在本文中,我们将探讨如何为生产准备机器学习模型,并将其部署在简单的 Web 应用程序中。部署机器学习模型本身就是一门艺术。事实上,将机器学习模型成功投入生产超出了数据科学知识的范围,并且涉及许多软件开发和DevOps技能。你为什么要关心这一切?目前,数据科学团队中最有价值的角色之一是机器学习工程师。这个角色聚集了两全其美的精华。
这些工程师不仅知道如何将不同的机器学习和深度学习模型应用于适当的问题,还知道如何测试它们,验证它们并最终部署它们。拥有一个能够将机器学习模型投入生产的人对任何公司来说都是一笔巨大的资产。一般来说,这是Rubik's Code提供的主要服务类型。为了成为一名成功的机器学习工程师,你需要具备各种技能,而不仅仅是关注数据。实际上,为机器学习模型编写的代码量远小于支持测试和提供该模型的代码量。
MLOps,一个围绕这种需求构建的工程术语,正在成为一种新的趋势。这就是为什么在本文中,我们将重点介绍您需要了解的几种技术,以便构建一个用户想要的成功机器学习应用程序。本教程中提供的完整解决方案由两个组件组成:服务器端和客户端。这是基本的 Web 体系结构,其中客户端与应用程序的用户交互并将其发送到服务器端。服务器端执行数据处理,或者在本例中运行预测,并将结果返回到客户端,客户端将其呈现给用户。从本质上讲,在本文中,我们构建了一个可以用下图表示的小系统:
MLOps,一个围绕这种需求构建的工程术语,正在成为一种新的趋势。这就是为什么在本文中,我们将重点介绍您需要了解的几种技术,以便构建一个用户想要的成功机器学习应用程序。本教程中提供的完整解决方案由两个组件组成:服务器端和客户端。这是基本的 Web 体系结构,其中客户端与应用程序的用户交互并将其发送到服务器端。服务器端执行数据处理,或者在本例中运行预测,并将结果返回到客户端,客户端将其呈现给用户。
为了涵盖所有内容,我们需要涵盖几个主题:
- 安装和数据集
- Rest API 基础知识
- FastAPI 基础知识
- 客户端 – 用户界面
- 服务器端 – 使用 FastAPI 进行模型训练的解决方案
- 服务器端 – 使用 FastAPI 加载模型的解决方案
1. 安装和数据集
要成功运行本教程中的示例,需要安装 Python/ target=_blank class=infotextkey>Python 3.6 或更高版本。最简单的方法是使用Anaconda分发。它附带了本教程所需的所有其他必要库,如Pandas,NumPy,SciKit Learn等。要安装 FastAPI 及其所有依赖项,请使用以下命令:
pip install fastapi[all]
这包括 Uvicorn,一个运行代码的 ASGI 服务器。如果您对其他一些ASGI服务器(如Hypercorn)更满意,那也很好,您可以在本教程中使用它。
对于Web应用程序,我们使用Angular。为此,您需要安装 Node.js 和 npm。使用Angular框架进行操作的最常见方法是使用Angular命令行界面 - Angular-CLI。这个工具的好处之一是,一旦我们用它初始化了我们的应用程序,我们就可以使用TypeScript,它将自动转换为JAVAScript。安装此接口是通过 npm 完成的,当然,通过运行以下命令:
npm install -g angular-cli
当您要创建新的Angular应用程序时,您可以使用以下命令执行此操作:
ng new Application_name
此命令将创建一个文件夹结构,供我们的应用程序使用。要运行此应用程序,请将 shell 放在刚刚创建的应用程序的根文件夹 (cd application_name) 中,然后调用命令:
ng serve
如果您在转到浏览器并打开localhost:4200后按照上述步骤操作,您将能够看到默认的Angular应用程序。
我们在本文中使用的数据来自PalmerPenguins Dataset。该数据集最近被引入,作为著名的Iris数据集的替代方案。它由Kristen Gorman博士和南极洲LTER的Palmer站创建。您可以在此处或通过Kaggle获取此数据集。该数据集主要由两个数据集组成,每个数据集包含344只企鹅的数据。就像在鸢尾花数据集中一样,有3种不同种类的企鹅来自帕尔默群岛的3个岛屿。此外,这些数据集还包含每个物种的 culmen 维度。Culmen是鸟喙的上脊。在简化的企鹅数据中,culmen的长度和深度被重命名为变量culmen_length_mm和culmen_depth_mm。以下是数据集:
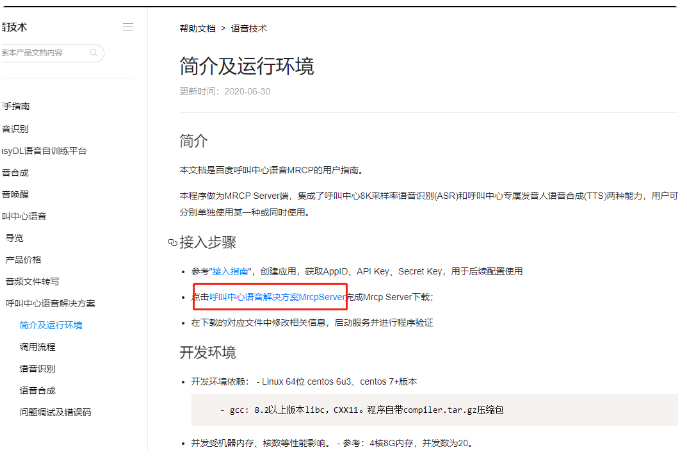
2. REST API 基础知识
在我们开始使用Python和Flask实现Web应用程序之前,让我们首先找出什么是REST API。现在,我相信你一生中已经看过这个词两次了。术语的第二部分 - API代表应用程序编程接口。从本质上讲,它 API 表示程序用于相互通信的一组规则。例如,在服务器-客户端体系结构中,应用程序的服务器端以公开可由应用程序客户端调用的方法进行编程。这意味着客户端可以在其代码中调用服务器上的方法,并从中获取特定结果。REST 代表"具象状态转移"。这表示开发人员在构建 API 时应遵循的一组规则。它定义了 API 的外观,因此 API 是标准化的。
