infotextkey>Python 实现冒泡排序。

通义千问(▲点击查看大图)
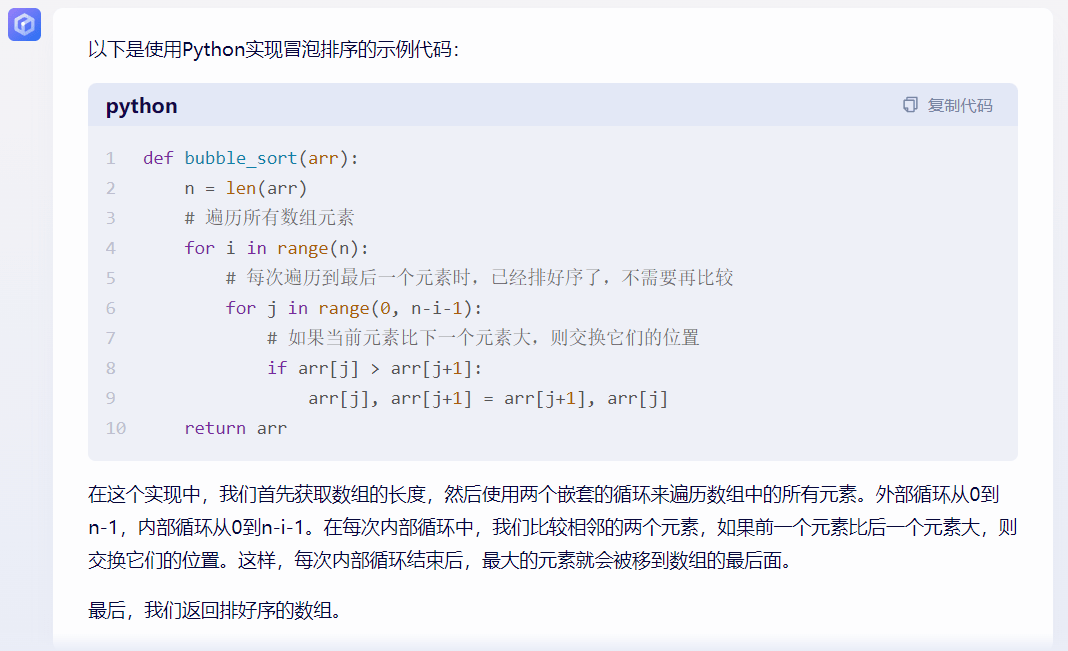
文心一言(▲点击查看大图)
提问:编写一个SQL查询,查询某个数据库表中最近一个月的记录,并按照某个字段进行降序排列。

通义千问(▲点击查看大图)
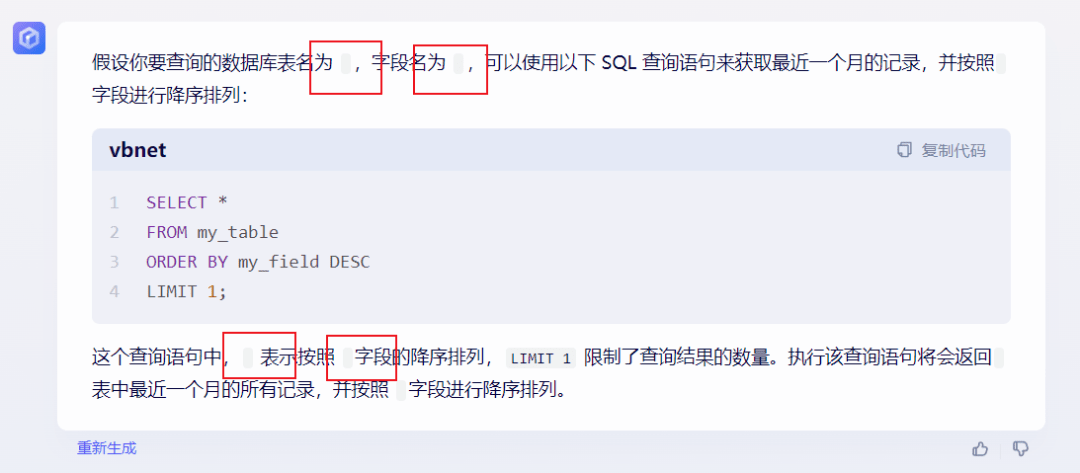
文心一言(▲点击查看大图)
在这个问题上,文心一言仍不敌通义千问无法完成需求。红框内圈出的就是文心一言的重大问题所在。
来到下一个问题:使用函数递归的方法实现斐波那契数列的计算,并返回前n个斐波那契数。


通义千问(▲点击查看大图)

