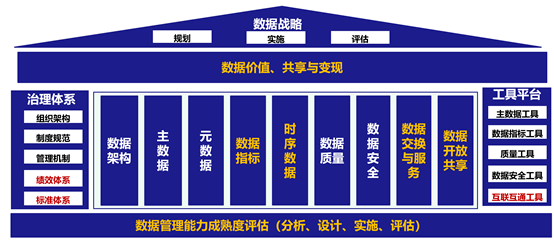
随着大数据分析市场快速渗透到各行各业,哪些大数据技术是刚需?哪些技术有极大的潜在价值?根据弗雷斯特研究公司发布的指数,这里给出最热的十个大数据技术。
预测分析:预测分析是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。可为预测、优化、预报和模拟等许多其他用途而部署。随着现在硬件和软件解决方案的成熟,许多公司利用大数据技术来收集海量数据、训练模型、优化模型,并发布预测模型来提高业务水平或者避免风险;当前最流行的预测分析工具当属IBM公司的SPSS,SPSS这个软件大家都已经很熟悉了,它集数据录入、整理、分析功能于一身。用户可以根据实际需要和计算机的功能选择模块,SPSS的分析结果清晰、直观、易学易用,而且可以直接读取Excel及DBF数据文件,现已推广到多种各种操作系统的计算机上。
NoSQL数据库:非关系型数据库包括Key-value型(redis)数据库、文档型(MonogoDB)数据库、图型(Neo4j)数据库;虽然NoSQL流行语火起来才短短一年的时间,但是不可否认,现在已经开始了第二代运动。尽管早期的堆栈代码只能算是一种实验,然而现在的系统已经更加的成熟、稳定。
搜索和认知商业:当今时代大数据与分析已经发展到一个新的高度,那就是认知时代,认知时代不再是简单的数据分析与展示,它更多的是上升到一个利用数据来支撑人机交互的一种模式,例如前段时间的围棋大战,就是一个很好的应用、现已经逐步推广到机器人的应用上面,也就是下一个经济爆发点——人工智能,互联网人都比较熟悉国内的BAT,以及国外的Apple、google、facebook、IBM、微软、亚马逊等等;可以大致看一下他们的商业布局,未来全是往人工智能方向发展,当然目前在认知商业这一块IBM当属领头羊,特别是当前主推的watson这个产品,以及取得了非常棒的效果。
流式分析:目前流式计算是业界研究的一个热点,最近Twitter、LinkedIn等公司相继开源了流式计算系统Storm、Kafka等,加上Yahoo!之前开源的S4,流式计算研究在互联网领域持续升温,流式分析可以对多个高吞吐量的数据源进行实时的清洗、聚合和分析;对存在于社交网站、博客、电子邮件、视频、新闻、电话记录、传输数据、电子感应器之中的数字格式的信息流进行快速处理并反馈的需求。目前大数据流分析平台有很多、如开源的spark,以及ibm的 streams 。
内存数据结构:通过动态随机内存访问(DRAM)、Flash和SSD等分布式存储系统提供海量数据的低延时访问和处理;
分布式存储系统:分布式存储是指存储节点大于一个、数据保存多副本以及高性能的计算网络;利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。当前开源的HDFS还是非常不错,有需要的朋友可以深入了解一下。
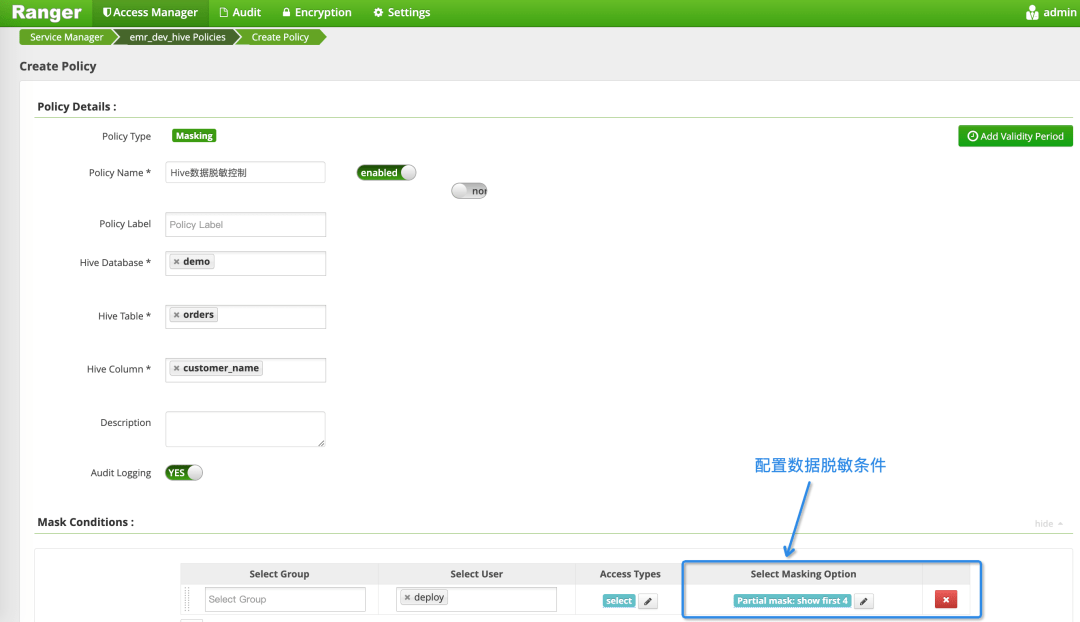
数据可视化:数据可视化技术是指对各类型数据源(包括hadoop上的海量数据以及实时和接近实时的分布式数据)进行显示;当前国内外数据分析展示的产品很多,如果是企业单位以及政府单位建议使用 cognos ,安全、稳定、功能强大、支持大数据、非常不错的选择。
数据整合:通过亚马逊弹性MR(EMR)、Hive、Pig、Spark、MapReduce、Couchbase、Hadoop和MongoDB等软件进行业务数据整合;
数据预处理:数据整合是指对数据源进行清洗、裁剪,并共享多样化数据来加快数据分析;
数据校验:对分布式存储系统和数据库上的海量、高频率数据集进行数据校验,去除非法数据,补全缺失。
数据整合、处理、校验在目前已经统称为 ETL ,ETL过程可以把结构化数据以及非结构化数据进行清洗、抽取、转换成你需要的数据、同时还可以保障数据的安全性以及完整性、关于ETL的产品推荐使用 datastage就行、对于任何数据源都可以完美处理。