其中一个规则定义了在链接特定 URL 时可以收集数据或资源。例如,您可以链接"api.rubikscode.com/blogs"并获取博客列表作为响应。URL api.rubikscode.com/blogs "称为"请求",返回的客户端列表称为响应。每个请求由 4 个部分组成:
- 终结点(路由) – 这是我们之前提到的 URL。它的结构是这样的 - "根端点/?根终结点是起点,后跟路径和查询参数。该路径定义所需的特定资源。例如,GitHub 的 API 的根端点是"api.github.com",而我在 GitHub 上的存储库列表的完整端点是 https://api.github.com/users/nmzivkovic/repos。
- 方法 – 可以发送五种类型的请求,该方法定义此类型:GET – 用于获取或读取信息。开机自检 – 用于创建新资源。PUT 和 PATCH – 它们用于更新资源。删除 – 删除资源。
- 标头 – 标头用于以属性值对的形式向客户端和服务器提供其他信息。MDN的HTTP头引用上的有效头列表。
- 正文 – 此部分包含客户端发送到服务器的信息。它不用于 GET 请求。
我们要在本文中创建的是 Web 服务器,它为 Iris 预测提供模型。我们希望构建 API,应用程序客户端可以使用该 API 从模型中获取预测。这是使用Python框架Flask完成的。
2. 快速API基础知识
在本文中,我们使用 FastAPI 来构建 REST API。我们为什么要使用这个库?这有几个原因。与其他主要的Python框架(如Flask和Django)相比,FastAPI更快。此外,此框架还支持使用 async/await Python 关键字的开箱即用异步代码。这进一步提高了其性能。使FastAPI成为最好的API库之一的最显着的功能可能是内置的交互式文档。稍后我们将更详细地探讨此功能。最后,使用 FastAPI 构建的应用程序非常易于测试和部署。由于所有这些,FastAPI成为使用Python构建Web API应用程序的标准。
2.1 首次快速API应用
好了,让我们构建第一个 FastAPI 应用程序。很酷的事情是,一个简单的HelloWorld示例与FastAPI可以用5行代码创建。我不是在开玩笑。准备好了吗?以下是您需要执行的操作:
- 创建一个新文件夹并将其命名为"my_first_fastapi"(或者您认为:)的任何内容)
- 创建一个名为 main.py 的新Python脚本(或者你觉得它:)的任何内容)
- 将以下代码添加到 main.py:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
- 转到终端并放入my_first_fastapi文件夹中
- 运行以下命令:
uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
太棒了,现在你有一个Web服务器在 http://127.0.0.1:8000 运行。如果您在浏览器中转到此地址,您将看到如下内容:
请注意,在上面的代码中@app.get("route") 装饰器?此修饰器确定可以在特定终结点上发出的请求类型。这意味着,例如,如果我们放置 app.get("/users"),我们将 REST API 端点定义为"users",我们可以在其上发出 GET http 请求。
2.2 快速 API 文档
FastAPI最酷的事情之一是内置的交互式文档。它以 Swagger UI 呈现。如果我们使用刚刚构建的示例并转到
http://127.0.0.1:8000/docs 我们将看到 API 的文档页面:
您可以单击任何端点,进一步浏览并了解它们。本文档的最大好处可能是,您可以通过单击"试用"按钮来执行实时浏览器内测试。
我知道,对吧?!
好了,回到我们的应用程序,让我们看看如何利用 FastAPI 进行机器学习部署。
3. 客户端和用户界面
好的,为了让用户与我们的模型进行通信,我们需要某种用户界面。有许多可用的框架和技术可供您使用。在这里,您可以看到我们如何用Flask和Python做类似的事情。在本教程中,我们使用 Angular 构建用户可以与之交互的 Web 应用程序。
我们不会在这里过多地讨论实现的细节,因为重点是FastAPI和机器学习模型。从本质上讲,应用程序Train和Predict的工具栏中有两个项目,它将我们引导到两个具有相同名称的网页。完整的内容在两个组件中实现:训练组件和预测组件。还有一项服务 - fastapi.service。此服务包含对服务器端实现的 REST API 的调用。
在训练选项卡中,您可以选择要训练的模型,选择要试验的数据(采用类似 PalmerPenguing 数据集的格式),以及定义测试数据集的大小。按下训练按钮后,包含此信息的 HTTP 请求将发送到服务器端,我们希望它将训练定义的机器学习模型。
在"预测"选项卡中,用户可以使用通过上一个选项卡训练的机器学习模型进行预测。在这里,用户可以输入描述企鹅的参数,用户希望对此进行预测。按下"预测"按钮后,此信息将发送到服务器,该服务器使用机器学习模型进行预测并将其发送回用户。
要运行此应用程序(我们假设您已经克隆了 GitHub 存储库),请打开终端并放入 train_solutionclient 并运行以下命令:
npm install
ng serve
