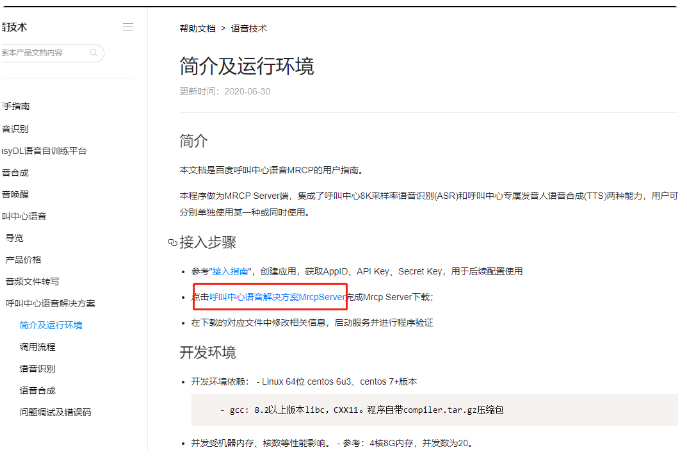
Meta AI连发三篇Textless NLP论文:语音生成的终极答案?
编辑:LRS
【新智元导读】AI语音生成的特点就是呆板,没有情绪的起伏。最近Meta AI连发了三篇Textless NLP的论文,不仅开源了textlesslib库,还展示了AI对话在语音情感转换的惊人能力!
在日常交流的时候,人们往往会使用一些「非语言」的信号,比如语调、情感表达、停顿、口音、节奏等来强化对话互动的效果。
像开心、愤怒、失落、困倦时说同一句话,虽然内容都一样,但听起来的感觉肯定是非常不同的,而AI的发声则比较死板。
目前AI语音生成系统大部分还是根据书面文本来学习发声,也就是说,模型只能知道说话的内容,却不知道人类以何种语速、情感来说,对于文本之外富有表现力的语音信号根本捕捉不到。
所以AI虽然能当主持人播新闻,但在一些特殊的应用场景里,比如小品、相声、脱口秀这些语言艺术领域,人工智能还没法取代人类来说话。
Meta AI去年推出了一个突破性的自然语言处理模型GSLM,打破了传统模型对文本的依赖。
GSLM可以通过直接处理原始的音频信号来发现结构化的内容,无需使用任何人工标签或文本,就像人学语言的过程一样。GSLM能够让NLP模型捕捉到口头语言的表现力,也可以作为下游应用的一种预训练形式,或者作为一种生成工具,从给定的输入音频提示中生成后续音频。
最近,Meta基于GSLM连发三篇论文,朝着更有表现力的NLP模型向前走了一大步。
开源textlesslib
发布了一个开源的Textless Python/ target=_blank class=infotextkey>Python库,机器学习开发人员可以更快地在GSLM组件(编码器,语言模型,解码器)上进行实验。
论文链接:https://arxiv.org/pdf/2202.07359.pdf
代码链接:https://github.com/facebookresearch/textlesslib
Textless NLP是一个活跃的研究领域,旨在使NLP相关的技术和工具可以直接用于口语。通过使用自监督学习的离散语音表征,Textless NLP技术能够在那些没有书面形式的语言上或在基于文本的方法无法获得的口语信息中开发出更多有趣的NLP应用。
Meta开源的textlesslib是一个旨在促进无文本NLP研究的库。该库的目标是加快研究周期,并降低初学者的学习曲线。库中提供高度可配置的、现成的可用工具,将语音编码为离散值序列,并提供工具将这种流解码回音频领域。
语音情感转换
对于一些表达性的发声,比如笑声、哈欠和哭声,研究人员开发的模型已经能够捕捉到这些信号了。这些表达方式对于以人的方式理解互动的背景至关重要,模型能够辨别出那些有可能传达关于他们的交流意图或他们试图传达的情感的细微差别,比如是讽刺、烦躁还是无聊等等。
论文链接:https://arxiv.org/pdf/2111.07402.pdf
演示链接:https://speechbot.github.io/emotion/
语音情感转换(Speech Emotion Conversion)是指在保留词汇内容和说话人身份的情况下修改语音语料的可感知情感的任务。在这篇论文中,研究人员把情感转换的问题作为一项口语翻译任务,将语音分解成离散的、不相干的,由内容单元、音调(f0)、说话人和情绪组成的学习表征。
模型先通过将内容单元翻译成目标情感来修改语音内容,然后根据这些单元来预测声音特征,最后通过将预测的表征送入一个神经声码器来生成语音波形。