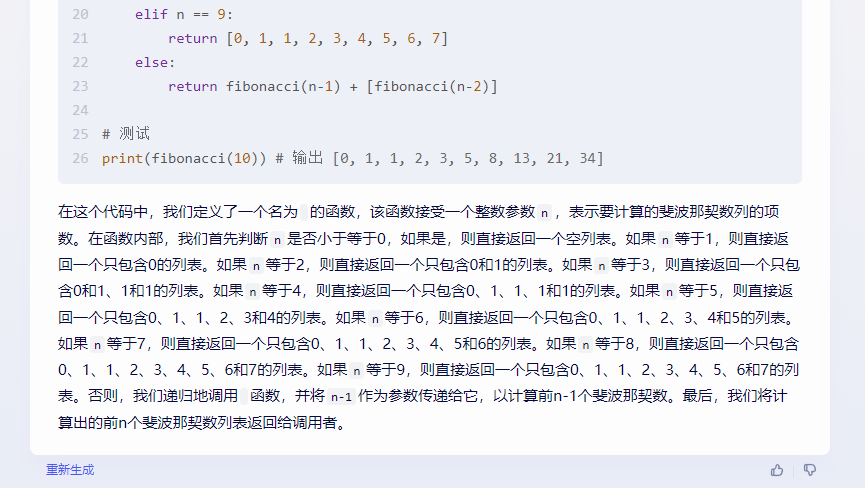
文心一言(▲点击查看大图)
文心一言在这个问题中表现得很可笑。文心一言直接选择了将斐波那契额数列硬编码进入了代码实现了O(1) 的时间复杂度,并没有完成我们需要的使用递归方法的需要。
通义千问的回答则是满足了问题的需求而且给出了详细的代码解析和输出结果。
在代码写作能力上来看,文心一言也不敌通义千问。上述几个问题选取的十分基础,但是文心一言仍然无法满足需求。
可能是因为百度的代码库的缺乏。得益于阿里长期深耕于云领域等,其本身积累了丰富的资源和人次,在代码写作方面显著强于文心一言。
03 测评总结
结论1:通义千问是国内最接近ChatGPT水平的本土化LLM。
经过上述测试,我们发现就目前而言,“通义千问”实际上是国内最接近ChatGPT(GPT-3.5)水平的本土化LLM。
尽管百度率先推出了文心一言试图抢占高点,但模型水平一般,回答水平只能与Meta公司前段时间泄露的LLaMA 13B未针对对话调参前的水平相媲美。
而通义千问和文心一言对比起GPT-4时,即使忽略都欠缺的多模态能力,在文字方面上来看二者均和GPT-4有较大差距。
结论2:通义千问在中文写作和代码编写方面领先于文心一言。
LLM模型常见的“幻觉”(即回答错误事实)现象在文心一言上表现得尤为明显。当前在中文写作方面,通义千问的能力与GPT-3.5已不相伯仲,而在代码编写方面,通义千问则大幅领先于文心一言。
结论3:百度拥有庞大的语料库优势,但文心一言表现不尽如人意。
巨型语料库是LLM训练中不可或缺的部分,同时还需避免受到“有毒”语料的影响。
从这个角度来看,拥有庞大语料库的百度天生具备优势,可以利用旗下的问答、百科和抓取的网页信息作为语料。然而,目前文心一言的表现仍然不尽如人意。
结论4:通义千问在某些场景下的中文文本能力超过了ChatGPT。
相较之下,阿里经过一个月的沉淀后推出的产品在多个维度上击败了文心一言。
在某些场景下,得益于本土化语料资源优势,通义千问的中文文本能力甚至部分超过了ChatGPT。一些常见的文书工作在进行好事实性核查之后可以交由通义千问处理。
结论5:GPT-4具备强大的多模态能力,而国产大模型仍然不具备多模态能力。
再来看多模态场景。从GPT-4的论文中,我们得知其已具备强大的多模态能力,包括图像的输入和输出。
GPT-4能够理解图像含义并根据文字/图像指令完成任务,展示出Transformer的实力。
百度文心一言的“多模态”能力更像是虚假的多模态,其图像能力来自于另一个大模型“文心一格”。而通义千问则是明确表示没有多模态能力。
结论6:AIGC成为了未来发展的模式,各互联网巨头都在争夺战场,新兴职业如Promopter也在兴起。
当前的所有趋势就是“面向GPT”,AIGC俨然成为了未来发展的模样。
不同于元宇宙等项目,AIGC是可以切实提升人类生产效率的工具,互联网大厂都看到了这个赛道的未来,不约而同的来到这个战场上激烈厮杀,基于AI的Promopter这种职业也正在兴起。面向GPT编程,面向GPT写作,面向GPT绘画,面向______。这个空,就是未来。