完成此操作后,此 Web 应用将在 localhost:4200 上可用。好吧,让我们看看服务器端实现的样子。
3. 模型训练解决方案
服务器解决方案由多个组件组成,这些组件可以在train_solutionserver 文件夹中的文件中找到。整体架构如下所示:
让我们来探索每个组件。
3.1 数据合同
train_parameters.py文件包含从 Web 应用程序的"训练"选项卡传递的模型。从本质上讲,此文件包含一个数据协定,当来自客户端的HTTP请求到达我们的服务器时,将使用该协定。
from pydantic import BaseModel
class TrainParameters(BaseModel):
model: str
path: str
testsize: float
请注意,我们使用 Pydantic、数据验证和设置管理库进行类型注释。此库在运行时强制实施类型提示,并在数据无效时提供用户友好的错误。我们在penguin_sample.py中使用的同一库,其中我们定义了从Web应用程序的预测页面发送HTTP请求时使用的数据协定:
from pydantic import BaseModel
class PenguinSample(BaseModel):
island: str
culmenLength: float
culmenDepth: float
flipperLength: float
bodyMass: float
sex: str
species: str
def __getitem__(self, item):
return getattr(self, item)
3.2 数据加载器
此类用于加载和准备数据。这是它的样子:
import pandas as pd
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from penguin_sample import PenguinSample
class DataLoader():
def __init__(self, test_size = 0.2, scale = True):
self.test_size = test_size
self.scale = scale
self.scaler = StandardScaler()
self._island_map = {}
self._sex_map = {}
def load_preprocess(self, path):
data = pd.read_csv(path)
data = self._feature_engineering_pipeline(data)
X = data.drop(['species', "island", "sex"], axis=1)
if(self.scale):
X = self.scaler.fit_transform(X)
y = data['species']
spicies = {'Adelie': 0, 'Chinstrap': 1, 'Gentoo': 2}
y = [spicies[item] for item in y]
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=self.test_size,
random_state=33)
return X_train, X_test, y_train, y_test
def prepare_sample(self, raw_sample: PenguinSample):
island = self._island_map[raw_sample.island]
sex = self._sex_map[raw_sample.sex]
sample = [raw_sample.culmenLength, raw_sample.culmenDepth, raw_sample.flipperLength,
raw_sample.bodyMass, island, sex]
sample = np.array([np.asarray(sample)]).reshape(-1, 1)
if(self.scale):
self.scaler.fit_transform(sample)
return sample.reshape(1, -1)
def _feature_engineering_pipeline(self, data):
data['culmen_length_mm'].fillna((data['culmen_length_mm'].mean()), inplace=True)
data['culmen_depth_mm'].fillna((data['culmen_depth_mm'].mean()), inplace=True)
data['flipper_length_mm'].fillna((data['flipper_length_mm'].mean()), inplace=True)
data['body_mass_g'].fillna((data['body_mass_g'].mean()), inplace=True)
data["species"] = data["species"].astype('category')
data["island"] = data["island"].astype('category')