这种范式使得模型不止能发现信号的频谱和参数变化,还可以对非语言发声进行建模,如插入笑声、消除哈欠等。论文在客观上和主观上证明了所提出的方法在感知情感和音频质量方面优于基线。实验部分严格评估了这样一个复杂系统的所有组成部分,并以广泛的模型分析和消融研究作为结论,以更好地强调拟议方法的架构选择、优势和劣势。
比如在一个包含五种情绪表达方式(中立、愤怒、娱乐、困倦或厌恶)的情绪转换任务中,模型需要根据输入音频转换到目标情绪,可以看到整个流程就相当于是一个端到端的序列翻译问题,所以插入、删除、替换一些非语言的音频信号来转换情感就会更容易。
经过实验评估可以看到,提出的模型与以往最佳情感语音转换模型相比,取得了极大的质量提升。事实上,结果与原始音频的质量非常接近(图表中以浅绿色为原始音频)。
有情感的AI对话
Meta AI建立了一个可以让两个人工智能agent之间自发的、实时的闲聊模型,每个agent的行为因素,如偶尔的重叠或停顿都很真实,这对建立像虚拟助手这样的应用场景来说很重要,可以让AI更好地理解细微的社交线索和信号,比如能够捕捉到与人聊天时的细微的积极或消极反馈。
论文链接:https://arxiv.org/pdf/2203.16502.pdf
演示链接:https://speechbot.github.io/dgslm/
文中提出的dGSLM模型是第一个能够生成自然口语对话音频样本的Textless模型。模型的开发上利用了最近在无监督口语单元发现方面的工作,加上一个带有交叉注意力的双塔Transformer架构,在2000小时的双通道原始对话音频(Fisher数据集)上训练,没有任何文字或标签数据。dGSLM能够在两个通道中同时产生语音、笑声和其他副语言信号,让谈话的转折非常自然。
颠覆传统NLP
在不久的将来,基于Textless NLP技术构建的下游应用将会呈井喷之势,由于模型训练既不需要资源密集型的文本标签,也不需要自动语音识别系统(ASR),模型可以直接通过音频信号进行问答。Meta AI的研究人员认为语音中的亲和力可以帮助更好地解析一个句子,这反过来又促进了对意图的理解,能够提高问题回答的性能。
其中一个应用场景是语音到语音的翻译,也可以叫做AI翻译配音(dubbing)。传统的流畅通常是基于文本来完成的,需要先将音频转换为文本,执行翻译,再将文本转换为音频信号。
比如大火的「鱿鱼游戏」多语言版本就用到了这一技术。
但流程太复杂会使得整个系统变得难以训练,也会丢掉一些口头语言的表现力,不仅是因为语调和非语言表达在文本中丢失,还因为语言模型在文本中的训练缺少了这些信号处理模块。
而自监督的语音表示方法能够从原始音频中学习离散的单元,可以消除对文本的依赖,研究人员认为Textless NLP可以胜过传统的复合系统(ASR+NLP),也有可能整合非语言发声和声调信息,在音素之上传达丰富的语义和语用信息,而这些信息通常在文本中无法获得。
随着世界变得更加数字化,元宇宙中也包含越来越多由人工智能驱动的应用程序,这些NPC可以创造新的体验。而这种全新体验不止局限于文本的交流,未来将会走向更流畅的互动方式,如语音和手势等。
所有这些使用表征和自我监督学习的进步都有可能帮助研究人员摆脱传统的基于文本的模型,建立更自然、更有吸引力的未来人工智能系统。
除了缺乏表现力之外,传统的NLP应用,依靠大量的文本资源,但在世界上只有少数几种语言有如此大规模的标注数据。
从长远来看,相信Textless NLP系统的进步也将有助于使人工智能对更多人具有包容性,特别是对于那些讲没有标准化书写系统的语言和方言的人,如方言阿拉伯语或瑞士德语。
参考资料:
https://ai.facebook.com/blog/generating-chit-chat-including-laughs-yawns-ums-and-other-nonverbal-cues-from-raw-audio