data["sex"] = data["sex"].astype('category')
data["island_cat"] = data["island"].cat.codes
data["sex_cat"] = data["sex"].cat.codes
self._island_map = dict(zip(data['island'], data['island'].cat.codes))
self._sex_map = dict(zip(data['sex'], data['sex'].cat.codes))
return data
作为构造函数中的参数,它接收测试数据集大小和指示数据是否应缩放的标志。此类中有两个公共方法和一个私有方法:
- _feature_engineering_pipeline – 此方法在现有集合上进行小型特征工程。也就是说,填充缺失的数据并对分类数据进行编码。如果您想了解有关功能工程的更多信息,请查看此博客文章。
- load_preprocess – 此方法执行繁重的工作,它从定义的路径加载数据,并将数据拆分为训练和测试数据集。
- prepare_sample – 当新样本进入我们的系统时,我们需要以与处理训练数据相同的方式处理它。这就是为什么我们在进行进一步预测之前使用prepare_sample方法的原因。
3.3 模型训练器
此组件负责训练模型。通过构造函数,它接收有关用户选择的算法的信息,并从那里开始处理它。这是它的样子:
from data_loader import DataLoader
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from penguin_sample import PenguinSample
class ModelTrainer():
def __init__(self, algoritm, test_size=0.2):
if(algoritm == 'svm'):
self.data_loader = DataLoader()
self.model = SVC(kernel="rbf", gamma=0.1, C=500, verbose=True)
if(algoritm == 'logistic regression'):
self.data_loader = DataLoader()
self.model = LogisticRegression(C=1e20, verbose=True)
if(algoritm == 'decision tree'):
self.data_loader = DataLoader(scale = False)
self.model = DecisionTreeClassifier(max_depth=5)
if(algoritm == 'random forest'):
self.data_loader = DataLoader(scale = False)
self.model = RandomForestClassifier(n_estimators=11, max_leaf_nodes=16, n_jobs=-1,
verbose=True)
def train(self, path):
X_train, X_test, y_train, y_test = self.data_loader.load_preprocess(path)
self.model.fit(X_train, y_train)
predictions = self.model.predict(X_test)
return accuracy_score(predictions, y_test)
def predict(self, data: PenguinSample):
prepared_sample = self.data_loader.prepare_sample(data)
return self.model.predict(prepared_sample)
在构造函数中,实例化了正确的模型。如您所见,使用了SciKit Learn中的类。除此之外,还创建了DataLoader的一个实例。在训练方法中,检索数据并训练模型。完成此操作后,将计算准确性分数,并将该值返回给调用方。另一方面,预测方法接收新示例,并使用数据加载程序实例将其调整到模型。然后调用 predict 方法,并将结果返回给调用方。
3.4 REST API 模块
最重要的文件是 main.py 文件。此文件将所有其他部分放在一起,并使用 FastAPI 构建 REST API。这是看起来的样子:
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from model_trainer import ModelTrainer
from train_parameters import TrainParameters
from penguin_sample import PenguinSample
origins = [
"http://localhost:8000",
"http://localhost:4200"
]
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.model = ModelTrainer('svm')
@app.post("/train")
async def train(params: TrainParameters):
print("Model Training Started")
app.model = ModelTrainer(params.model.lower(), params.testsize)
accuracy = app.model.train(params.path)
return accuracy
@app.post("/predict")
async def predict(data:PenguinSample):
print("Predicting")
spicies_map = {0: 'Adelie', 1: 'Chinstrap', 2: 'Gentoo'}
species = app.model.predict(data)
return spicies_map[species[0]]
首先,我们导入所有必要的库。由于我们的服务器在 http://localhost:8000 和客户端中以 http://localhost:4200 运行,因此我们需要处理 CORS 策略。这就是我们导入 CORSMiddleware 的原因。此类在应用初始化期间使用:
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.model = ModelTrainer('svm')
请注意,我们在那里添加了一个 ModelTrainer 的实例。此实例只是一个占位符,稍后将替换。有两个终结点"/trian"和"/predict"都接受POST HTTP请求。这样,我们有两个函数来处理这些请求。训练方法根据从客户端收到的参数创建 ModelTrainer 的新实例。然后,它运行模型的训练并返回模型的准确性:
@app.post("/train")
async def train(params: TrainParameters):
print("Model Training Started")
app.model = ModelTrainer(params.model.lower(), params.testsize)
accuracy = app.model.train(params.path)
return accuracy
预测方法是从 Web 应用程序的预测选项卡接收数据。它从 ModelTrainer 调用 predict 方法并返回预测值:
@app.post("/predict")
async def predict(data:PenguinSample):
print("Predicting")
spicies_map = {0: 'Adelie', 1: 'Chinstrap', 2: 'Gentoo'}
species = app.model.predict(data)
return spicies_map[species[0]]
3.5 测试服务器端
要运行此解决方案,请打开终端,然后转到train_solutionserver 文件夹。运行以下命令:
uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
应用程序运行后,转到浏览器中的localhost:8000 / docs。您应该看到如下内容:
首先,让我们测试一下训练终结点。展开它,然后单击"试用"按钮:
作为请求正文传递此 json 对象:
{
"model": "svm",
"path": "./data/penguins_size.csv",
"testsize": 0.2
}
然后点击 执行 按钮:
以下是我们得到的回应:
以类似的方式,我们可以测试预测端点。试试吧!
3.6 一起运行
要运行服务器端,您需要转到train_solutionserver文件夹并使用以下命令:
uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
在另一个终端中,您需要转到train_solutionclient文件夹并运行:
npm install
ng serve
√ Browser application bundle generation complete.
Initial Chunk Files | Names | Size
vendor.js | vendor | 3.02 MB
polyfills.js | polyfills | 481.27 kB
styles.css, styles.js | styles | 340.83 kB
main.js | main | 93.72 kB
runtime.js | runtime | 6.15 kB
| Initial Total | 3.92 MB
Build at: 2020-11-22T10:33:00.423Z - Hash: bf345d81dfd56983facb - Time: 10867ms
** Angular Live Development Server is listening on localhost:4200, open your browser on http://localhost:4200/ **
√ Compiled successfully.
完成此操作后,您可以转到localhost:4200并测试应用程序:
4. 模型加载解决方案
现在,以前的解决方案真的很漂亮。我真的很喜欢你可以选择不同的模型并玩转参数。然而,即使它是底层的,它也不是一个现实世界的例子,它更像是一个虚荣的项目。在实际解决方案中,一个组件负责收集数据,另一个组件负责处理该数据,第三个组件负责定期训练模型并将其存储在某个位置。然后,REST API 会利用这些存储的模型。现在,所有这些对于这个简单的教程来说都太多了,但是,我仍然需要给出一些更接近现实世界的问题和解决方案的东西。因此,服务器端的体系结构更改为:
这些更改也会影响 UI。火车选项卡变成了"加载"选项卡,它更简单一些。没有测试大小定义,也没有数据路径定义。但是,用户仍然可以选择要使用的模型。该解决方案位于load_solution/客户端路径中,如下所示:
服务器端位于load_solution/服务器文件夹中,它的变化更多一些。让我们来看看每个组件。
4.1 训练和保存模型
您可能已经注意到解决方案文件夹中的新文件夹"models"。在此文件夹中,您可以找到以下文件:
这些是已经训练过的模型。实际上,有一个脚本train_models_script.py,如果要再次重新训练以下模型,则可以运行该脚本。它利用了先前实现中的零碎部分,但有一个主要区别。模型不存储在内存中,而是存储在硬设备中。脚本如下:
from sklearn.ensemble import RandomForestClassifier
from joblib import dump
def load_data(scale = True):
data = pd.read_csv('./data/penguins_size.csv')
data['culmen_length_mm'].fillna((data['culmen_length_mm'].mean()), inplace=True)
data['culmen_depth_mm'].fillna((data['culmen_depth_mm'].mean()), inplace=True)
data['flipper_length_mm'].fillna((data['flipper_length_mm'].mean()), inplace=True)
data['body_mass_g'].fillna((data['body_mass_g'].mean()), inplace=True)
data["species"] = data["species"].astype('category')
data["island"] = data["island"].astype('category')
data["sex"] = data["sex"].astype('category')
data["island_cat"] = data["island"].cat.codes
data["sex_cat"] = data["sex"].cat.codes
X = data.drop(['species', "island", "sex"], axis=1)
if(scale):
scaler = StandardScaler()
X = scaler.fit_transform(X)
y = data['species']
spicies = {'Adelie': 0, 'Chinstrap': 1, 'Gentoo': 2}
y = [spicies[item] for item in y]
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=33)
return X_train, X_test, y_train, y_test
# Train SVM
X_train, X_test, y_train, y_test = load_data(scale=True)
model = SVC(kernel="rbf", gamma=0.1, C=500, verbose=True)
model.fit(X_train, y_train)
dump(model, './models/svm.joblib')
# Train Decision Tree
X_train, X_test, y_train, y_test = load_data(scale=False)
model = DecisionTreeClassifier(max_depth=5)
model.fit(X_train, y_train)
dump(model, './models/decision_tree.joblib')
# Train Random Forest
X_train, X_test, y_train, y_test = load_data(scale=False)
model = RandomForestClassifier(n_estimators=11, max_leaf_nodes=16, n_jobs=-1, verbose=True)
model.fit(X_train, y_train)
dump(model, './models/random_forest.joblib')
# Train Logistic Regression
X_train, X_test, y_train, y_test = load_data(scale=True)
model = LogisticRegression(C=1e20, verbose=True)
model.fit(X_train, y_train)
dump(model, './models/logistic_regression.joblib')
load_data函数加载数据并执行所有必要的预处理,就像 DataLoader 在上一个解决方案中所做的那样。然后,我们使用 joblib 的转储函数训练模型并将其保存在文件中。您可以按如下方式运行此脚本:
python train_models_script.py
4.2 模型加载器
此组件看起来类似于先前实现中的 ModelTrainer,但它更简单。这是它的样子:
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from penguin_sample import PenguinSample
from sklearn.preprocessing import StandardScaler
from joblib import load
import numpy as np
class ModelLoader():
def __init__(self, algoritm):
self.scaledData = True
self._island_map = {'Torgersen': 2, 'Biscoe': 0, 'Dream': 1}
self._sex_map = {'MALE': 2, 'FEMALE': 1}
if(algoritm == 'svm'):
self.model = load('./models/svm.joblib')
if(algoritm == 'logistic regression'):
self.model = load('./models/decision_tree.joblib')
if(algoritm == 'decision tree'):
self.scaledData = False
self.model = load('./models/random_forest.joblib')
if(algoritm == 'random forest'):
self.scaledData = False
self.model = load('./models/logistic_regression.joblib')
self.scaler = StandardScaler()
def prepare_sample(self, raw_sample: PenguinSample):
island = self._island_map[raw_sample.island]
sex = self._sex_map[raw_sample.sex]
sample = [raw_sample.culmenLength, raw_sample.culmenDepth, raw_sample.flipperLength,
raw_sample.bodyMass, island, sex]
sample = np.array([np.asarray(sample)]).reshape(-1, 1)
if(self.scaledData):
self.scaler.fit_transform(sample)
return sample.reshape(1, -1)
def predict(self, data: PenguinSample):
prepared_sample = self.prepare_sample(data)
return self.model.predict(prepared_sample)
同样,根据我们从客户端接收的参数,我们使用 joblib 的 load 函数加载正确的模型。这两种方法用于执行预测。prepare_sample准备一个新样本进行模型处理,而预测方法则在模型中运行样本并检索预测。
4.3 REST API 模块
此模块与之前的实现几乎相同:
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from model_loader import ModelLoader
from train_parameters import TrainParameters
from penguin_sample import PenguinSample
origins = [
"http://localhost:8000",
"http://127.0.0.1:8000/predict",
"http://127.0.0.1:8000/load",
"http://localhost:4200"
]
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.model = ModelLoader('svm')
@app.post("/train")
async def train(params: TrainParameters):
print("Model Loading Started")
app.model = ModelLoader(params.model.lower())
return True
@app.post("/predict")
async def predict(data:PenguinSample):
print("Predicting")
spicies_map = {0: 'Adelie', 1: 'Chinstrap', 2: 'Gentoo'}
species = app.model.predict(data)
return spicies_map[species[0]]
主要区别在于使用了 ModelLoader 类,并且没有对模型进行任何训练。
要运行服务器端,您需要转到train_solutionserver文件夹并使用以下命令:
4.4 一起运行
要运行服务器端,您需要转到load_solutionserver文件夹并使用以下命令:
uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
在另一个终端中,您需要转到load_solutionclient文件夹并运行:
npm install
ng serve
√ Browser application bundle generation complete.
Initial Chunk Files | Names | Size
vendor.js | vendor | 3.02 MB
polyfills.js | polyfills | 481.27 kB
styles.css, styles.js | styles | 340.83 kB
main.js | main | 93.72 kB
runtime.js | runtime | 6.15 kB
| Initial Total | 3.92 MB
Build at: 2020-11-22T10:33:00.423Z - Hash: bf345d81dfd56983facb - Time: 10867ms
** Angular Live Development Server is listening on localhost:4200, open your browser on http://localhost:4200/ **
√ Compiled successfully.
完成此操作后,您可以转到localhost:4200并测试应用程序:
结论
在本文中,我们能够看到如何使用 FastAPI 和一些 JavaScript 框架(在此特定情况下为 Angular)部署机器学习算法。我们看到了什么是REST API以及如何使用FastAPI构建它。最后,我们在用户界面的帮助下利用了这个API,完成了整个解决方案。如果你想更进一步,你可能想把它放到Docker实例中,并使用Kube.NETes。
感谢您的阅读!
原文标题:Deploying machine Learning Models with FastAPI and Angular
作者:AI, Angular, Machine Learning, Python
原文:
https://rubikscode.net/2020/11/23/deploying-machine-learning-models-with-fastapi-and-angular/
编译:LCR